大模型知识点
-1、😭线性代数和图论回顾
伴随矩阵:$AA^=A^A= A E$ 矩阵的逆:$A^{-1}=\frac{A^*}{ A }$
图论
- 图的构建有两种方法:(1)Adjacency matrix (2)adjacency lists
- adjacency lists算法(1)DFS(低效,从src到dst的所有路径数量) (2)BFS(仅能寻找最短路径)
- Data structure for representing a graph: combination of linked list and hash table:这个文章介绍一种全新的、用来表示图的数据结构,它试图结合“邻接矩阵”和“邻接表”的优点
- tree的插入和删除很昂贵,所以需要用红黑树,AVL树查询更高效,红黑树插入和删除更高效,看了下红黑树会改变tree的顺序,也就是会改变draft产生的语义顺序,不太适用
hash
构建hash table
- direct-address:H(key)=a*key+b 适合连续
- 除留余数:H(key)=key % p (p一般取小于等于表长的最大质数,冲突更少)
hash冲突解决方法
- 开放定址:找一个新空闲位置存放 (线性探测法:依次探测下一个位置,无论是存放还是检索都是按顺序)
- 平方探测法(和开放定址差不太多):冲突时按照 $+1^2,-1^2,+2^2,-2^2, +3^2,-3^2 …$的顺序进行探测(表尾之后是表首)。优点:可以缓解堆积问题。表长=某个4k+3的质数(k为正整数)那么一定可以探测到所有位置
- 拉链法:
0.不断更新论文or新的研究
- 1)DualPipe & Cross-Node All-to-All Communication讲解了两个方向的前向和反向传播来重叠传播时间,代价是复制了一份网络参数(貌似有新的可以不用复制了)—- 基于 1F1B 的 MoE A2A 通信计算 Overlap
主要还是训练中的F和B的问题,不看,不碰训练~~~
0.1 LLM推理加速
COLING 2025 Tutorial: Speculative Decoding for Efficient LLM Inference
- 这个tutorial很好的讲解了从
Blockwise Decoding、Speculative Decoding、Speculative Sample,并且展示了Spec-Bench: Benchmark for Speculative Decoding- 介绍了
Independent Drafting中从Non-Autoregressive LM到Small LMs到Sequence-Level KD(蒸馏)到Context Retrieval到copy输入,Independent Drafting需要保证draft和target有共同的tokenizer- 介绍了
Self-Drafting从Extra Head(like medusa)到layer Skipping到Mask-Predict- 第三部分开始从
medusa到EAGLE过度到语料库COPY is All Your Need- Context as Drafts中
SAM-Decoding可以和EAGLE2结合,SAM-Decoding感觉是一个大融合,用了多种drafting method,EAGLE2利用动态的draft tree来减少不必要的分支关注,Verification for High-quality DraftsEAGLE2的核心是置信度越高,被accept的概率越高,通过计算每个分支的置信度,对低置信度的进行过滤- 后续讨论到严格的verify是否太死板了,或许可以只让他符合human的judgement就很好了,所以类似于medusa,有了judge head(我个人觉得比如我们运用到一些语音视频或者推荐里面,tolerance比较高?),
Faster Speculative Sampling Requires Going Beyond Model Alignment实验得到即使很强的draft也有上限

相关文章研讨SpecInfer,Medusa,Kangaroo等
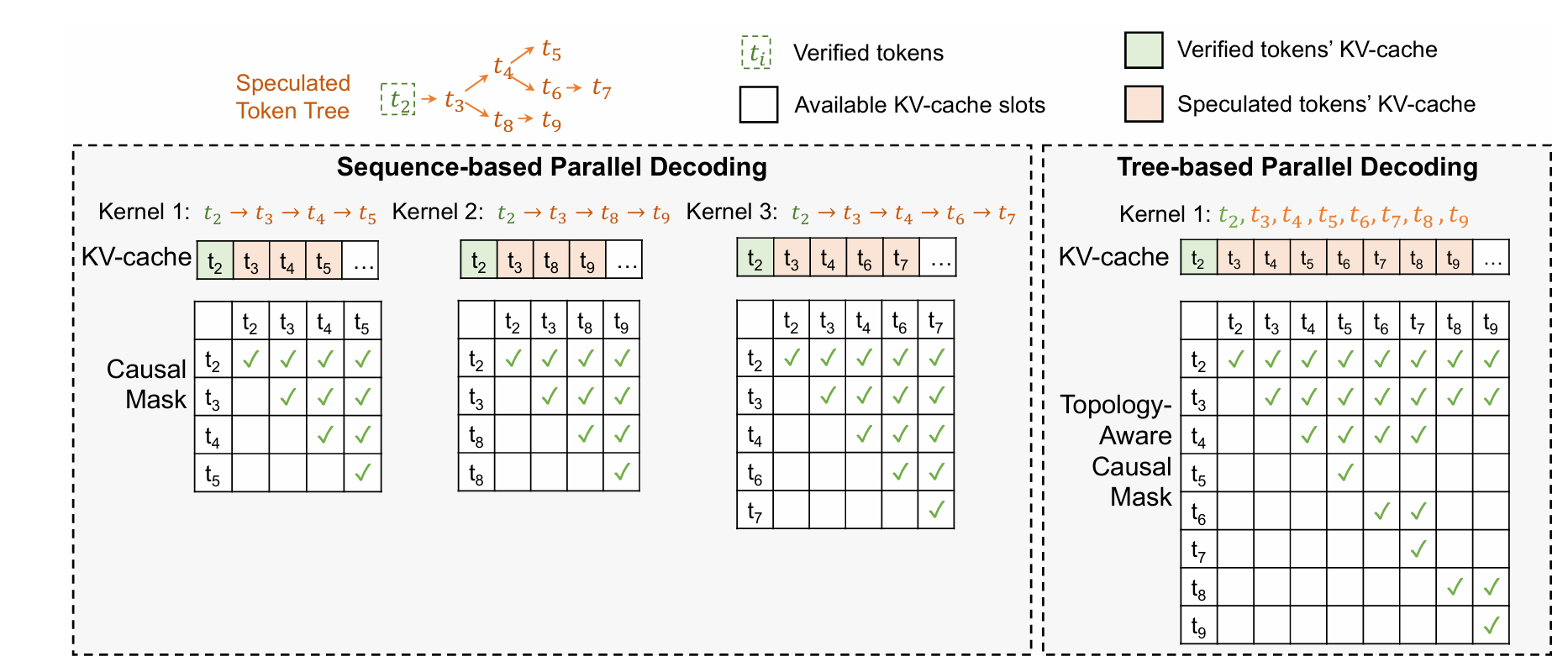
LLM推理加速的方法:- 生成候选token,要么小模型串行快速生成多个token;要么并行输出序列后n个token。
- 而check部分,对并行解码和投机采样直接一次并行(prefill)推理验证;而对于medusa的token是tree形状的,以特殊的mask进行并行推理
0.1.1 投机解码
- 投机解码原理:预测执行的加速之道讲解了(大算力小带宽的prefill的check模型)和(大带宽小算力的draft的decoder模型),大模型遍历一次时间为$T_L$,小模型遍历一次时间是$T_S$,那么平均接受率即加速比例为$\alpha =\frac{T_S}{T_L}$。加速的要点是draft足够快&质量高(小模型生成的是类似于空格这样非关键的token) 这个讲解的更好——投机采样原理和实现方法
- 缺点1.寻找理想的Draft Model很难,使用投机解码进行采样时,需要使用一种重要性采样方案。这会带来额外的生成开销,尤其是在较高的采样温度下。
- 缺点2.在一个系统中托管两个不同的模型会引入多层的复杂性,不论是计算还是操作,尤其是在分布式环境中。
- 缺点3.这些复杂性和权衡限制了投机解码的广泛采用。因此,虽然投机解码前景广阔,但并未被广泛采用。
0.1.2 Specinfer树状
- Specinfer利用注意力的mask机制,用多个小模型生成树状结果,因为候选的token变多了,所以效果理论上会优于直接投机采样。根据需要适配了树形并行解码
0.1.3 Medusa美杜莎
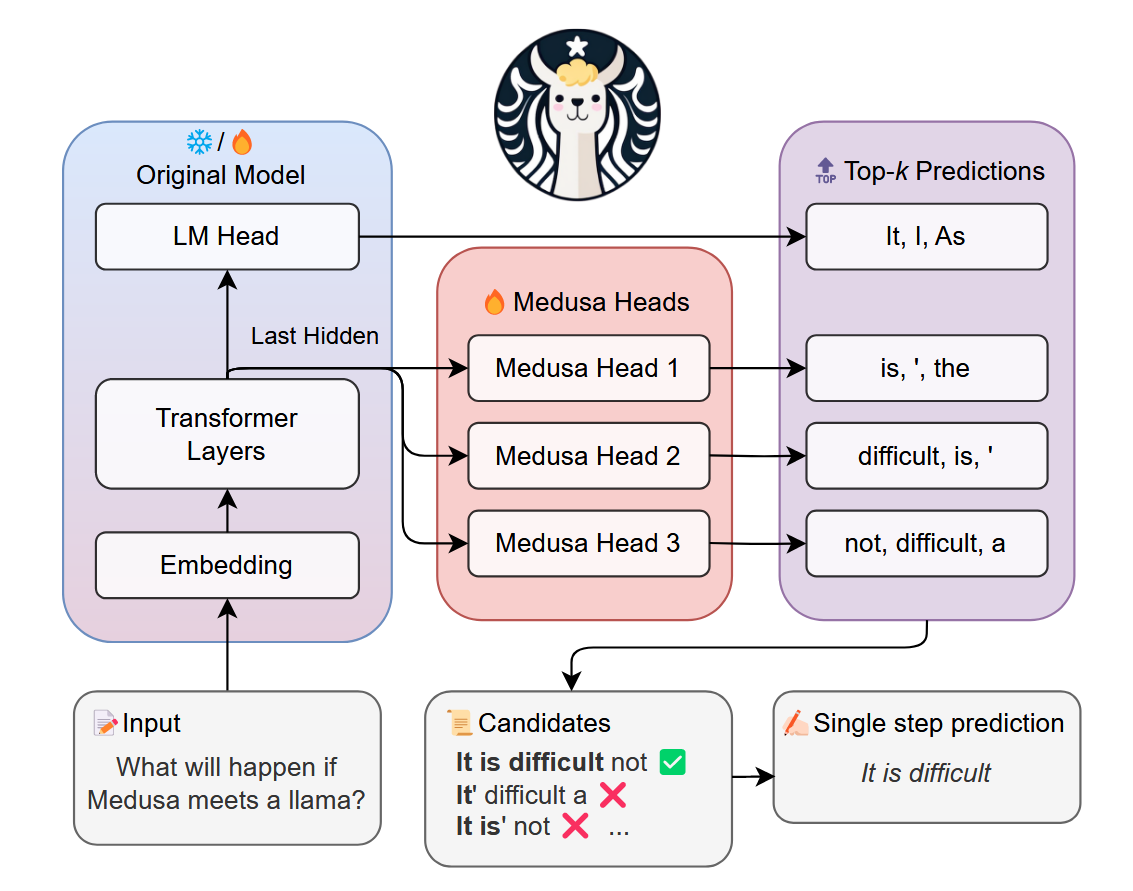
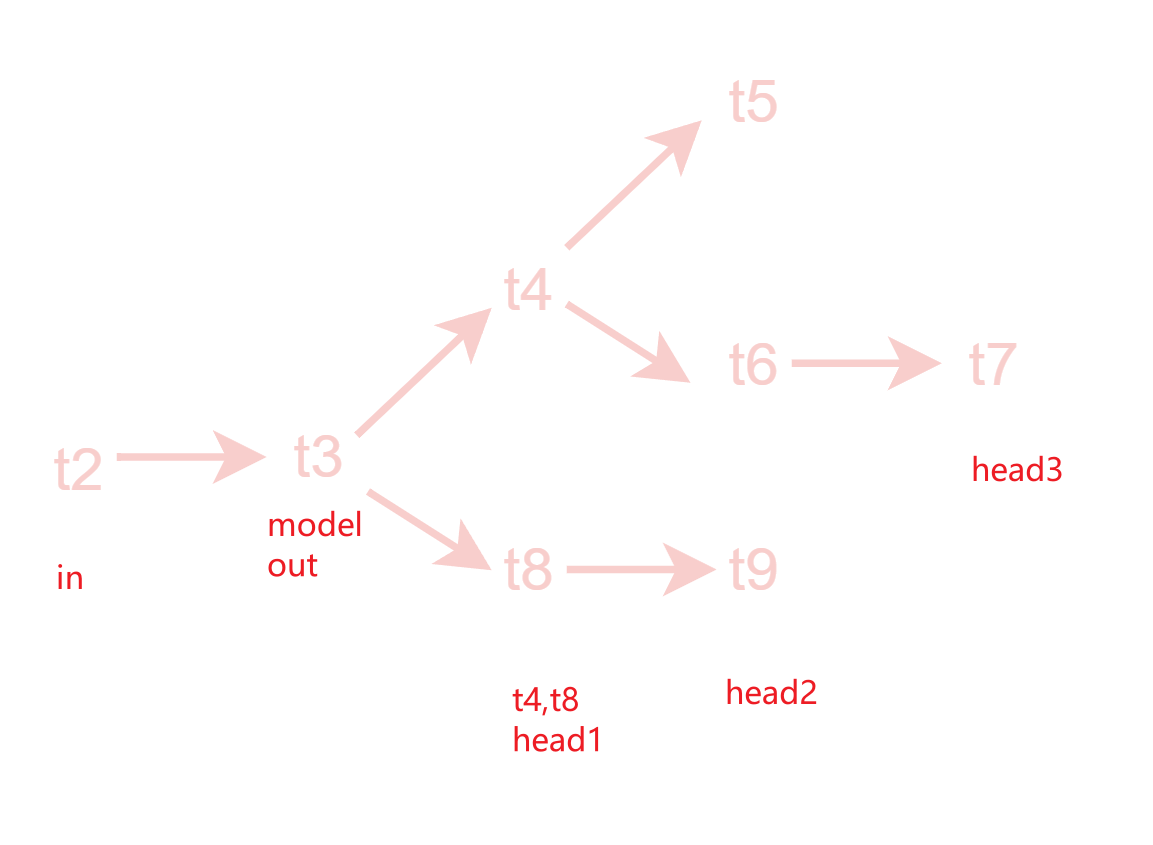
- Medusa美杜莎结合了并行解码和Specinfer,并行解码部分,每个head负责树的不同层次的生成,解码多次
- 这里的美杜莎head对应新微调出来的lm_head,
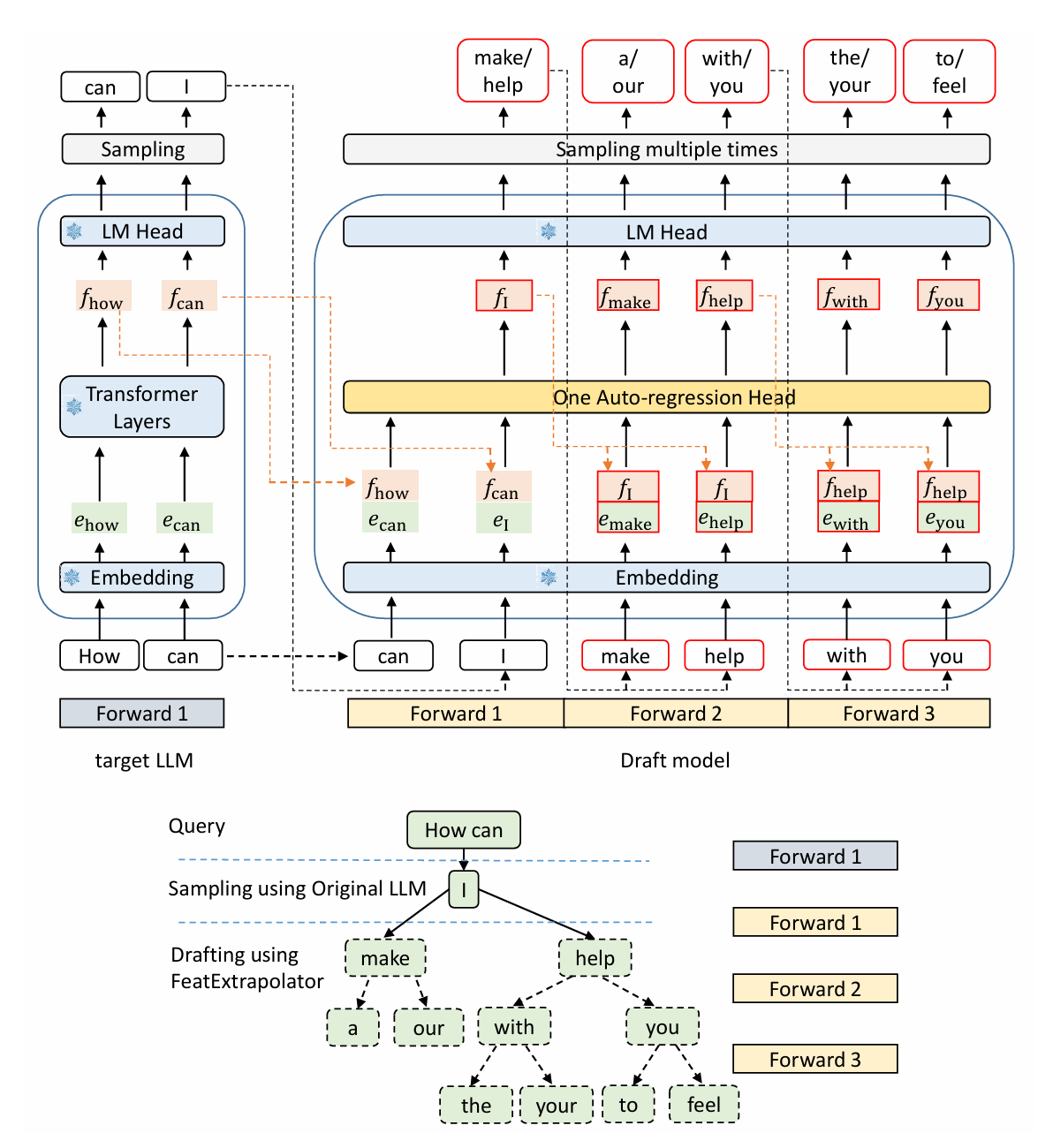
0.1.4 EAGLE
这个很有意思 大模型来辅助小模型—有点抽象哈哈,把大模型的f拼接到小模型的embed之后,变成2*hid_dimm
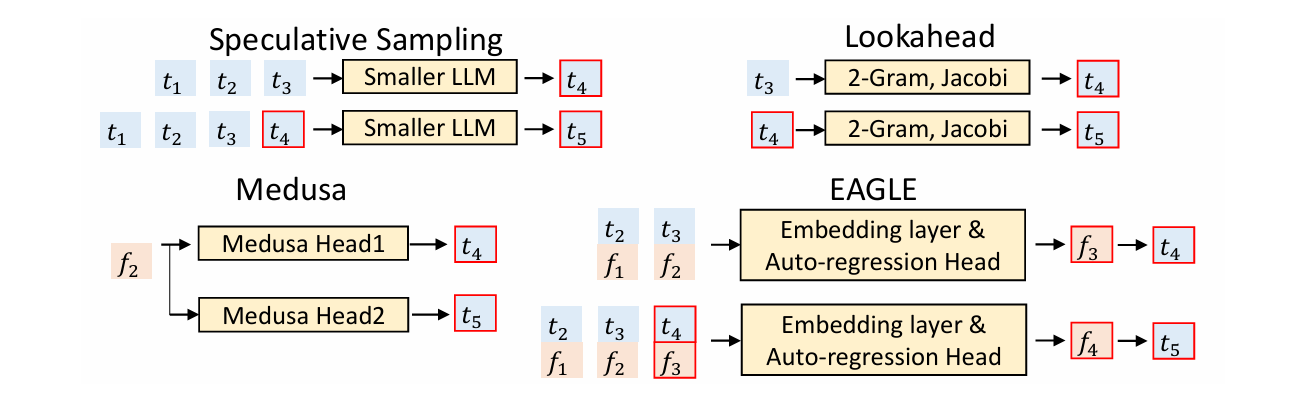
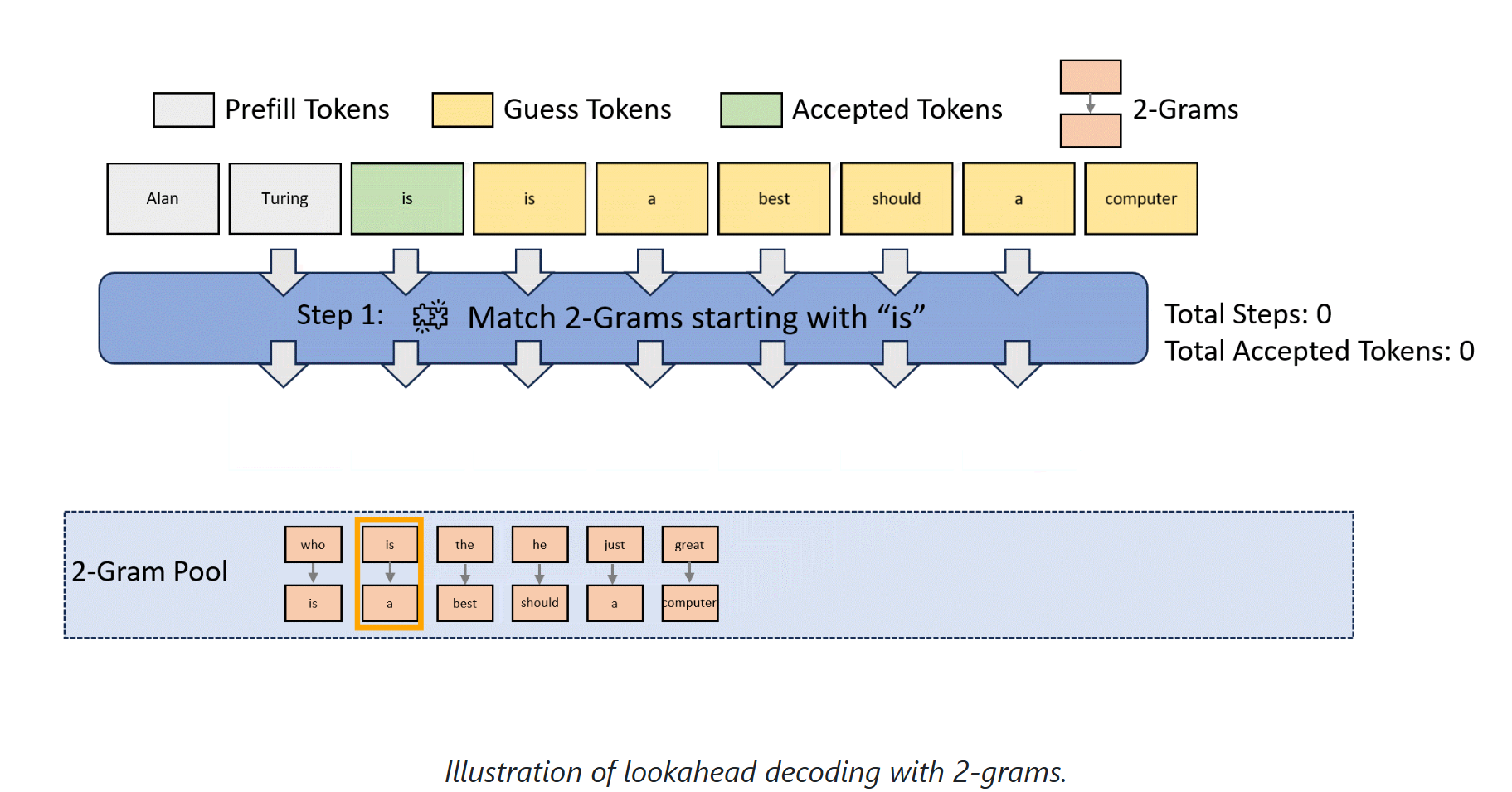
0.1.5 LookaheadDecoding
并行decode-> verify-> 不match之后更新Pool-> search Gram Pool & replace
下面是lookahead的思想,通过N-Gram:回顾过去的雅可比迭代轨迹的步数,,这个长度决定了在第二张图中,注意力的计算长度和输入的拼接长度
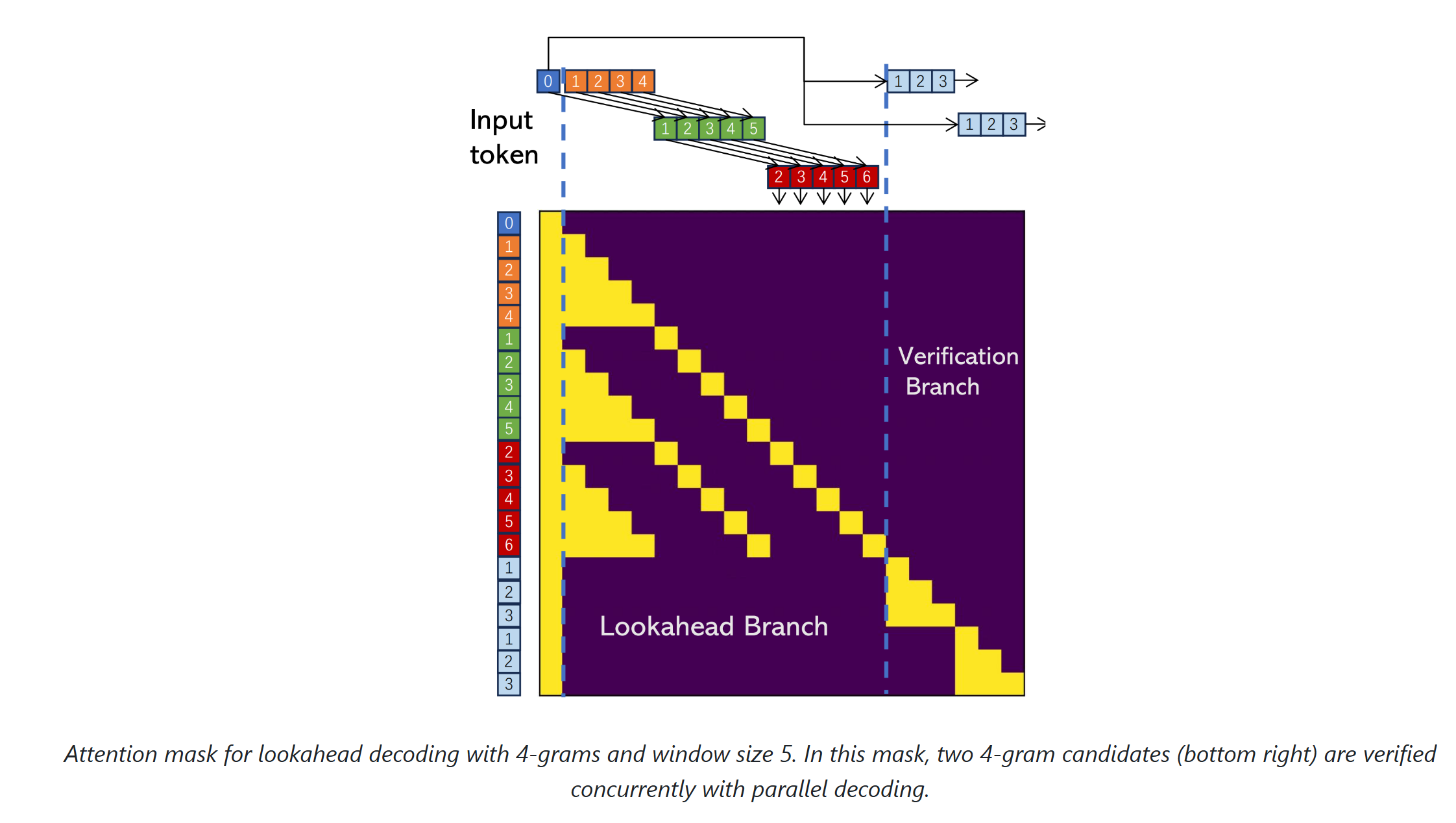
In the verification branch, we identify n-grams whose first token matches the last input token.
回顾推测式解码中的验证过程——将草稿标记输入大语言模型以获取每个草稿标记对应的输出,随后逐步检查目标大语言模型生成的末位标记输出是否严格匹配该草稿标记本身。
前瞻解码的验证分支虽需并行验证多个n元语法候选,但其流程与此类似。首先从n元语法池中筛选”有潜力”的n元语法(判断条件为该n元语法首标记需与当前序列末位标记完全匹配),随后参照推测式解码的模式,并行验证所有这些n元语法
token的更新规则为:用绿色的2345替代橙色,红色替代绿色以及新生成的token替代红色
N-Gram的组成规则为:图中的箭头橙色1->绿色2->红色3->新生成的4
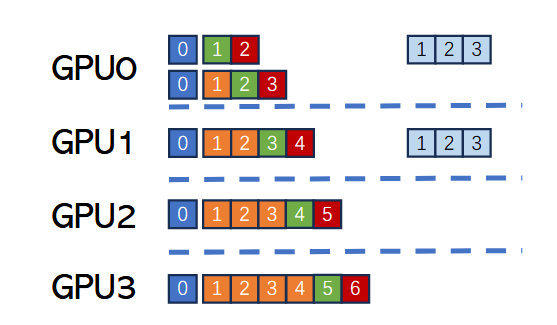
如何分配到GPU进行并行计算:此工作负载分配会导致橙色令牌0、1、2、3及输入令牌0被冗余存储与计算,但其核心优势在于可显著减少整个前向传播过程的通信开销。我们仅需在前向传播结束后同步各设备生成的令牌。
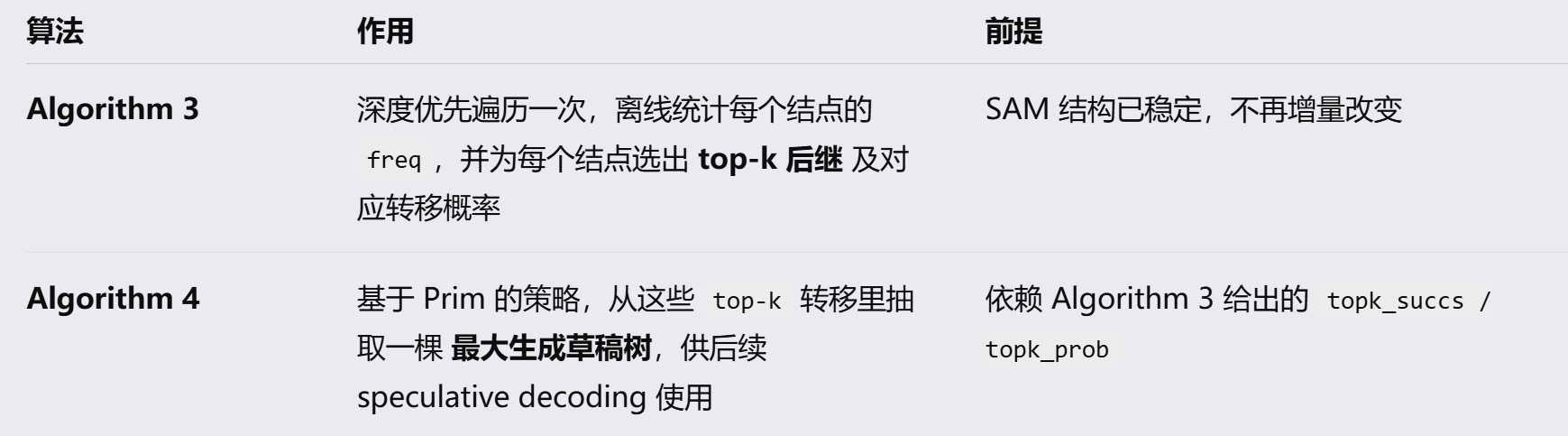
0.1.6 SAM Decoding中构建corpus的算法理解
列举了一个sam的Suffix Automaton构建 中命中clone的推导(不懂这个算法为什么这么设计 但是你别管,follow别人就行),算法1讲解了Suffix Automaton的状态转移算法,论文里实际上只有一套 Suffix Automaton(SAM)的增量构建算法2,也就是说离线构建的静态也是这套,只是在推理的时候不会再expand了。




静态的corpus通过使用特殊符号(如句末符EOS)将语料库中的多个字符串进行串联。静态的构建基于Top-K的Prim算法,静态 SAM不重新发明新建法,而是在 Algorithm 2 完成后再离线跑 Algorithm 3/4 来附加统计信息。

0.2.1 Prefix Caching 原理详解
我们的corpus本质就是在维护上下文,所以也可以维护上下文多轮请求的kvcache存储,这样可以减少prefill的时间
github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/core/kv_cache_utils.py#L187-L188 这里可以看看链表的一些操作达到O(1)复杂度的添加删除移动
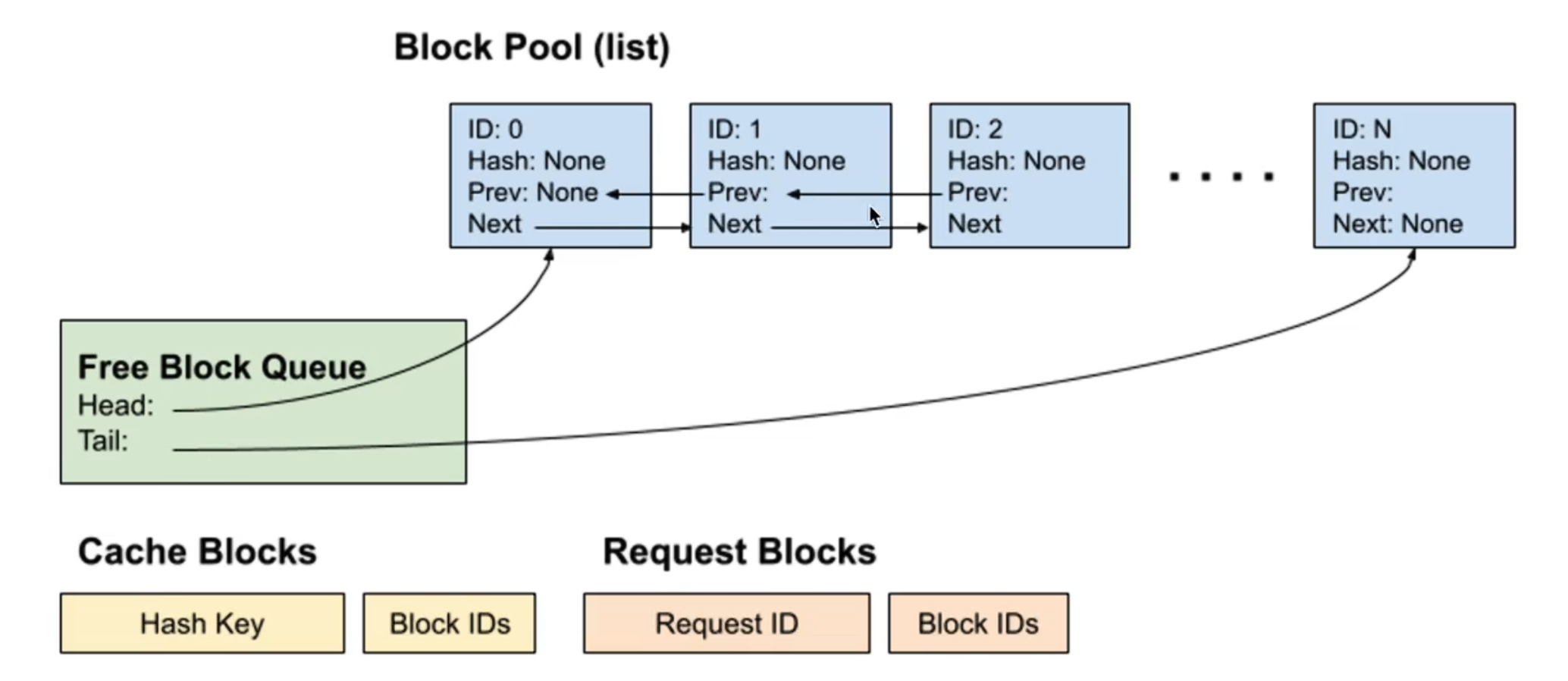
这就是corpus,分别实现kvcache的词典和request(input)的词典,参照这个视频来观看这个数据结构的构建方法,逆序添加blockid,不立即驱逐block缓存
Prefix Cache Aware Routing利用Gateway API Inference Extension维护一个全局prefix cache index来决定将请求打向哪一台设备,每台设备都有自己的prefix cache
0.2.2 vLLM PagedAttention
一、大模型的基础知识
- 最初的输入(token 序列)是
input_ids,形状通常为 [batch_size, seq_len],经过Embedding层后,通常变为 [batch_size, seq_len, hidden_dim]- 每个元素是一个词或子词的 ID(介于
[0, vocab_size))
- 每个元素是一个词或子词的 ID(介于
Q的形状为 [batch_size, seq_len, hidden_dim]- 大词表模型最后有个线性层(
W^out大小[hidden_dim, vocab_size]),把每个时间步的 hidden state 投影到词表维度,最后flatten成[batch_size∗seqlen,vocab_size]。分类网络最后一层一般会选用softmax 和 cross entropy(s-p) 来计算损失
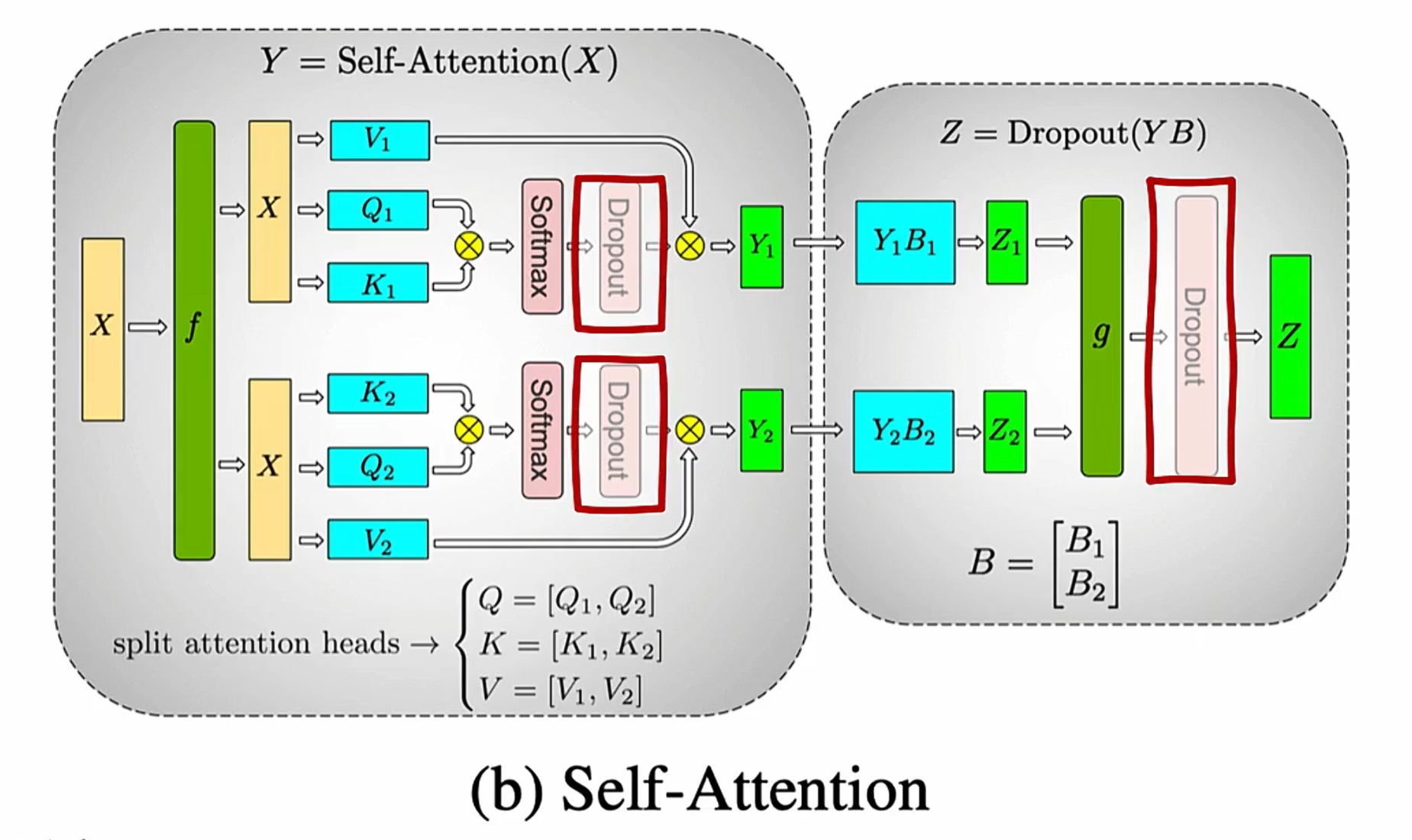
1.1 dropout
- Dropout在前向传播时,Dropout 会以某个概率 p 对输入随机置零,减少过拟合
- 缩放(Scaling)将未被归零的部分除以 (1−p)
- 在测试/推理阶段,神经网络通常关掉 Dropout(或改用推断模式的缩放),以保证所有神经元全部激活。
1.2 梯度导致的数据维度变化
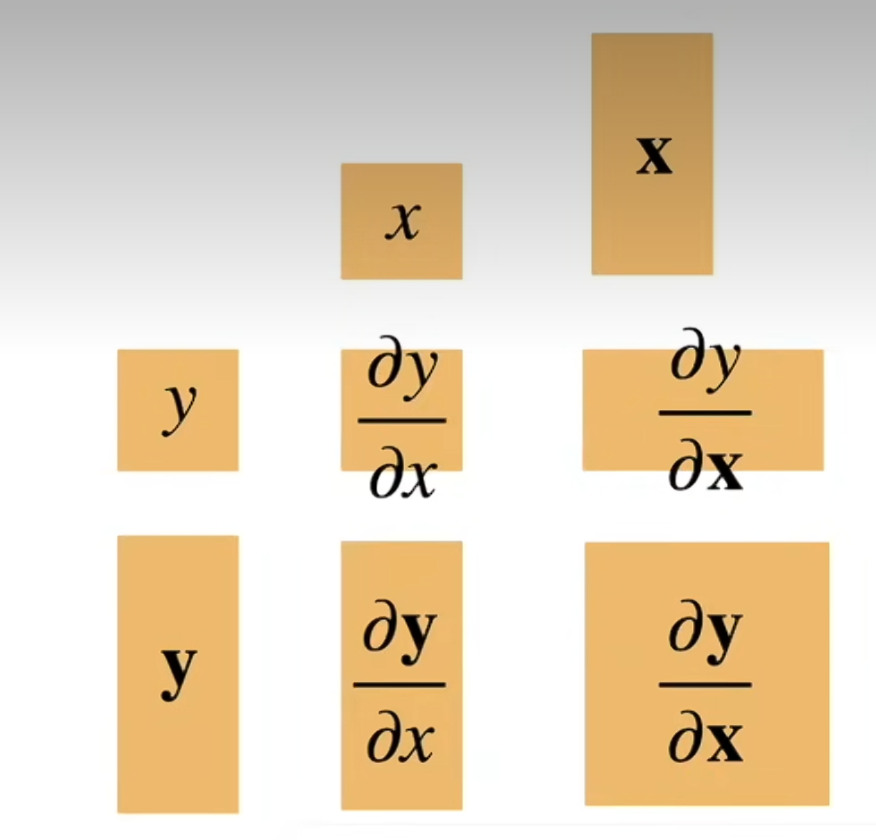

y是标量,x是向量
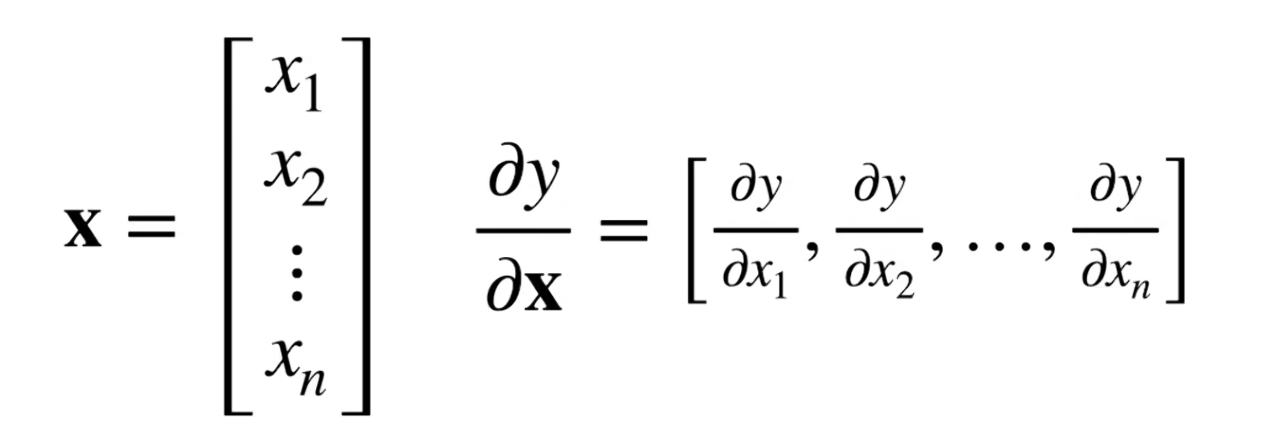
y是向量,x是标量
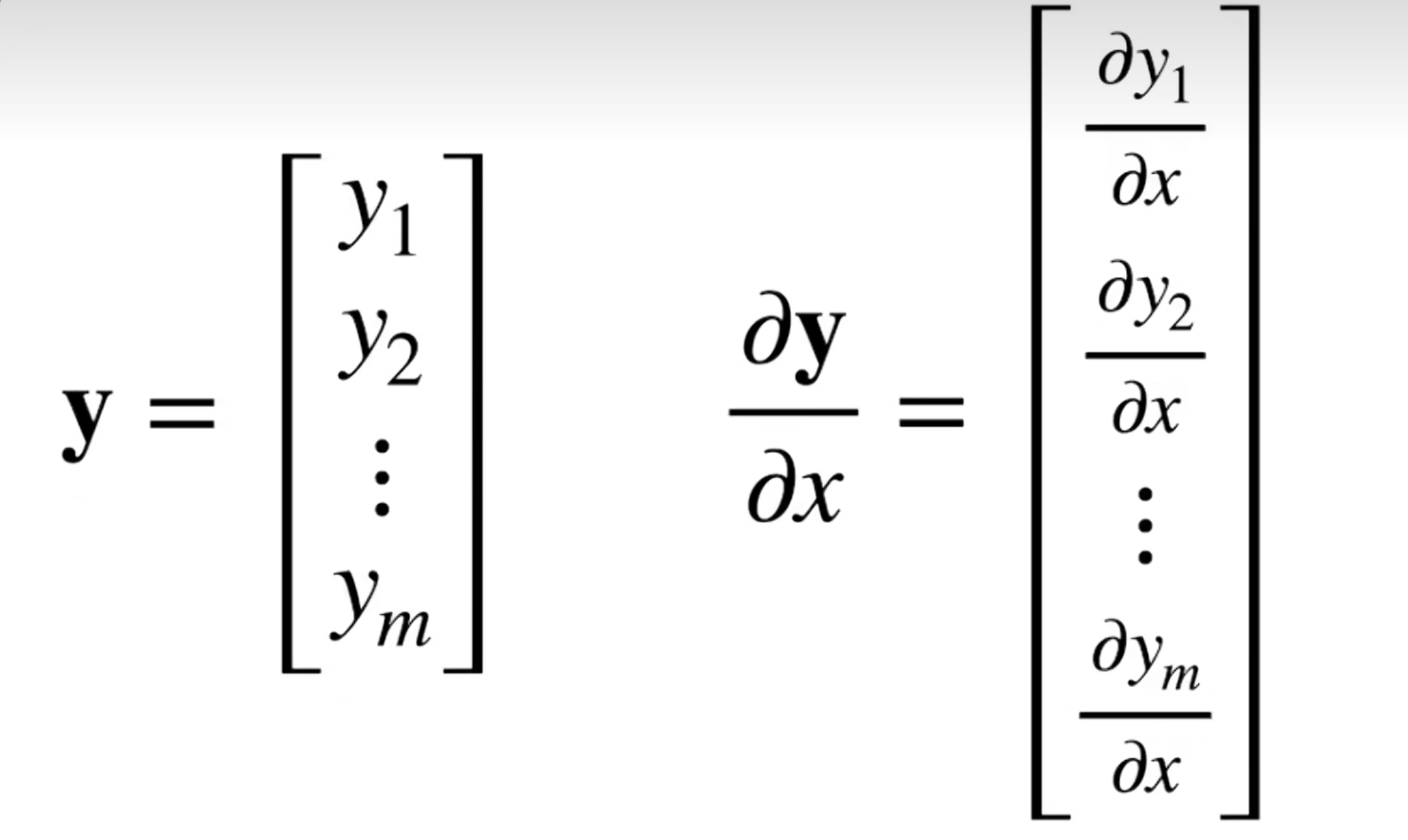
内积求导(注意:向量对向量求导结果是一个矩阵)
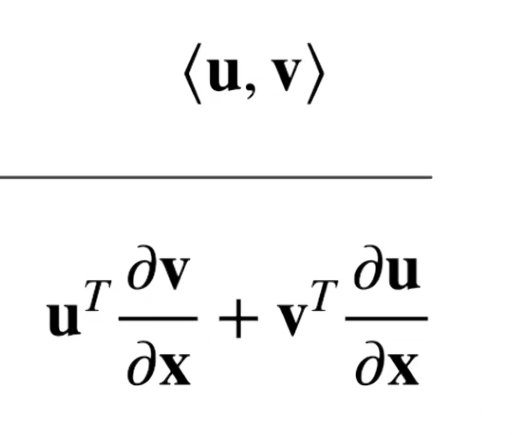

样例(加粗代表向量)
$y=x^TA$ ,求导为$A^T$
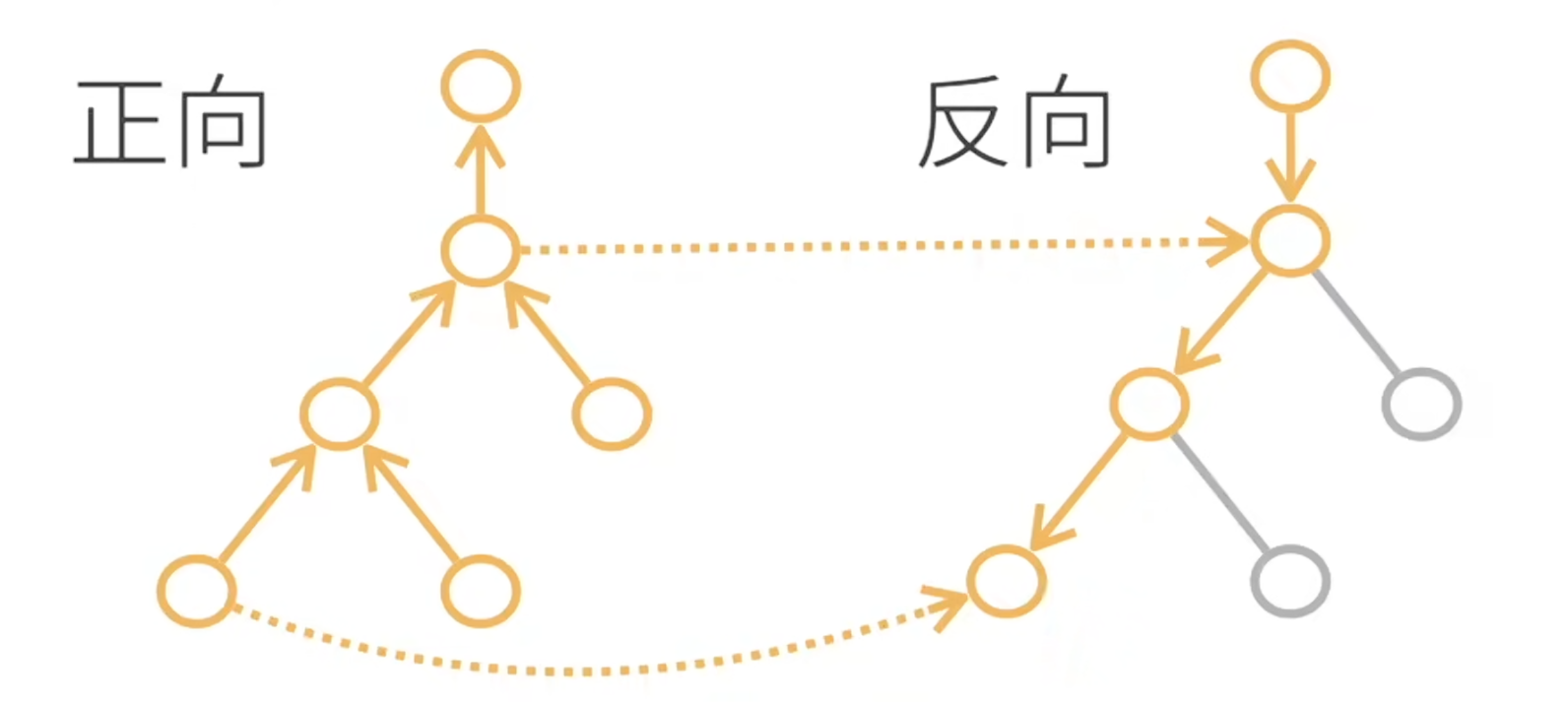
正向传播和反向传播数据依赖:因为需要存储正向的所有中间结果
1.3 回归和分类的区别
回归是一个单连续值的输出,和真实值的区别作为loss
分类是多个输出,代表预测为第i类的置信度
1.4 RoPE && RMSNorm
外积:向量 a⊗b=$a*b^T$= \(\left[ \begin{matrix} a_1xb_1 & a_1xb_2 \\a_2xb_1 & a_2xb_2 \end{matrix} \right] \tag{1}\)
内积:结果为标量,$a_1$$b_1$+$a_2$$b_2$
在复平面上,$z_1$$z_2$等效于模长r1r2,角度为$o_1$+$o_2$
1.4.1 RoPE
cis编码: cis(x)=cos(x)+i*sin(x)
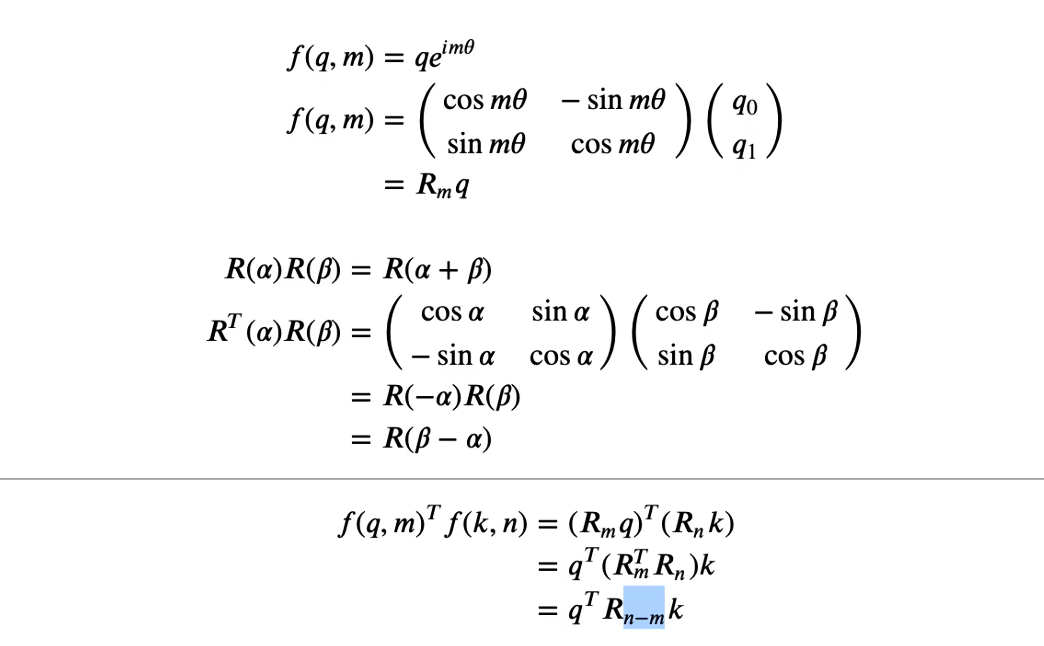
表示输入向量的第i个位置的编码向量,将向量xi拆分为一系列长度为2的子向量$( x_{i,2k},x_{i,2k+1} )$
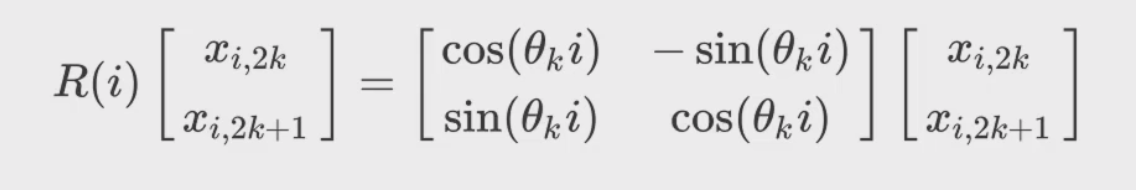
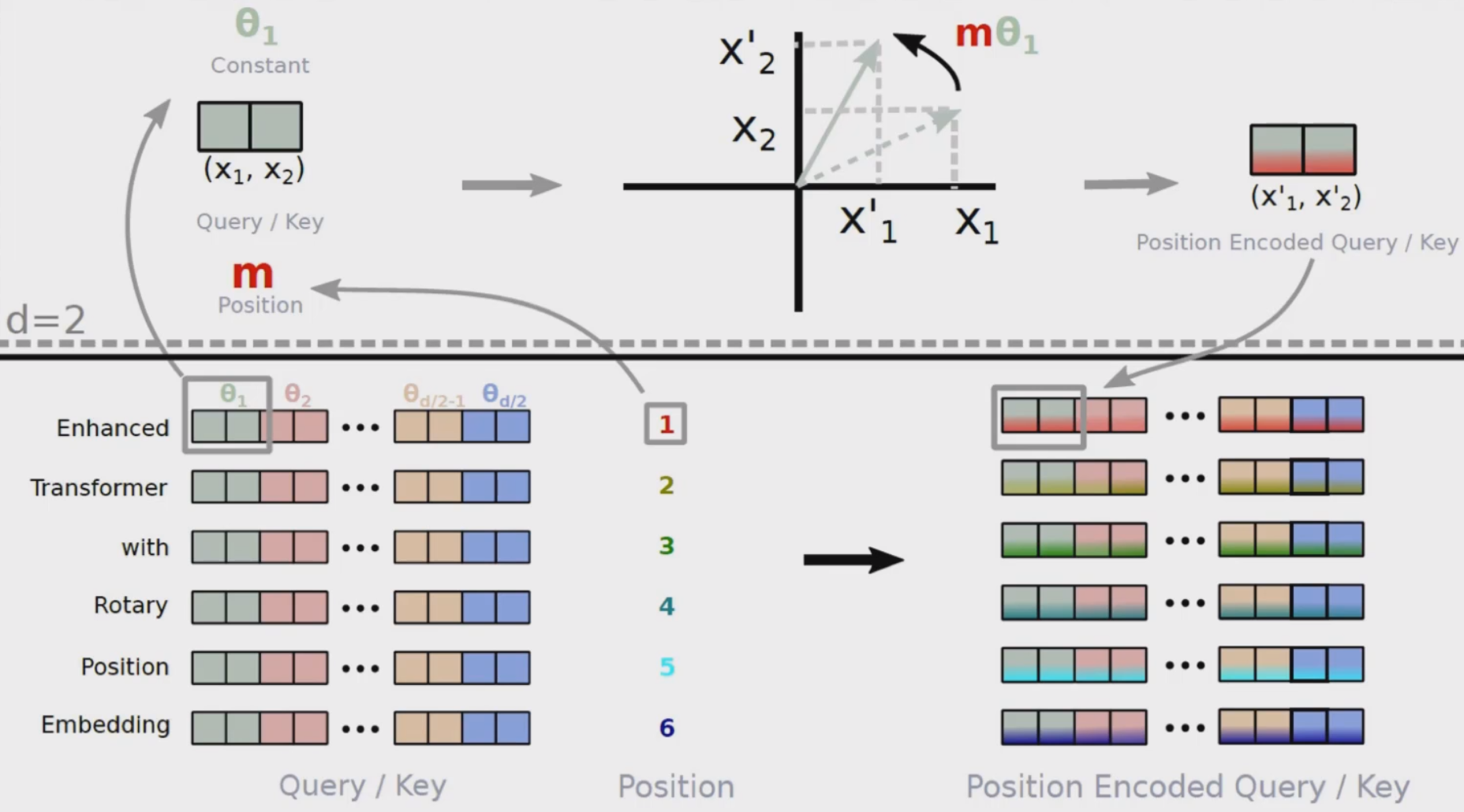
位置编码和相对位置有关,绝对位置不是那么重要 。RoPE位置编码的要点:
- 先做多Head的投影,再加上旋转位置编码
- 用的仍然是正弦和余弦函数操作,当两个向量计算内积时,直接转换成了包含相对位置信息。
- 只对Q,K做旋转位置编码,V不变
- d为embedding的维度,m为绝对位置
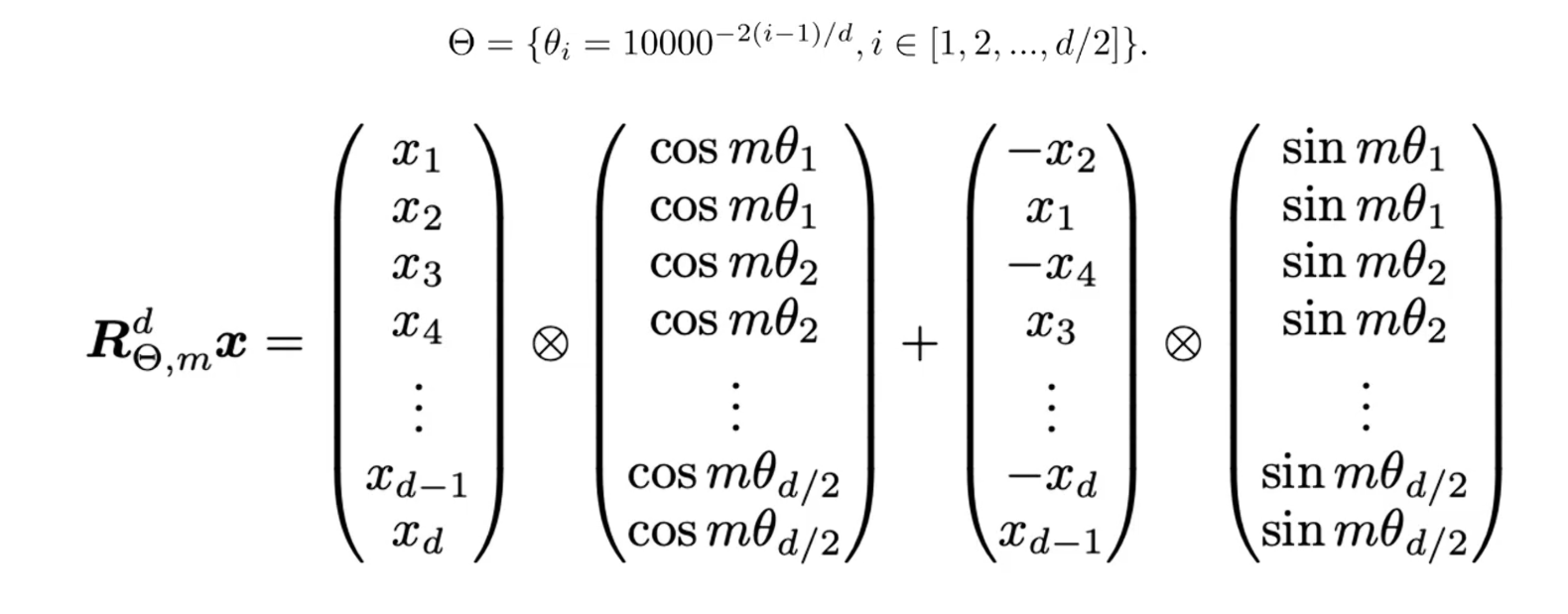
llama的rope不太一样,所以这个怎么做rope无所谓

1.4.2 RMSNorm
Norm是为了防止在训练中,后面层刚学好,前面输入稍微一变,又要重新学!导致网络收敛变慢。 Norm使得数据均值为0,方差为1。
BatchNorm是把同一个batch不同实例中相同位置的数据一起计算均值和方差来做归一化,在图像任务中比较常用。
LayerNorm在文本任务中常用,只关注输入文本自身进行计算。(因为对于一个输入,为什么要和语义不相关的句子去一起计算均值和方差呢?) RMSNorm相比LayerNorm减少计算开销(不需要均值),计算量少了,效果基本不变
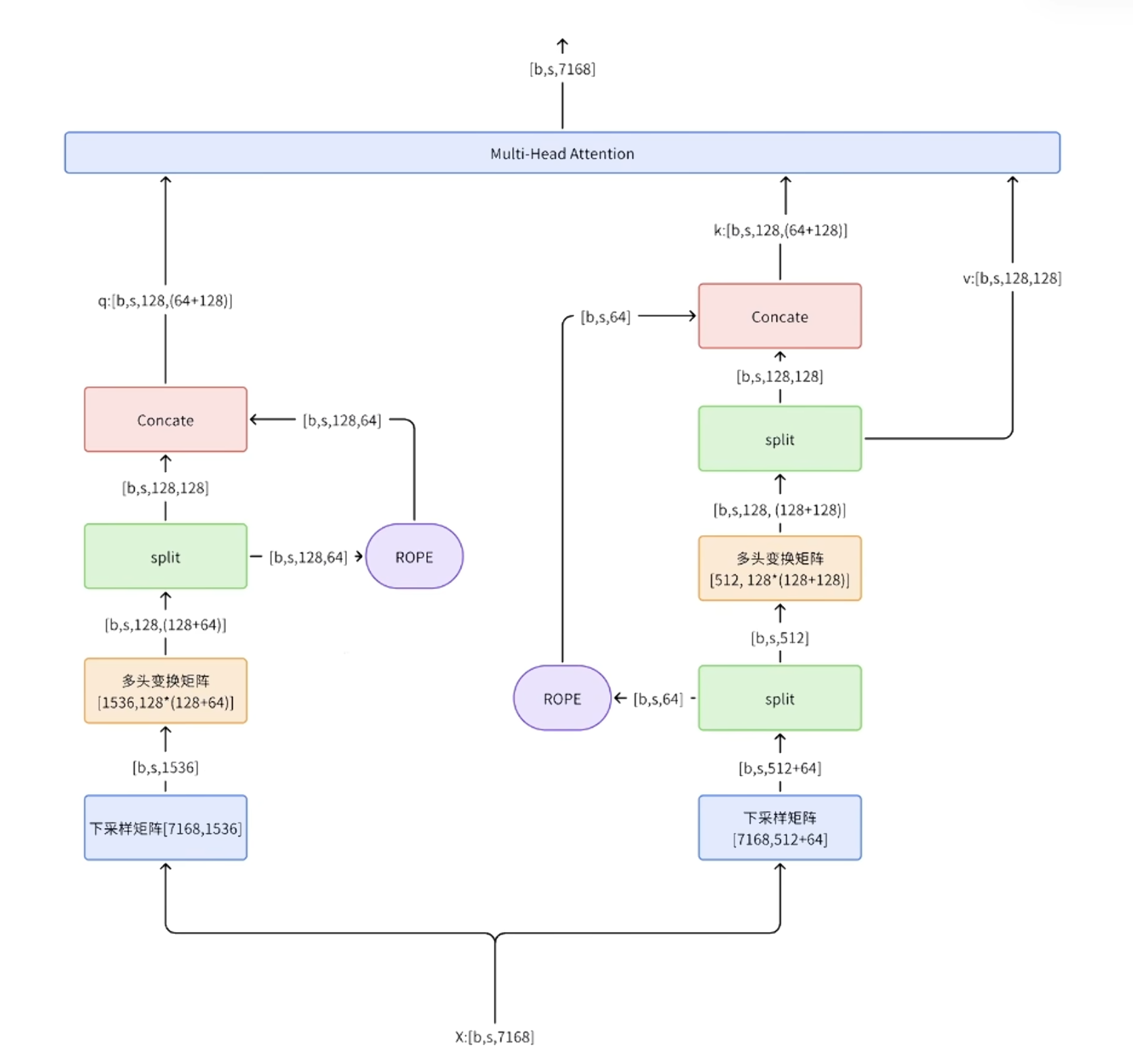
1.5 MLA(Multi-head Latent Attention)
[1.1有MHA的计算形式],对于每个token,KVCache的缓存占用为2$n_h * d_h * l(n_h为头的数量,d_h为每个头的维度),l为layer的数量$
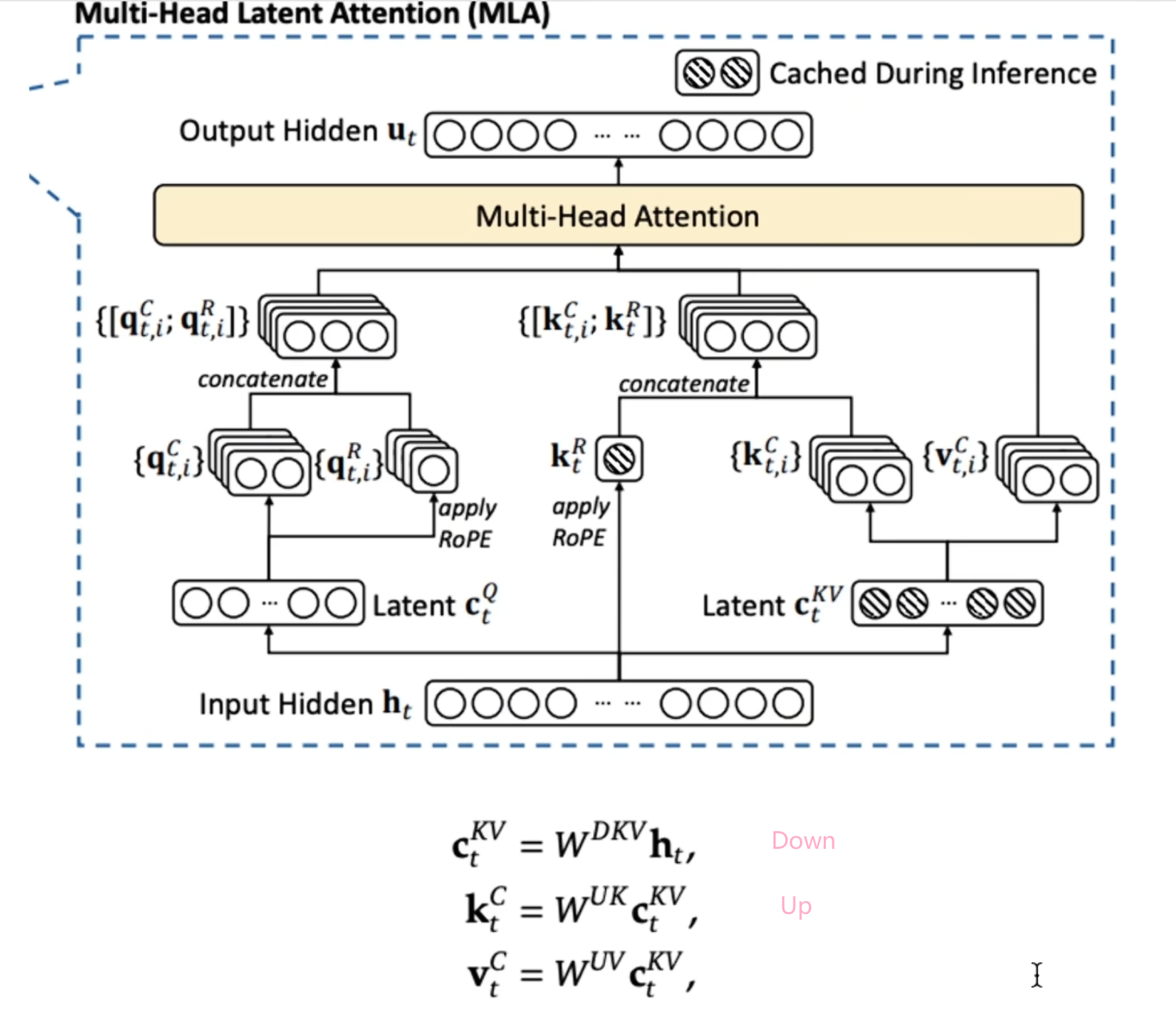
实际上不存在两个上采样矩阵,可以直接从$c_t^{KV}$开始计算,WUK可以融入WQ,WUV可以融入WO,例如在算attention的时候,$q^Tk=h_q(W_1W_2)h_k$,训练的时候会直接得到括号里的内容
这种计算方式,对RoPE旋转位置编码是有影响的。也就是不能直接在压缩后的向量上应用RoPE(只对QK进行变换),那么可不可以在解压后的向量上应用RoPE呢?可以,但是影响效率,因为前面已经说过不显示计算解压后的向量,而是直接应用压缩后的向量。如何解决呢?再造一个向量,单独应用RoPE。
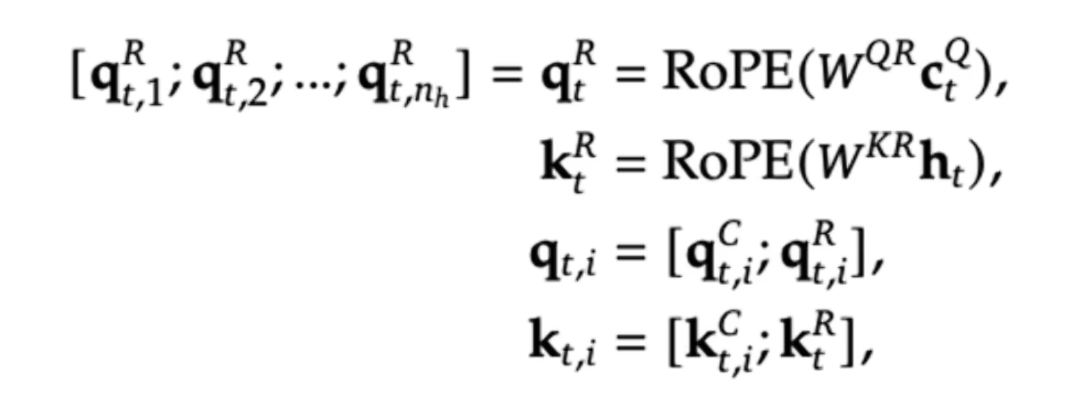
1.6 MoE
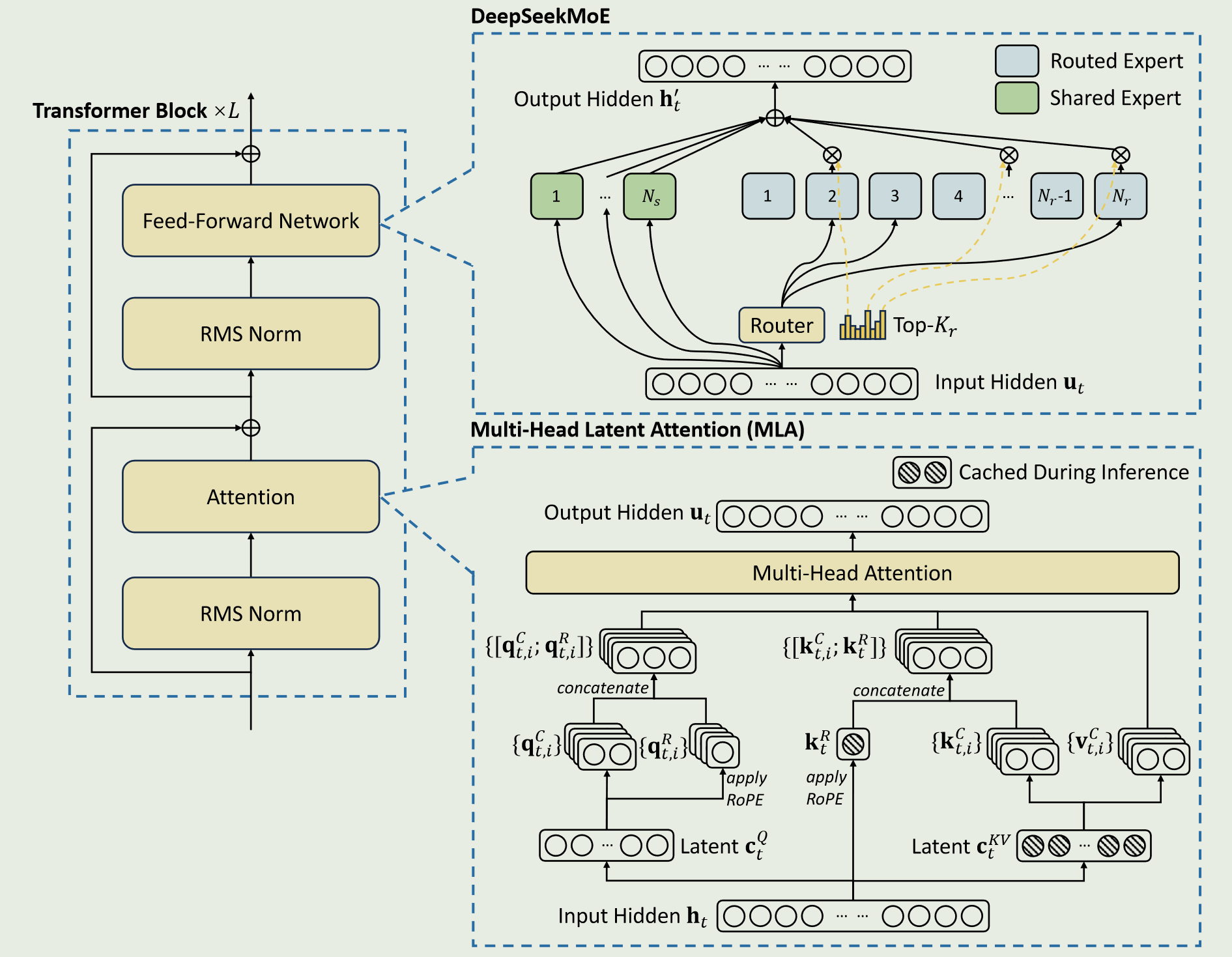
下面是计算路由的函数,sigmoid

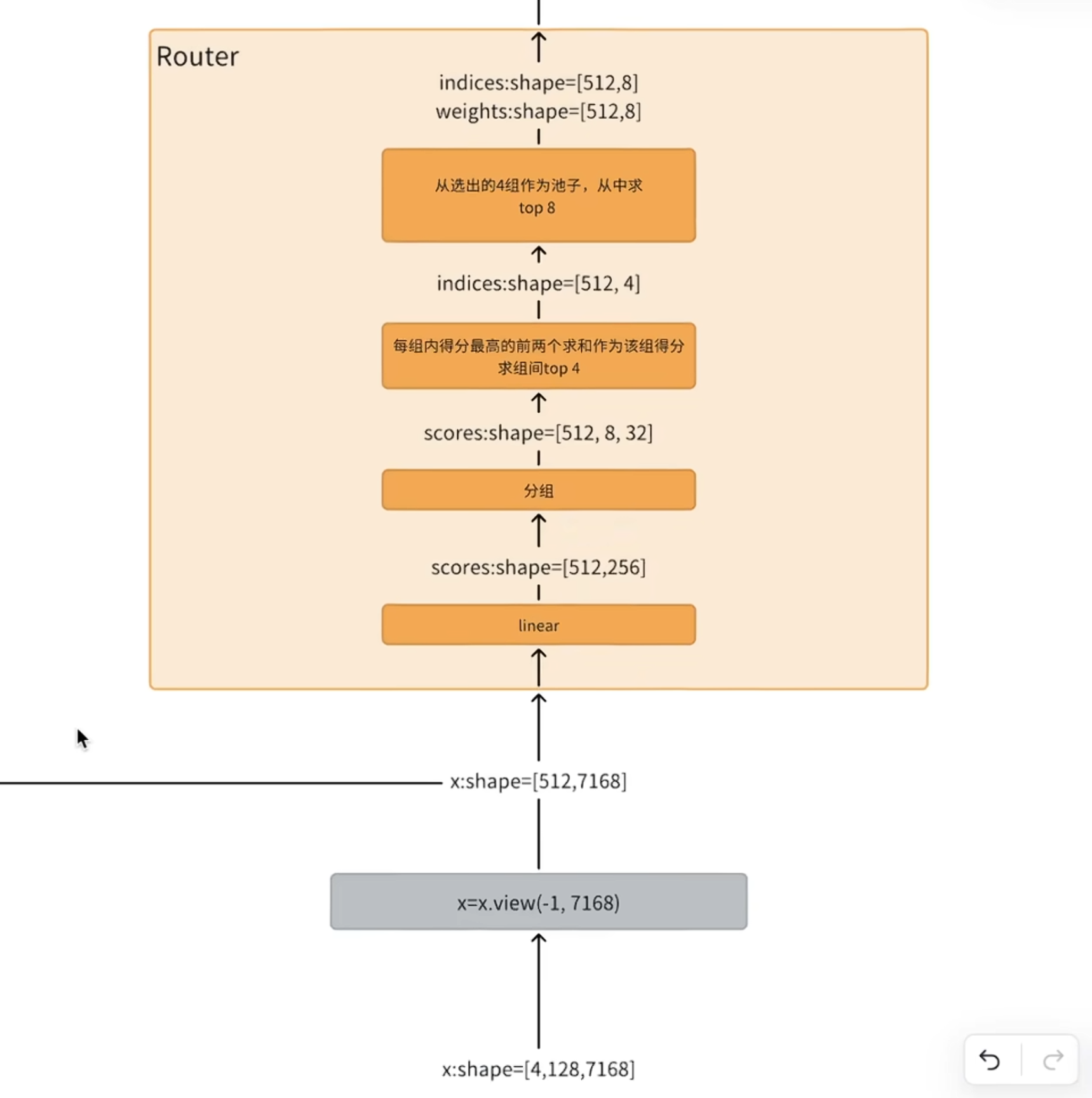
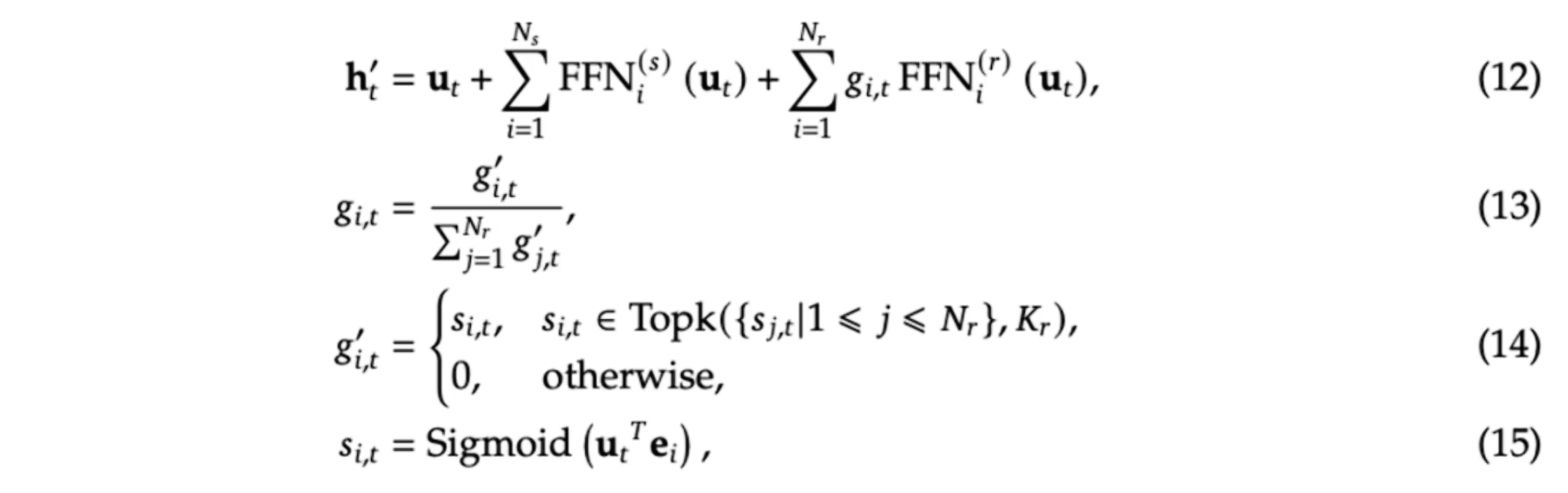

route的行为是对输入进行一个linear,把linear的结果进行分组(取决于要激活的专家个数),在组内挑选得分最高的几个,求和代表为该组的得分,最后选出对应的组的index,最后再从组index中找出对应专家的index和专家权重
1.7 Flash attention比较FA2和sdpa的效率
论文分享:从Online Softmax到FlashAttention-2
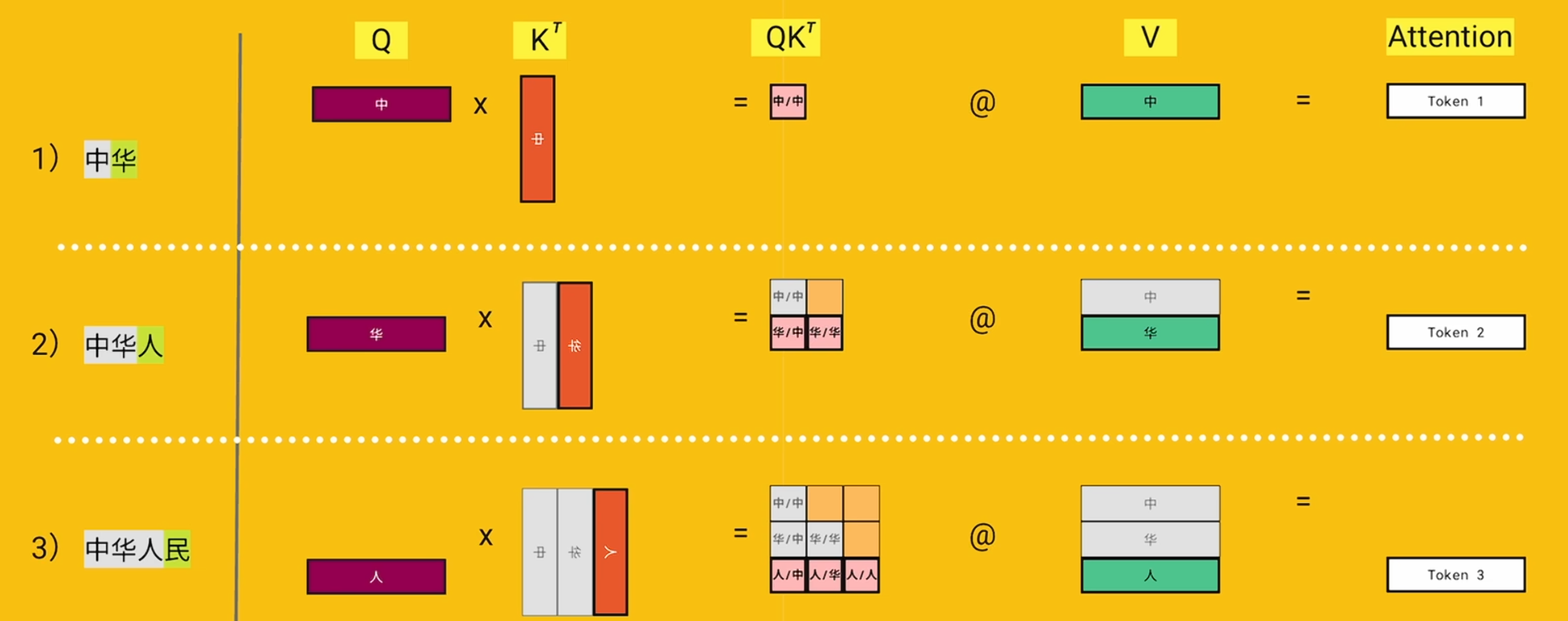
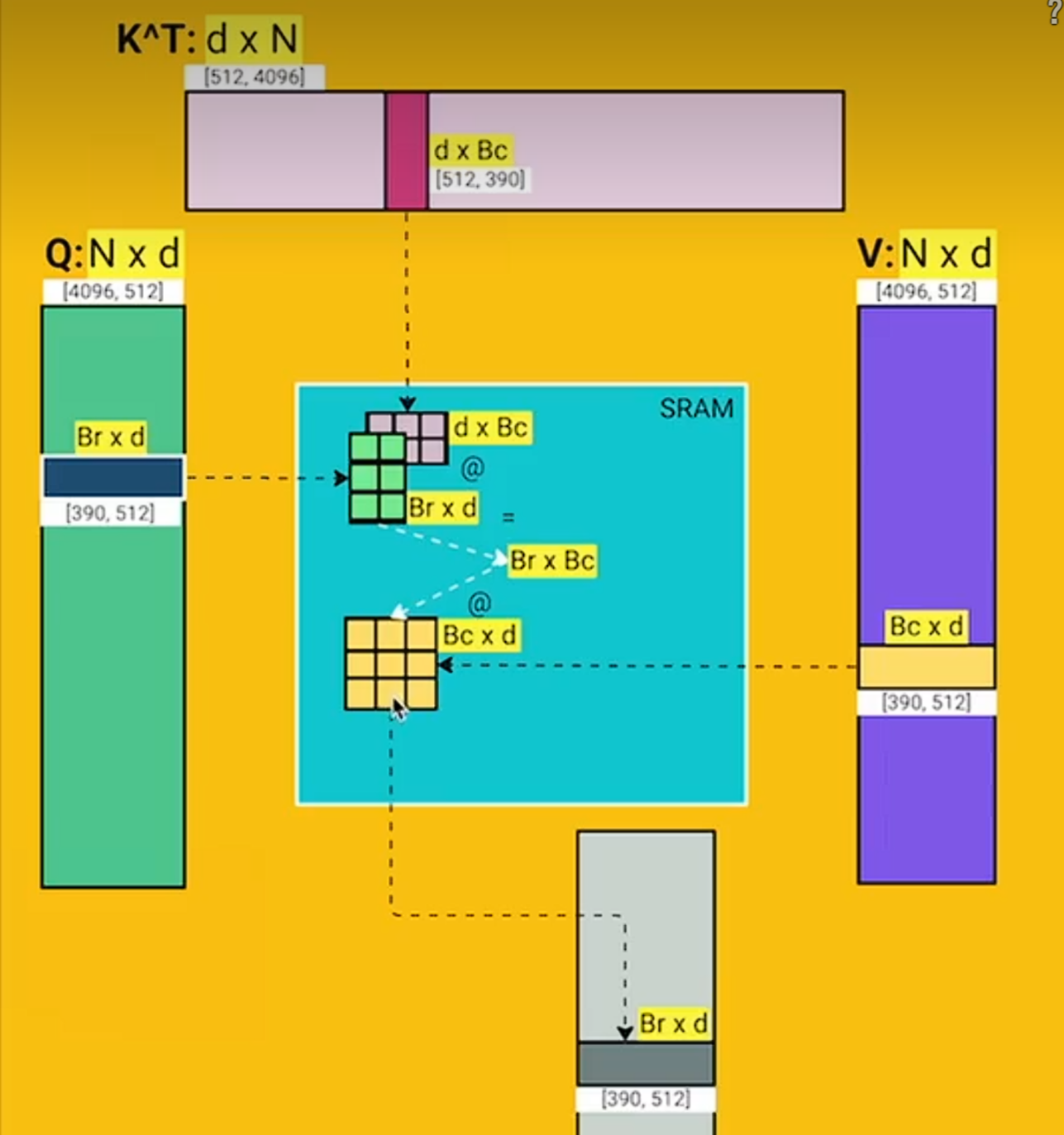
d为QKV_gen中的权重维度,Br和Bc的取值根据SRAM的大小,存储qkvo4份,计算如下
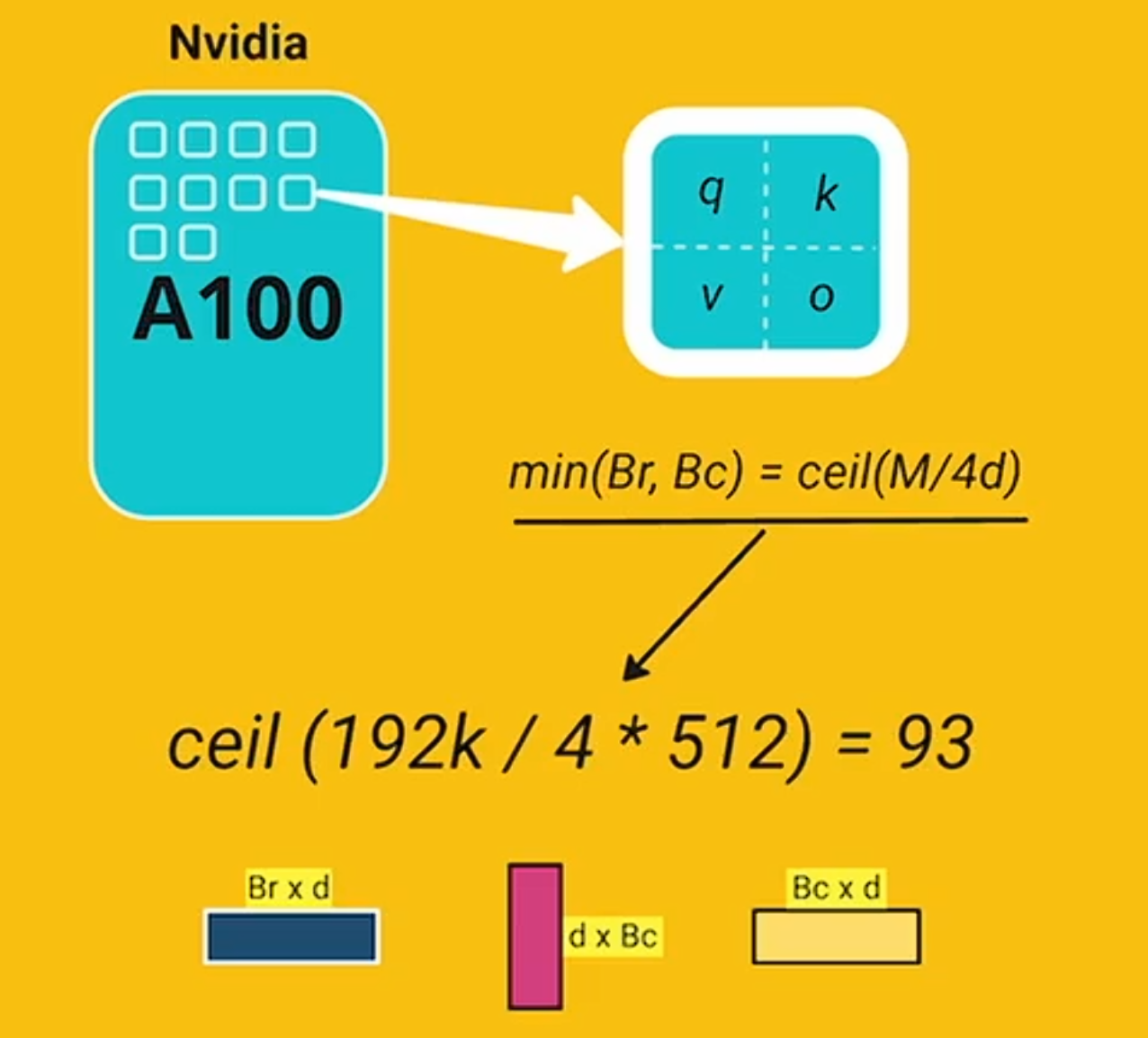
在GPU中,QKV存在HBM中,在计算softmax的时候,会分块加载到SRAM中。比如Q不断更新,K暂时不变,Q全部轮询完了之后,加载下一块K,继续更新Q直到S全部计算完毕
但是flash attention可以让我们一次读+写,不需要再将PV存储到HBM,load QKV,在softmax阶段,存储一个全局的m和l,再修正S中的最大local值带来的误差,写回HBM的就是

外循环是KV层面,内循环是Q层面,循环完一个Q就刷完了O,循环KV的结果是不断刷新O(原基础上叠加每一行)
在SRAM上计算的变量如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
K, V: Bc*d
Q, O: Br*d ≤ d*d
S, P: Br*Bc ≤ d*Bc
l, m: Br ≤ d
注意,整个M的容量约是4*Bc*d
内循环是对O进行从上往下刷新,而外循环KV是重复刷新整个O,因此内循环load Q之后的计算,都会更新l,m,O
step1: 导入KV (+2*Bc*d)
step2: 导入Q, O, l, m (+2*d^2+2d)
step3: 计算S (+Bc*d) (共3*Bc*d+2*d(d+1))
step4: 释放QK (-2*Bc*d) (Bc*d+2*d(d+1))
step5: 用S计算m~ (+d),用S和m~计算P~ (+Bc*d)
step6: 释放S(-Bc*d)
step7: 利用P~计算l~ (+d)
step8: line11的m和l更新 (+2*d)
step9: 利用l^new, m^new, l, m, O, P~, V原地更新O并储存O (-d^2)
step10: 储存l_new, m^new (-2*d)
step11: 释放其他变量


flashattention2主要是用KV的访问次数换取了Q的load、O的load和store次数
flashattention1是需要涉及wrap之间的同步 同时也可以做到seq_len层面的序列并行SP,不知道能有多大的提升
1.8 ring attention(SP also)
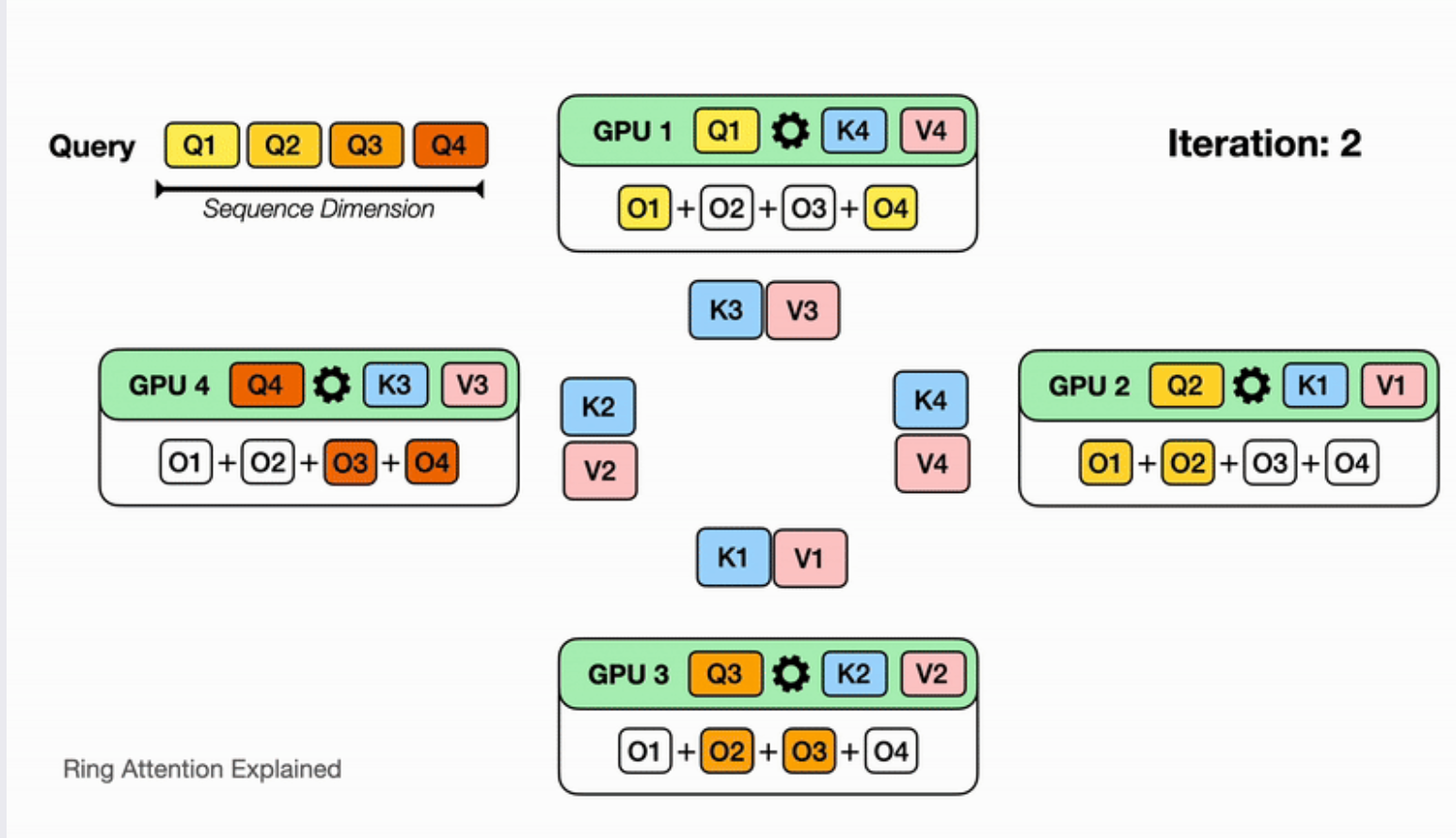
如果引入SP+PP,针对norm操作,对seqlen进行拆分,这样可以将原有的allreduce拆成AG+RS
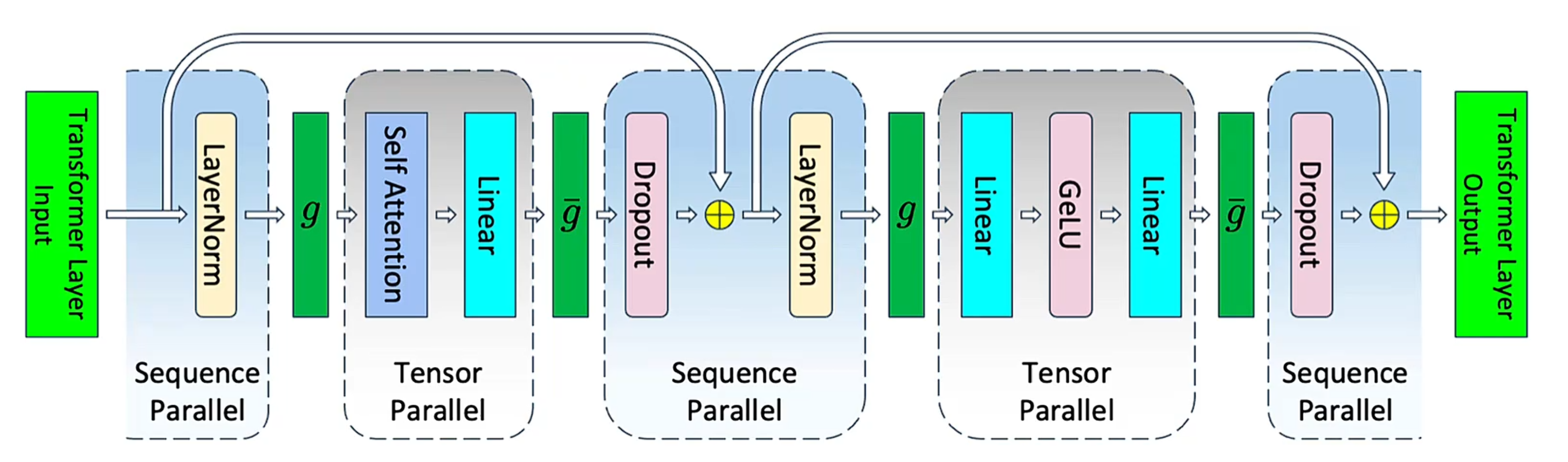
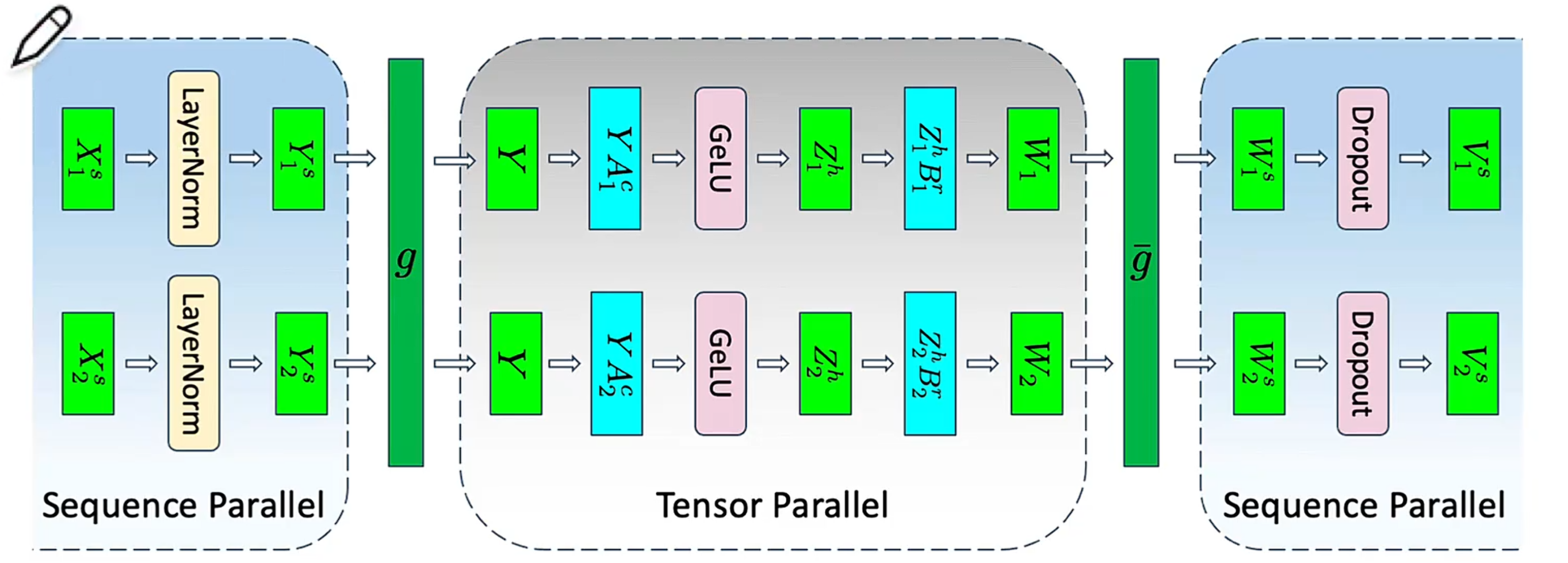
1.9 前向传播和反向传播
只有在分类任务里面,softmax和Loss是紧挨着的时候才会有这种巧妙的情况,像现在的transformer是用不上的,因为后面还有很多FFN
1.10 Boundry
compute time:受throughput限制,参数指标FLOPS = Floating point operations /s 每秒可以执行多少次浮点运算,例如4090可以达到82.58 TFLOPS
memory access latency:受bandwidth限制,但4090只能达到1.01TB/s ,加载数据的速度远远低于实际执行计算的速度
Computational Intensity: TFLOPS/B ,每次访问内存时要执行的浮点运算次数,描述了一个Roofline Model
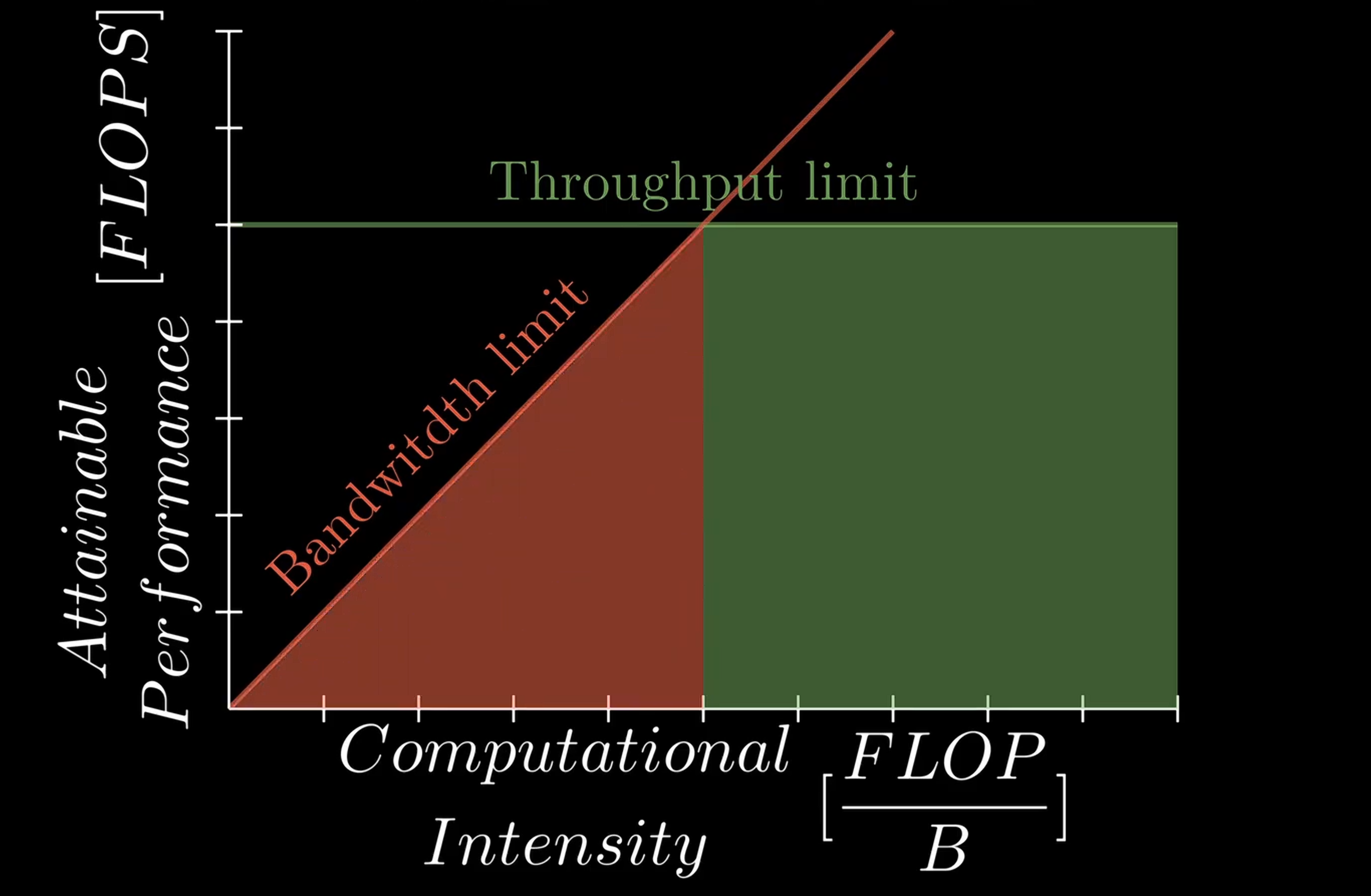
斜坡的斜率是性能,提高斜率(比如降低计算延迟)能改善这个workload的throughput
反之如果,比如一个workload完全落在了右边的平台区上,那就要考虑增加上限(capacity,值得注意的是,减少阻塞(例如low-latency/runahead/out-of-order/unblocking/high-bandwidth…)也对此有益),把这个平台往上抬,才能把workload的throughput托起来。
roofline相关的计算公式
由GQA性能数据异常引发的对MHA,GQA,MQA 在GPU上的感性分析
每个SM 都会对同一份KV head 做重复的load,导致GQA 在L2 load 上的数据量等效于MHA 在L2 的load 数据量,但GQA 的KV size 小可以cache 在L2 上,导致GQA bound 在L2 而不是HBM 上,由于A100 的L2 带宽是4T,是HBM 2.0T 的2X,因此在目前这种kernel 的实现上,GQA 最多就提升2X,MQA 也如此。
GQA MQA,在GPU 上的实现带来的收益来主要自于KV cache 的减少,能放下更多的token,但同时将HBM bound 推到了L2 bound,使得memory bound 这件事并没有被改善,这也是为什么性能上GQA并没有MHA没好多少的原因
用roofline 估算GQA MQA 性能的时候,要用L2 的带宽和MHA 的KV cache size量去估算
TOPS是指每秒钟的操作次数,计算公式为:TOPS = MAC矩阵行 * MAC矩阵列 * 2 * 主频。其中,2表示一个MACC(乘加运算)为一次乘法和一次加法
A*B+C:M维度为Decode阶段的Batch Size,N为hid_dimm,K为N/TP \(\begin{aligned} Arithmetic-Intensity & = \tfrac{number of Flops}{number of bytes accesses} \\ & = \tfrac{2* M * N*K}{((M * K +K* N + M * N) * dtype_bytes) } \\ \end{aligned} \tag{1}\)
\[T_{cal} = \tfrac {number of Flops}{BW_ {cal}}\] \[T_{mem} = \tfrac {number of bytes access}{BW_ {mem}}\]如果是memory boundry:则$T_{mem}>T_{cal}$
所以: \(\begin{aligned} Arithmetic Intensity \leq \tfrac{BW_ {cal}}{BW_ {mem}} \end{aligned}\)
也就是说算术强度小于这个值的时候,是访问mem花的时间太多了,是memory_boundry
我们举个例子,一个MNK的GEMM计算,两个矩阵为MxK和KxN,假设为FP16,算数强度为15.7(上面的公式1)由于是memory_boundry,所以
GEMM:服务于attention计算的Matrix * Matrix
GEMV:服务于MLP的FC
1.11 分布式下的并行
1.11.1 DP, MP, DDP概念
- DP:数据拆分,模型复制,梯度聚合,权重更新后广播(单进程,多线程,只能利用一个CPU,单个进程读取mini-batch,切分n份给GPU)
- DDP:数据由不同的CPU以不同进程读取,分bucket实现梯度反向传播的边计算边传输,最后利用GPU之间的ring-allreduce实现同步(多线程读取多个mini-batch,在本地GPU进行计算)
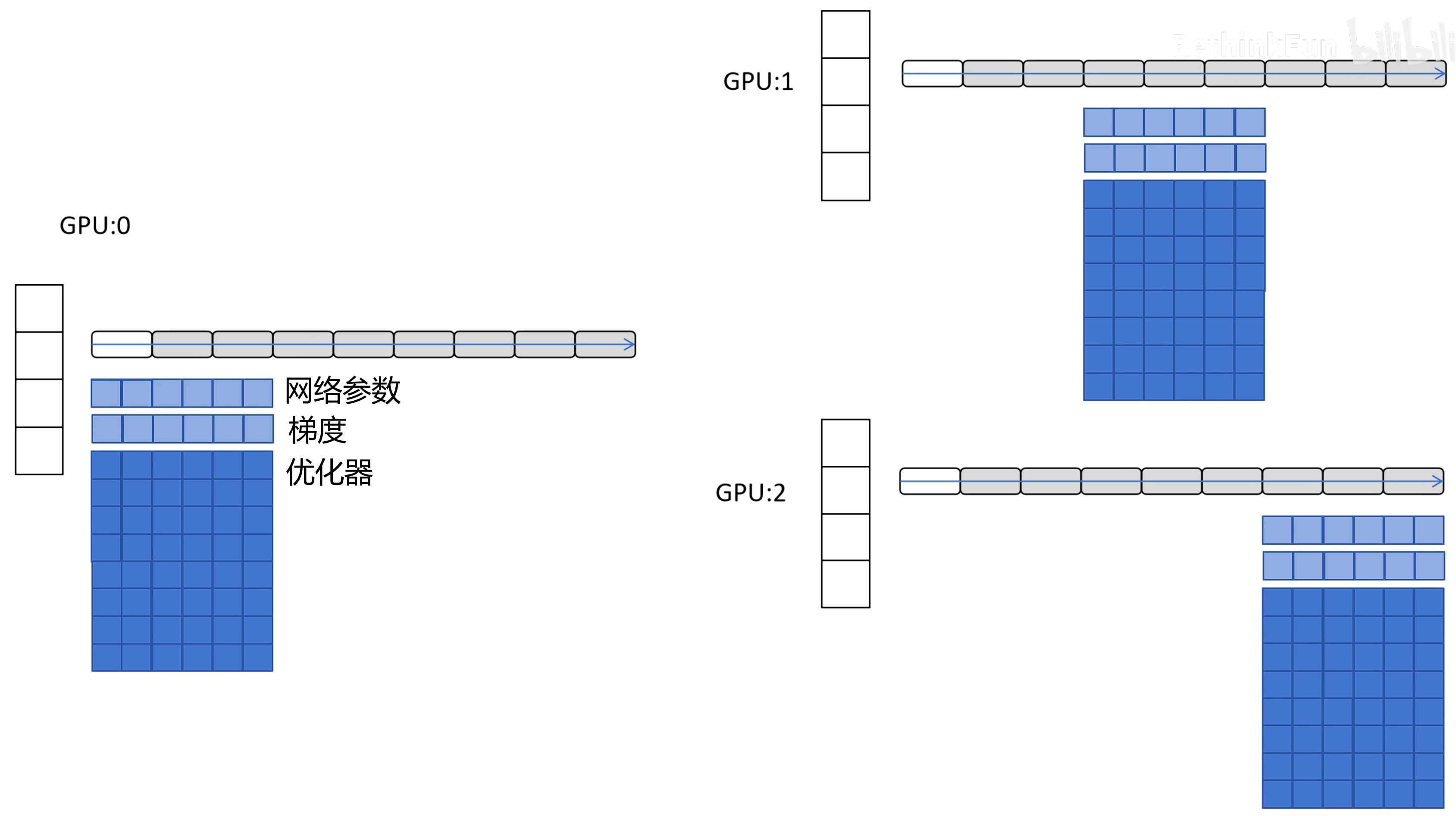
- 模型太大,显存放不下–>DeepSpeed ZeRO-1(Zero Redundancy Optimizer):每个GPU存储全部的FP16的网络参数和梯度,但是优化器的所有参数(占比很大)按网络层数拆分到每个GPU。这样在边反向传播的时候可以边同步属于自己的梯度,更新各自的网络参数,最后广播给其他GPU实现全局的权重更新。 【DeepSpeed ZeRO-2将FP16梯度也拆分了,DeepSpeed ZeRO-3 进一步将FP16的梯度以及网络参数也拆分】—— DeepSpeed ZeRO-3由于缺少部分FP16模型参数,在前向和后向传播的时候,需要拥有该参数的GPU进行广播,可以overlap广播和计算的时间。
举个例子,存在GPU012的时候,前向传播的模型参数需要靠拥有该参数的GPU0广播给1,2。而反向传播时,GPU0,1计算完本地的FP16梯度,被GPU2 all-gather到本地,实现梯度聚合
ZeRO1和2的进程总传入/传出为2X(X为模型参数量),而ZeRO3为3X,但是降低了更多的显存占用
如果head内也要切分,就是这种情况:
在分布式场景下,性能的考虑因素:计算b个样本梯度的时间$t_1$,传输m个参数或者梯度的传输时间$t_2$,每个batch的耗时为max(t1,t2)
增大batchsize(通过增大b和GPU的数量n)会使得收敛变慢(可以调小学习率),但是还是要更多的epoch,导致训练时间增大
(总结就是,我用了更多的计算单元,我训练单次时间减少了,但是为了收敛到更好,我需要更多的训练次数,我的训练时间还是没有降低)
- 所谓模型并行(MP),就是设备上存储不同layer的参数
- Pipeline并行(PP)=改进版的模型并行,通过微批处理(micro-batching)减少空闲时间,提升并行效率
Gpipe 论文论文mini_batch把一个大的batch拆分成多个小的batch,只存储输入X,反向传播需要的中间激活值可以通过X重新进行计算(计算换空间),这样反向传播不需要储存每一层的中间激活值。
需要注意的是,一次额外的前向计算开销占整个系统计算开销的1/3
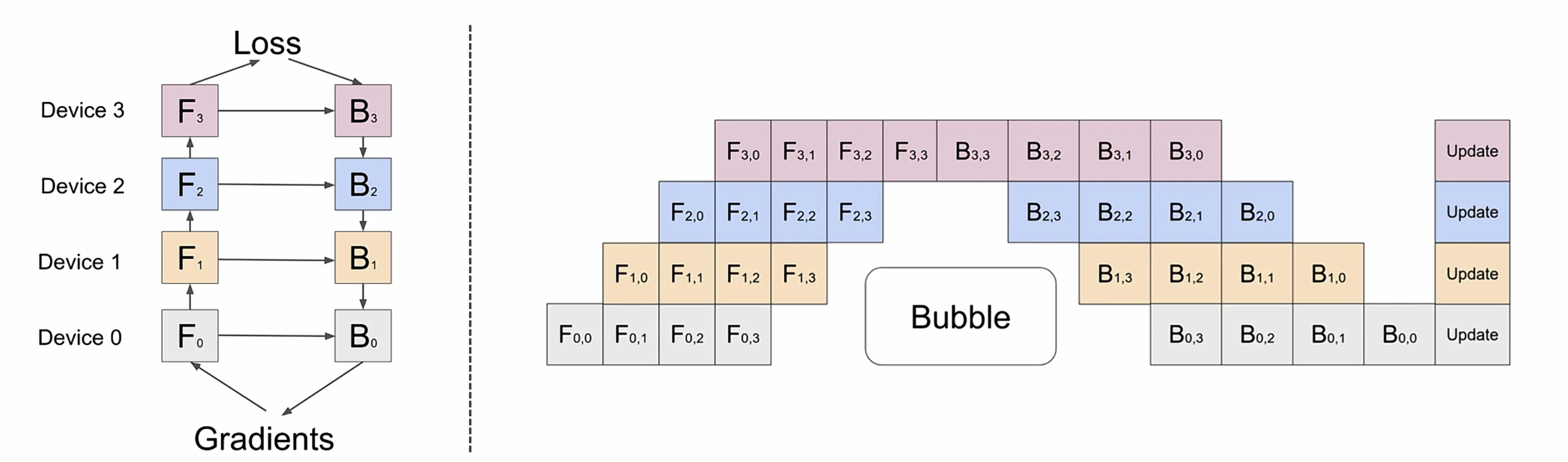
PipeDream使用非交错式1F1B,没有减少bubble但是节省了峰值显存。
1.11.2 各种并行的切分情况
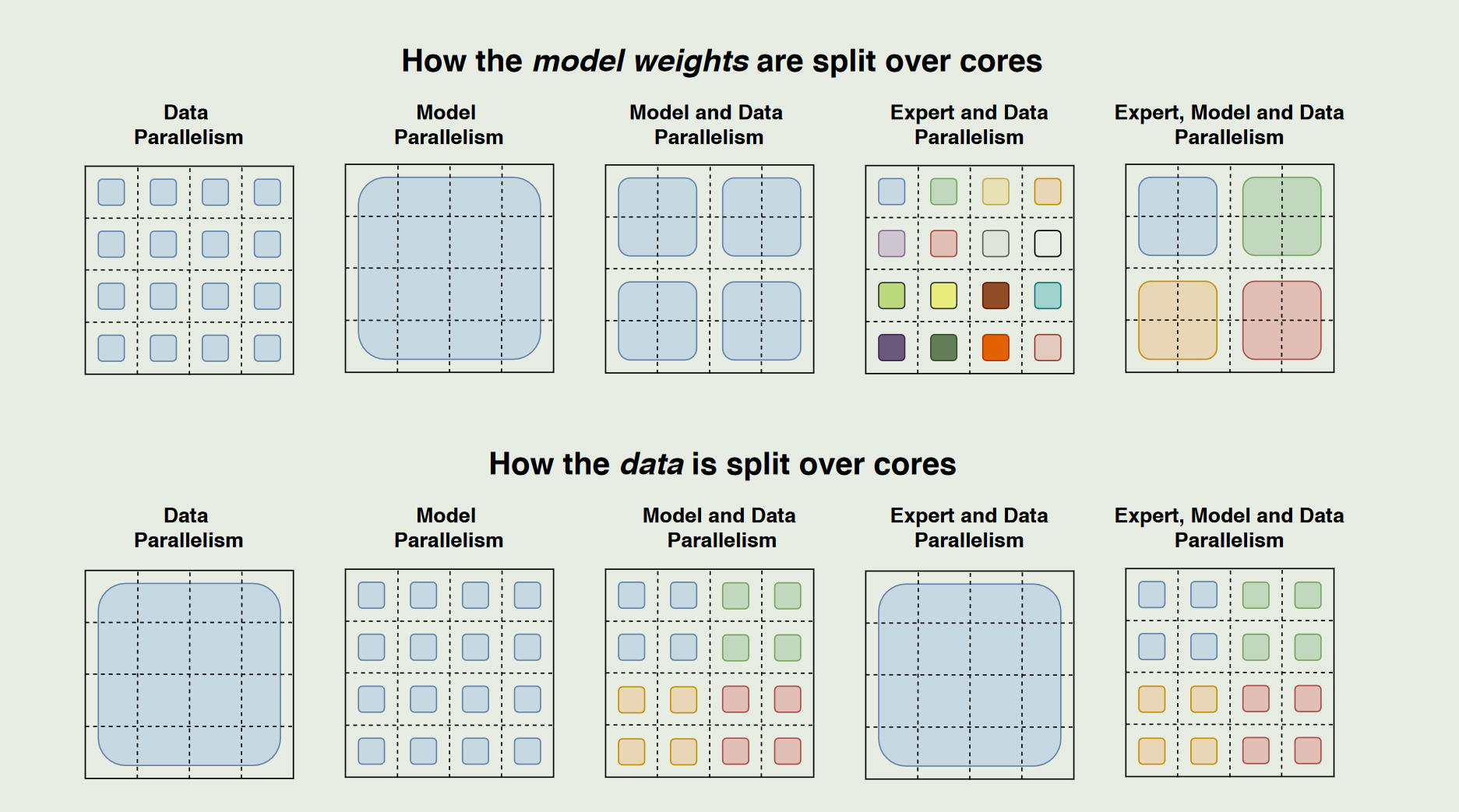
在多核(或多GPU/TPU)环境中对大型模型进行并行化的split方案:
第一行:模型权重在各核心之间的切分方式、第二行:输入数据在各核心之间的切分方式。同一个颜色 / 同一个大矩形往往表示的是同一个权重矩阵的某一块;
- Data Parallelism:每个设备(核心)都持有完整的模型参数,但只处理一部分的数据(即 batch 切分)
- Model and Data Parallelism:不同的核心各自保存不同的一部分参数。大家合起来才构成完整模型。不同颜色一般是用来区分同一个大批次(batch)里被切分开的不同子块。所有颜色合起来才是同一次 forward/backward 的整个 batch ,换句话说,整张图中的所有颜色块加起来才构成一次完整的 batch;在实际训练中,我们往往会在每个训练 step 中取一个大的 batch,然后按照硬件并行策略把它拆分给各核心,各核心并行处理后再在梯度或激活等环节进行必要的通信与汇总。
- Expert and Data Parallelism:每个小颜色方块可以看作一个**专家(Expert)对应的参数 ** ,但“非专家”部分(如自注意力层、嵌入层等)通常会完整复制,
1.11.3 TP张量并行
列并行,会切分权重但不切分输入,好处是可以让硬件并行。虽然计算attention不需要allreduce,但是后面的Dropout还是需要allreduce
行并行,输入和权重都会切分
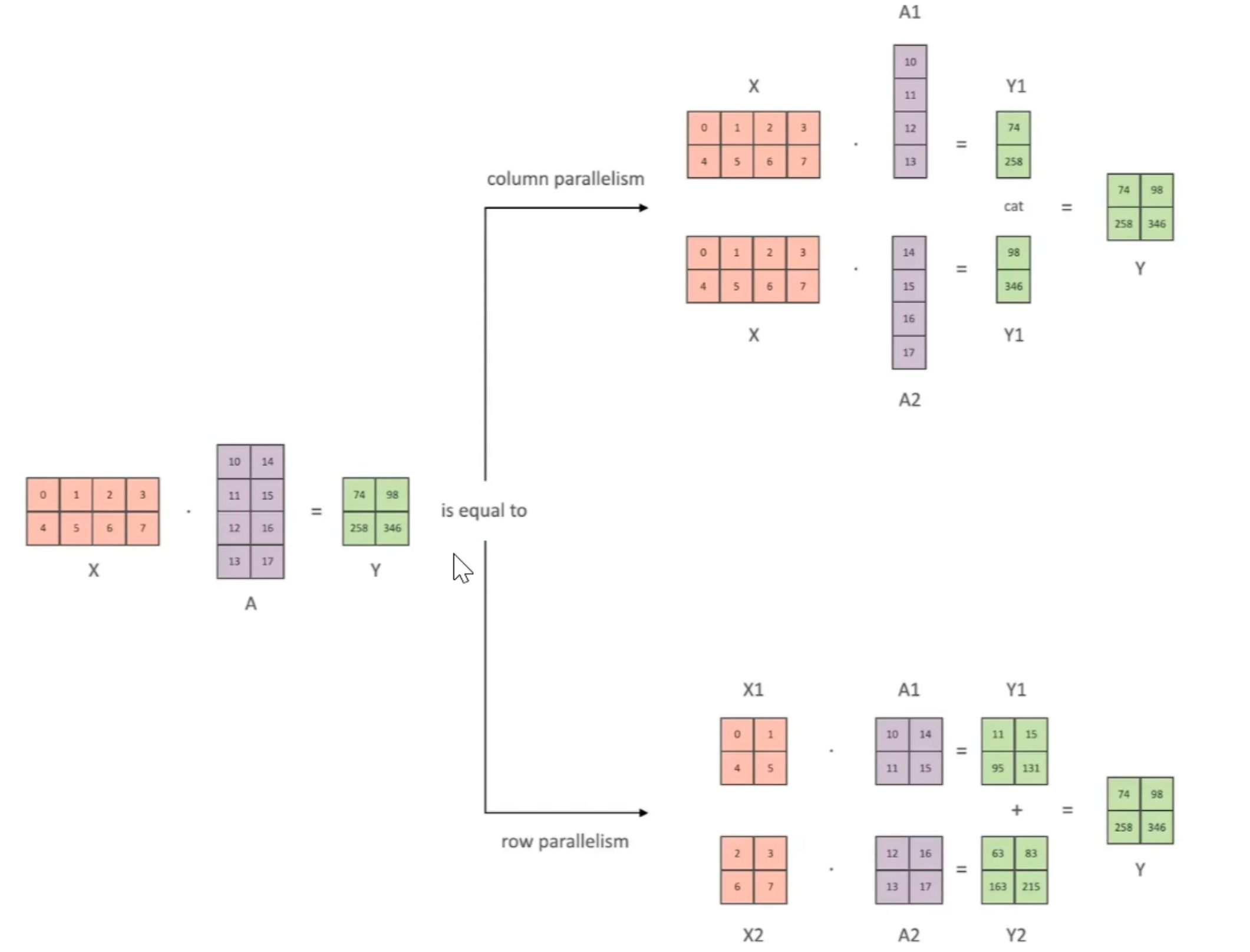
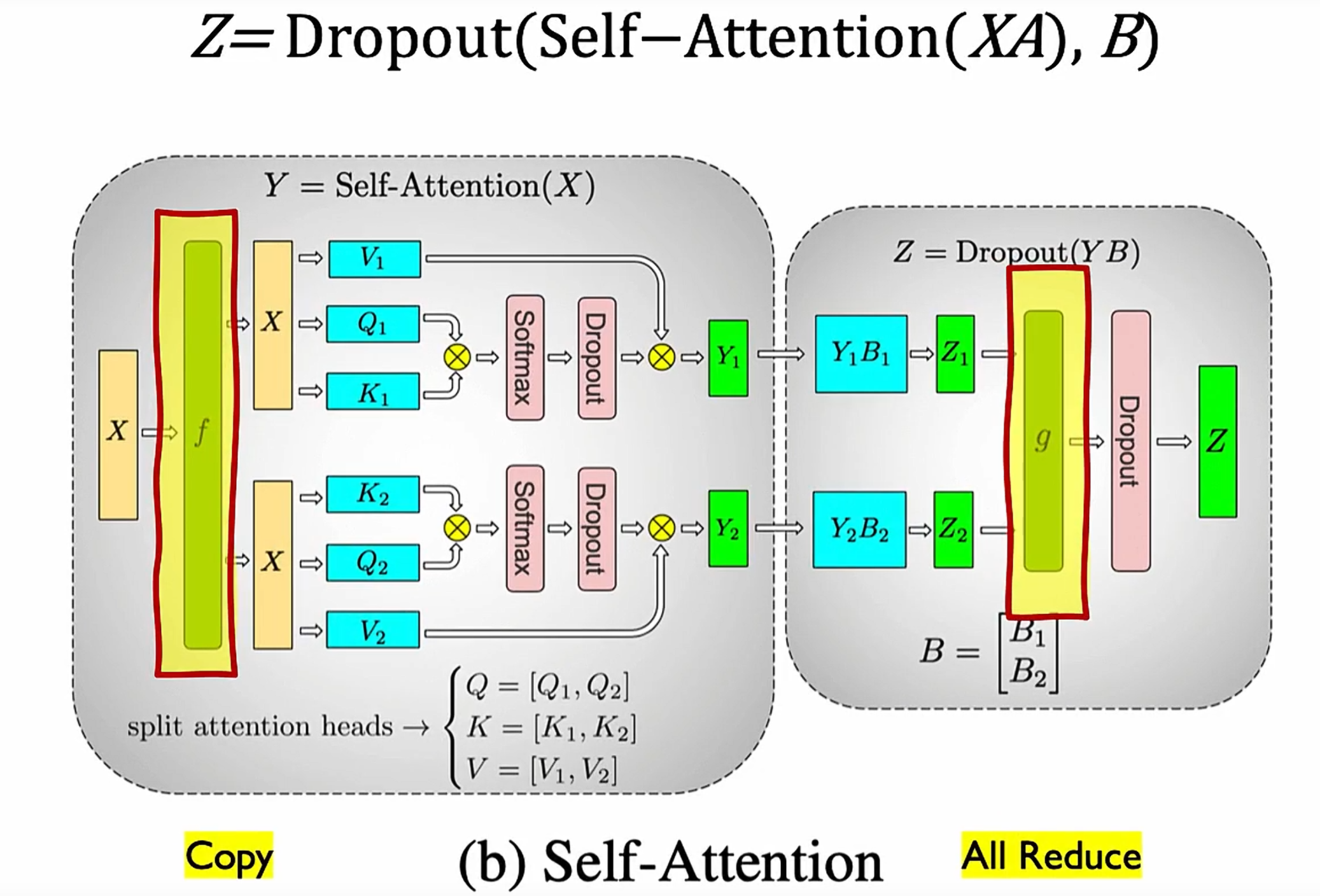
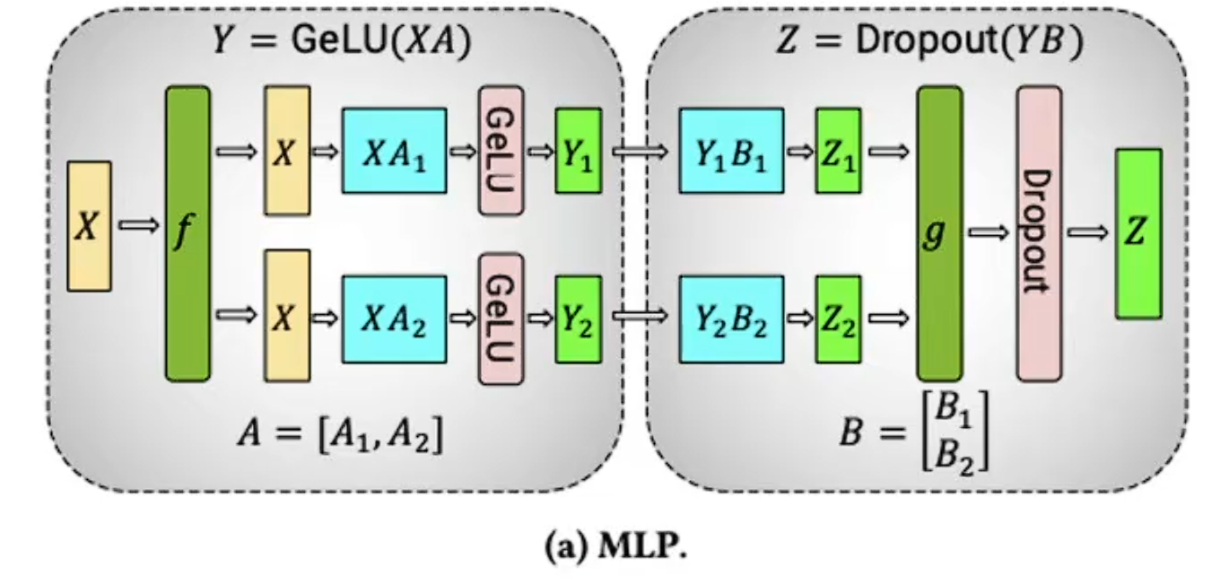
需要两次通讯,第一次是broadcast输入X,第二次是allreduce的g,同步dropout之后的结果
二、Switch Transformers
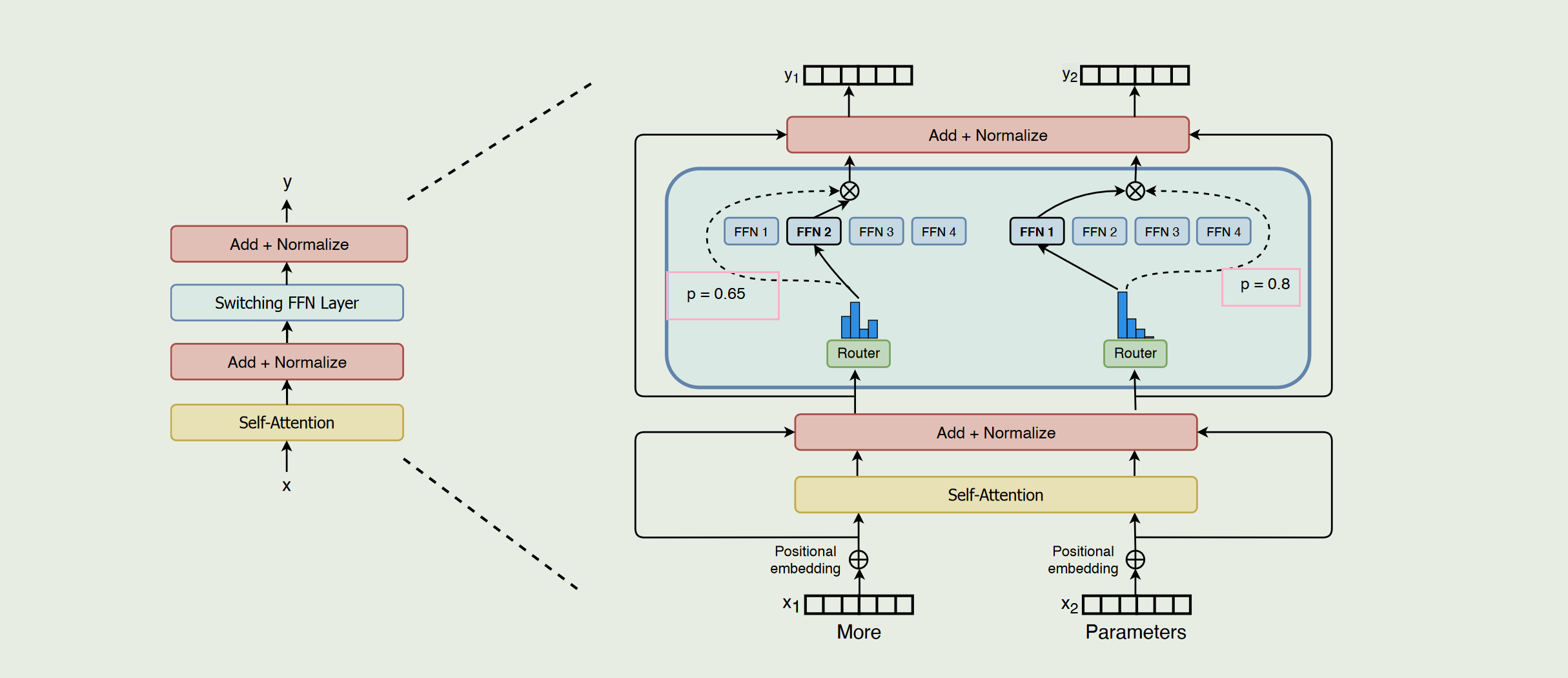
“专家权重”或“可信度”通常由一个 路由器 (Router) 或 门控网络 (Gating Network) 来计算:
每个 token先经过前面的自注意力层与 Add+Norm 等操作后,得到一段向量h。路由器常常只是一个 单层线性变换(有时会加上激活函数),把 h 投影到“专家数”维度上。获得向量z,z 的每个分量对应一个专家(Expert)在“未归一化”下的得分,将 z 做 softmax 得到概率分布$p_i$,对应第i个专家的可信度。
三、llama解读

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
model_parallel_size:并行执行模型的设备数量
#每个设备上运行的头的数量
n_local_heads = n_heads // model_parallel_size
#每个设备上键和值的头的数量
n_local_kv_heads = n_kv_heads // model_parallel_size
#每个键值需要重复计算的次数
n_rep = n_local_heads // n_local_kv_heads
#每个头的维度
head_dim = dim // n_heads
-----------------------------------------------------------------------
#举个例子
假设总共8个头,模型并行的设备为2,键值头数为4
1. (每个GPU处理) 8//2=4 头
2. (每个GPU处理) 4//2=2 键值头
3. (每个键值头需要被重复利用) 4//2=2次
也就是说,每个GPU需要处理4个头,但是只有两组独立的KV(权重共享)
3.1 llama中的ROPE
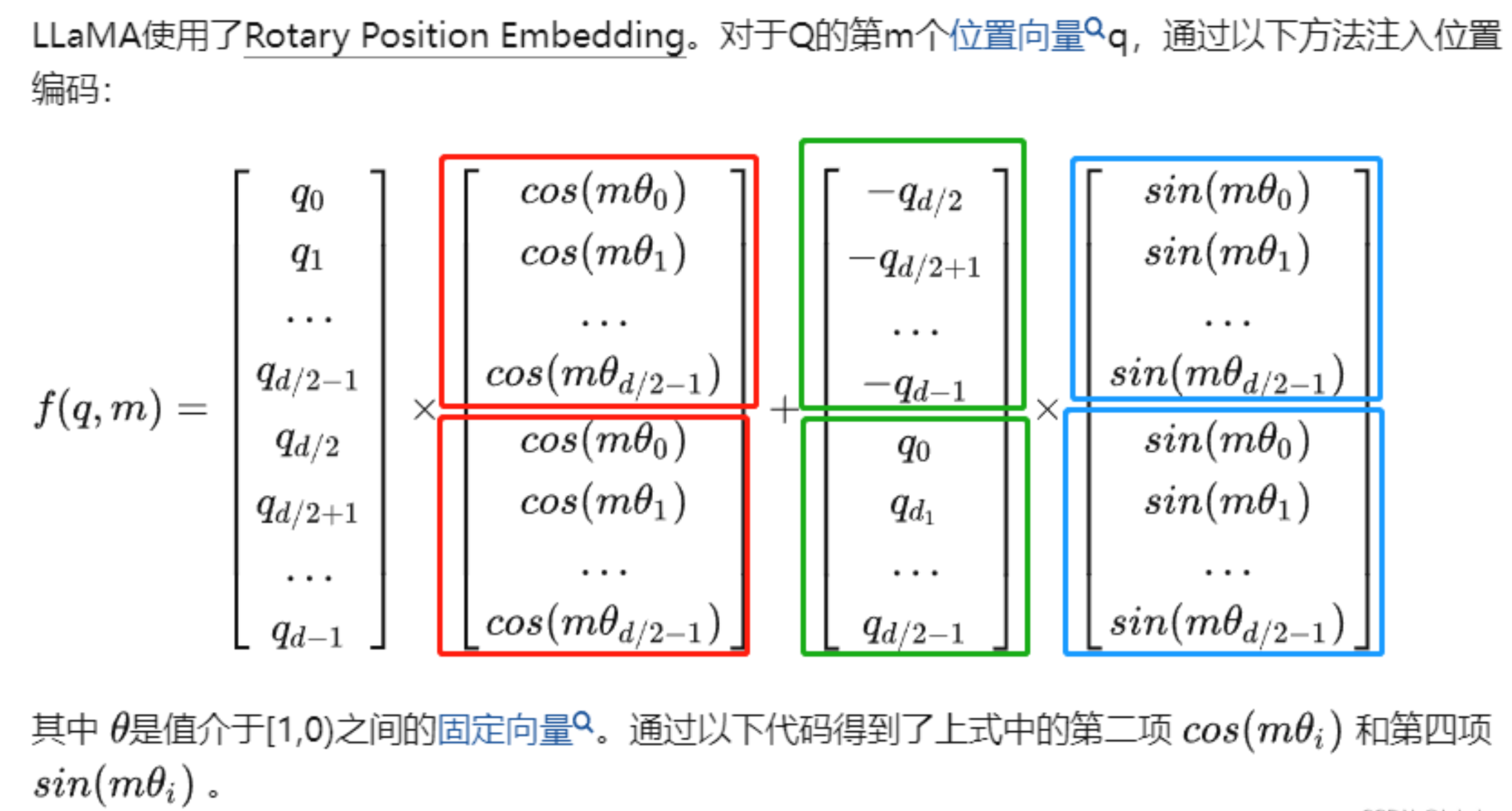
远程衰减性指的是,如果向量k在向量q的附近,那么它们的应该偏高,反之应该偏低。所以怎么拆分不影响准确性,他只要满足两个向量内积时候那个衰减因子是正确的就行了
四、量化概念
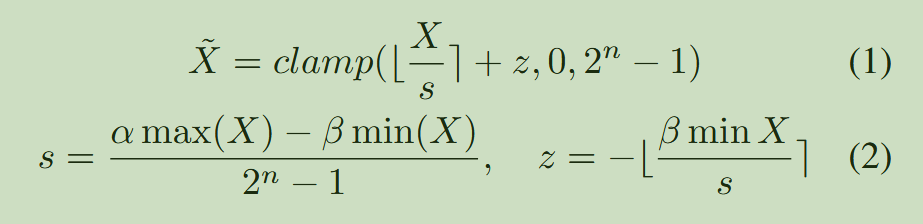
五、PD分离
5.1 DistServe–物理拆分
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
- 为了达到TTFT和TPOP的时间约束,通过batching或者增加设备来降低时间
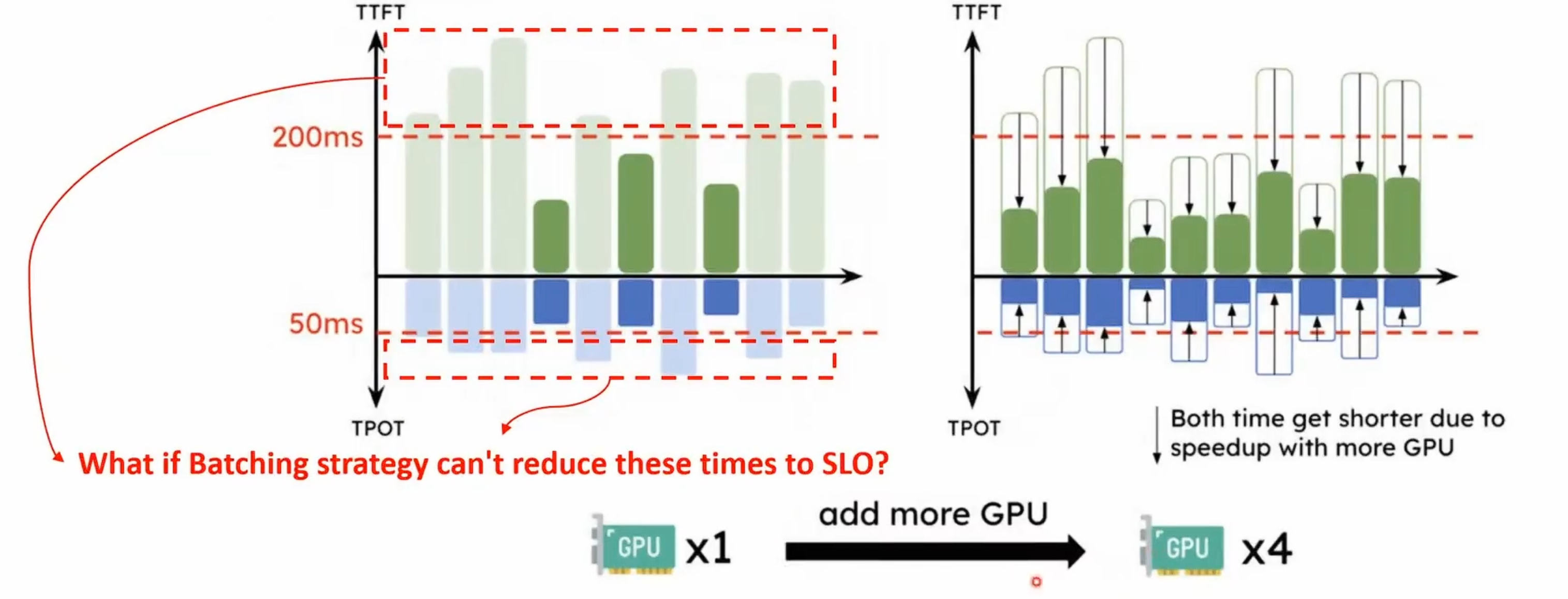
- 2.(1)找到Prefilling中影响吞吐率的拐点 (2)multiple prefill instances to a single decoding instance
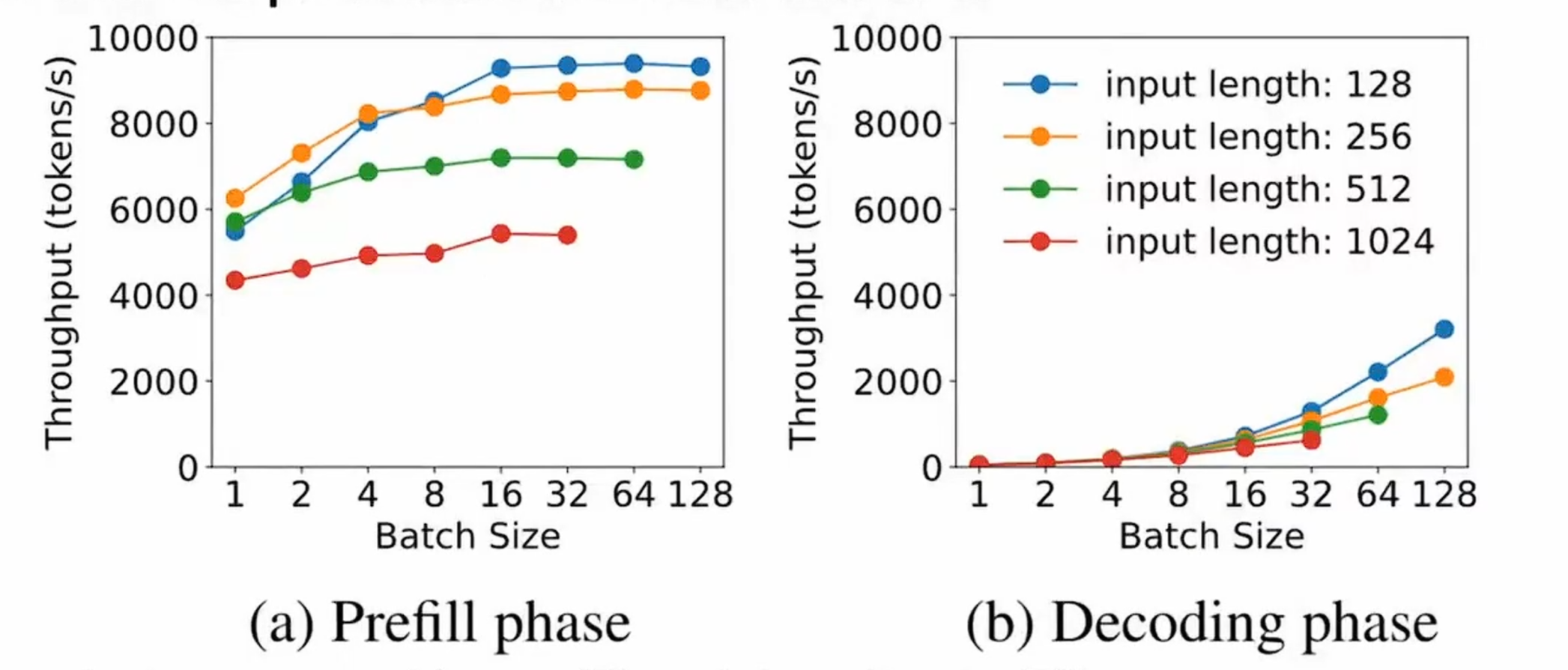
PD带来的影响是KV Cache的传输
1)The KV cache size of a single 512-token request on OPT-66B is approximately 1.13GB. Assuming an average arrival rate of 10 RPS, it needs to transfer 1.13GB×10-11.3GB data per second-or equivalently 90Gbps bandwidth to render the overhead invisible.
2)Many modern GPU clusters for LLMs, equipped with cross-node InfiniBand (e.g., 800 Gbps), can effectively hide these communication overheads.
3)If cross-node bandwidth is limited, DistServe relies on the commonly available intra-node NVLINK, where the peak bandwidth between A100 GPUs is 600 GB/s, again rendering the transmission overhead negligible.
4)Solving the placement problem can reduce communication overhead.
对于inter带宽比较低的Cluster,考虑算法2. The communication overhead within the node is negligible. (Require the same stage of prefill/decoding instances to be on the same node)
利用节点内(inter)的大带宽让KV cache的传输只发生在节点内,因为KV-Cache Transfer only happens between the same layer.
- 推理时prefill适合使用模型并行策略。解码阶段是内存密集型适合使用数据和流水线并行。如果预填充和解码同时配置在一个计算设备上,并行策略不能单独配置。
- DistServe的实验结果显示, Prefill阶段:在请求率较小时,更适合张量并行(TP), 在请求率较大时,更适合流水线并行(PP)
- Decode阶段: GPU数量增加时, PP可显著提高吞吐量(因为其处理方式是流水线化的), TP 则可降低延迟(减少单个请求的处理时间)
5.2 Pod-attention(ASPLOS25)–内核融合
PD分离下混合batching,prefill和decode的kvcache无法复用所以attention部分是按顺序分离计算的,这篇文章讲的是融合,怎么去分配prefill和decode的线程块CTA=多个warp,太特定针对GPU了 没啥好看的
5.3 KVDirect–优化kvcache的传输
vLLM核心技术PagedAttention原理这篇文章讲解了实际kvcache的存储在物理空间上是零散的
5.4
六、KVCache的计算
输入序列的长度S,输出序列长度t,以f16保存,H=hid_dimm,l为layer层数
KV Cache的峰值显存占用为:$b(S+t)Hl2*2$
七、带宽瓶颈的计算
计算通信比 $CCR=\frac{每秒可执行的浮点运算量(FLOP/s)}{每秒需要通信的数据量(Byte/s)}$
根据具体的应用场景所需的CCR和芯片的算力峰值,计算出芯片所需的通信需求
带宽利用率=$\frac{通信需求带宽}{硬件拥有的网络带宽}$,当带宽不足,通信就成为瓶颈
八、多模态
N、偶然看到一些可能以后有用的东西
- Aho-Corasick 模式匹配算法 : 并行匹配给定的长输入,含有需要匹配内容的index位置