电路设计tips
这里有一个基础的tb的队列比较 长代码直接贴文件
一、STA静态时序分析章节
时序基础
亚稳态的概念:数据传输中不满足触发器的建立时间 Tsu 和保持时间 Th,或者复位过 程中复位信号的释放相对于有效时钟沿的恢复时间(recovery time)或 removal time 不满足,就可能产生亚稳态,此时触发器输出端Q在有效时钟 沿之后比较长的一段时间处于不确定的状态,在这段时间里Q端在0和1之 间处于振荡状态,而不是等于数据输入端 D 的值,这段时间称为决断时间 (resolution time)。经过 resolution time 之后 Q 端将稳定到0或1上, 但是稳定到0或者1,是随机的,与输入没有必然的关系。
recovery time:类似与setup,需要在时钟来临之前一段时间撤销复位
removal time:类似于hold,需要在复位的时候保持一段时间
- 时钟门控信号的检查
下面的是acitve high的时钟门控(AND或者是NAND)
需要保证门控信号的变化仅在时钟的非活动期间发生(5-10),data arrival time会从门控信号的寄存器CK端开始作为起点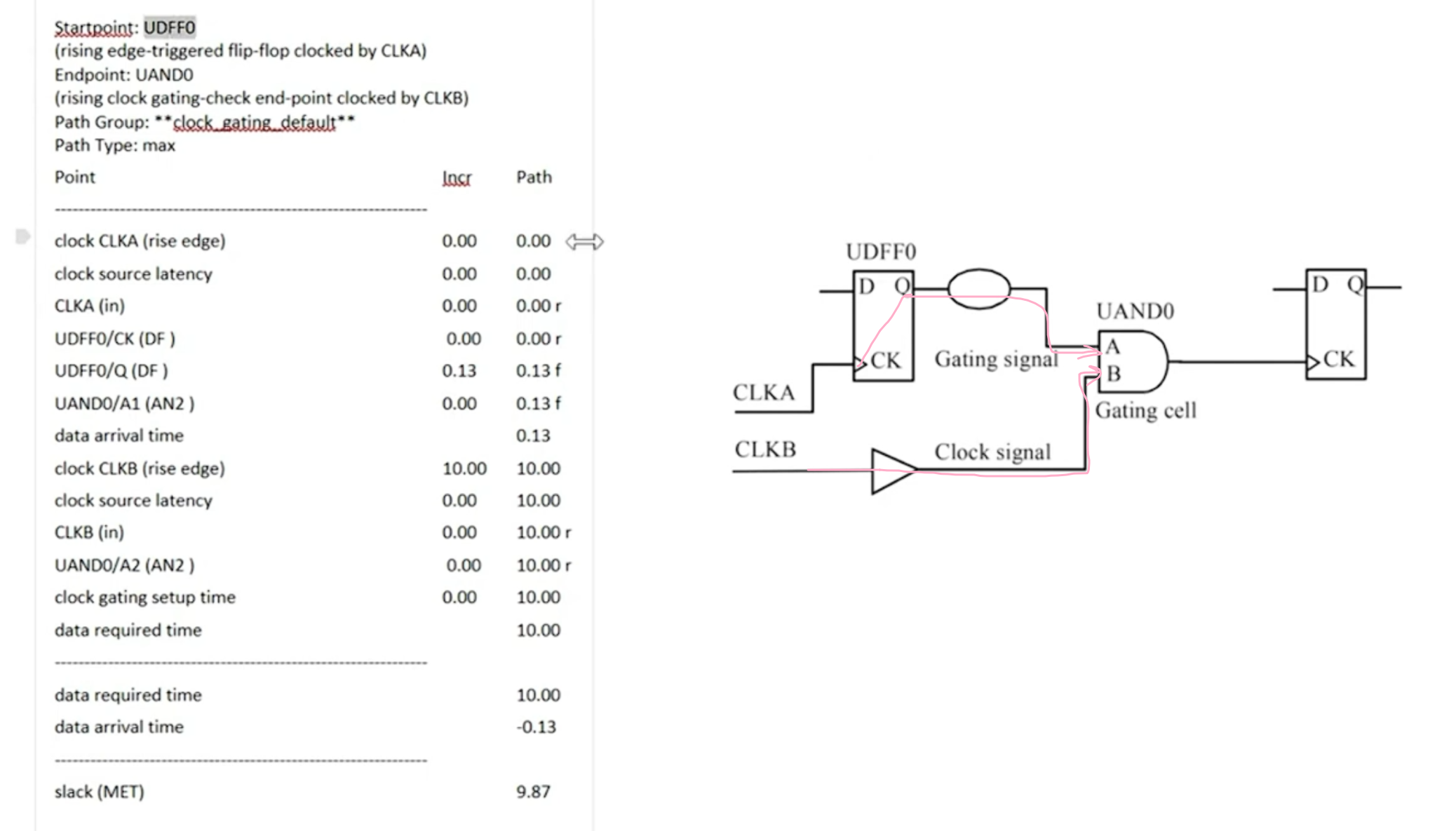
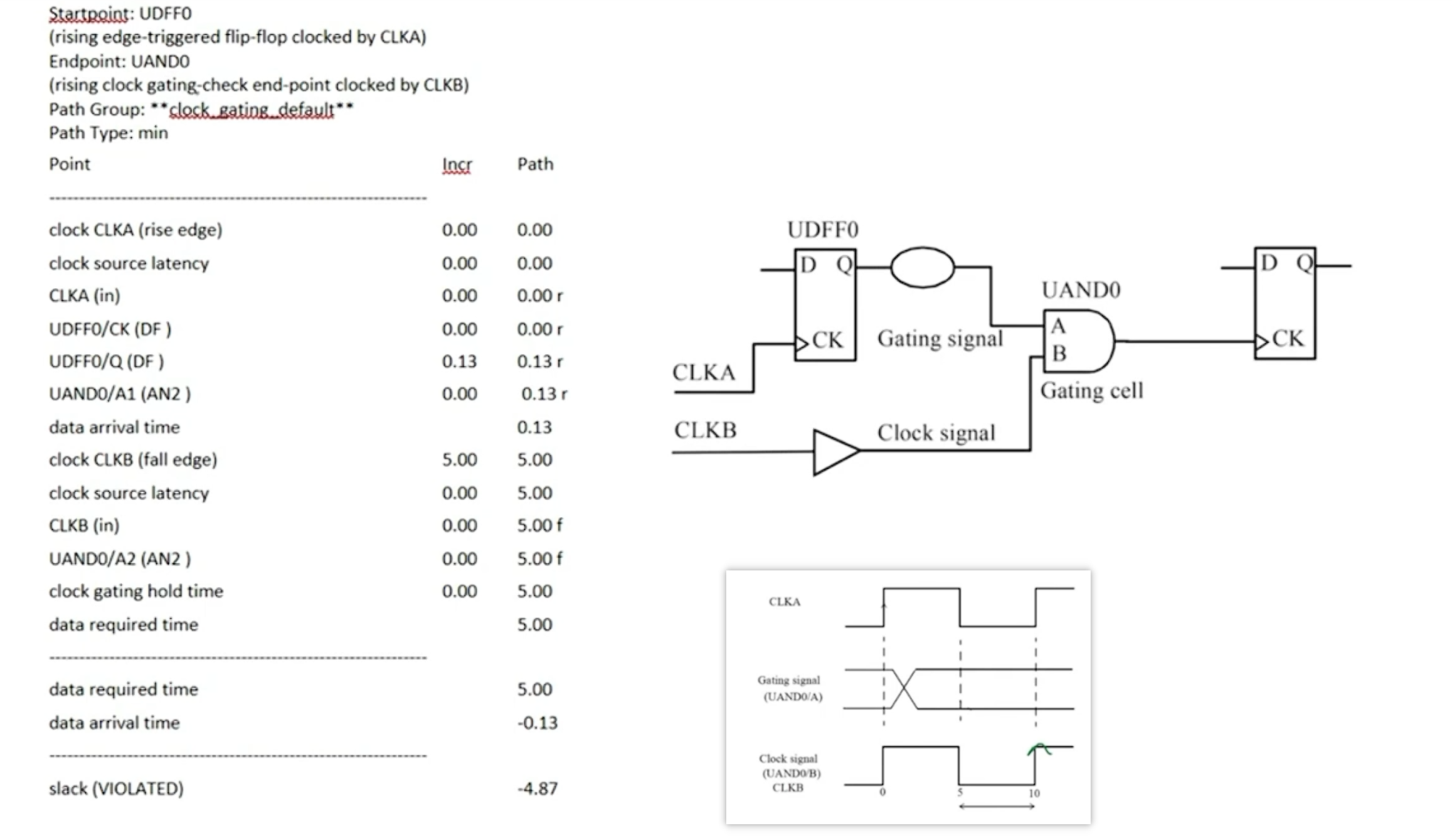
而active low的时钟门控需要在时钟的活动期间发生变化 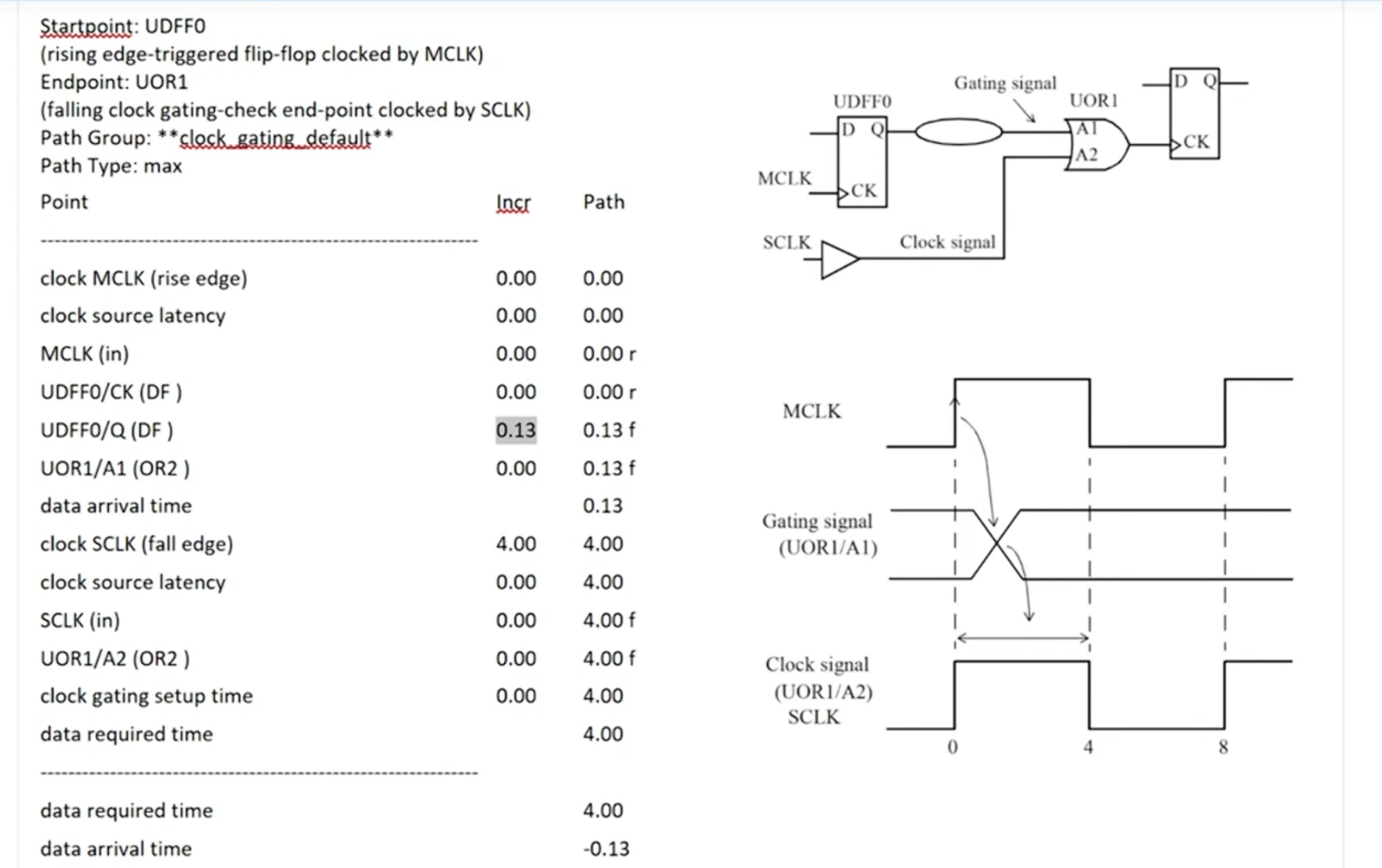
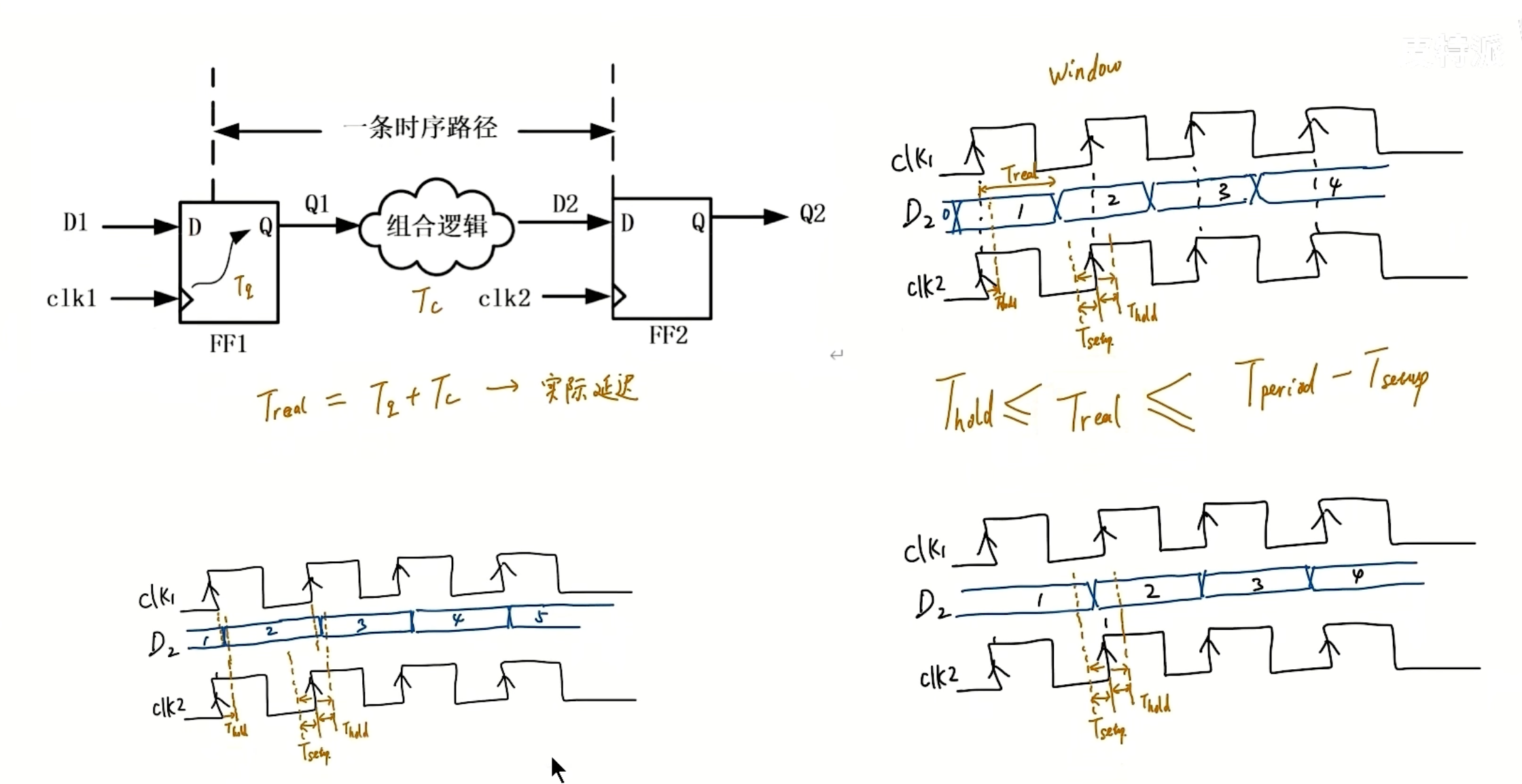
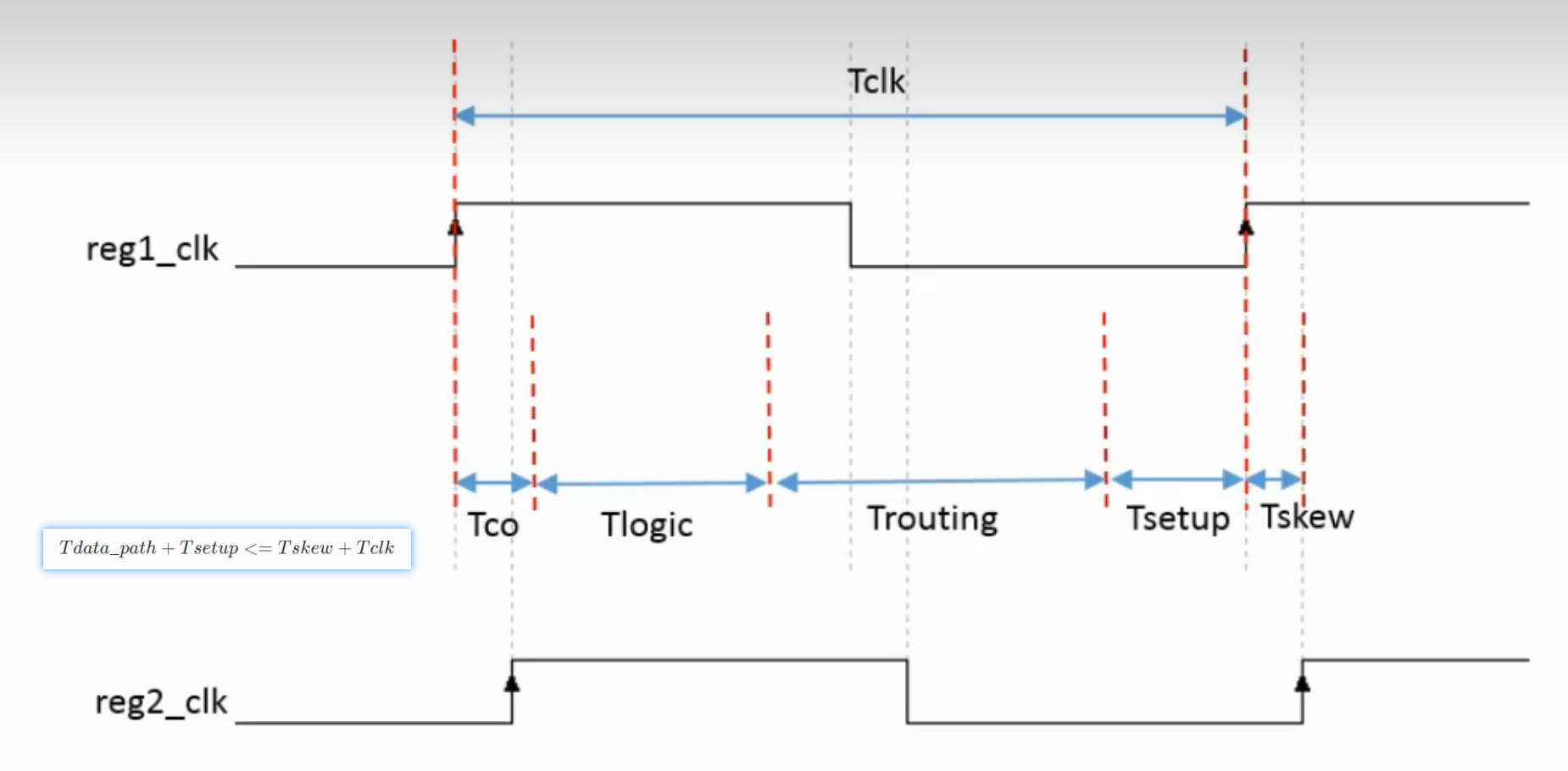

Tlogic和代码风格有很大关系,Trouting和布局布线的策略有很大关系。
- 如果两个时钟周期不一样,这里的$T_{period}$可以看作$T_{launch}$和$T_{capture}$之间的时间可以看这里解释 但是一般都将其视为异步时钟,做跨时钟域处理
- 在测试验证的时候,要检查setup违例,可以降低时钟频率来看


复杂时钟树约束过程这里是参考视频
多个时钟输入约束过程:
- 首先是create多个输入,然后设定他的uncertainty
- 其次对mux的多个时钟输入声明创建两个时钟,并表征这两个时钟不会同时出现(set_clock_groups -logically_exclusive),这样工具就不会去考虑一些没有用的东西
- 对输入是-logically_exclusive不会同时存在进来,对输出是-physically_exclusive在物理上不会有相互影响(电线之间的互相影响)
- 在后续的MUX上的输入,也就是前一项的输出需要用create_generated_clock来引出,进一步完成set_clock_groups、分频以及占空比的设计(-edge {1 3 7})
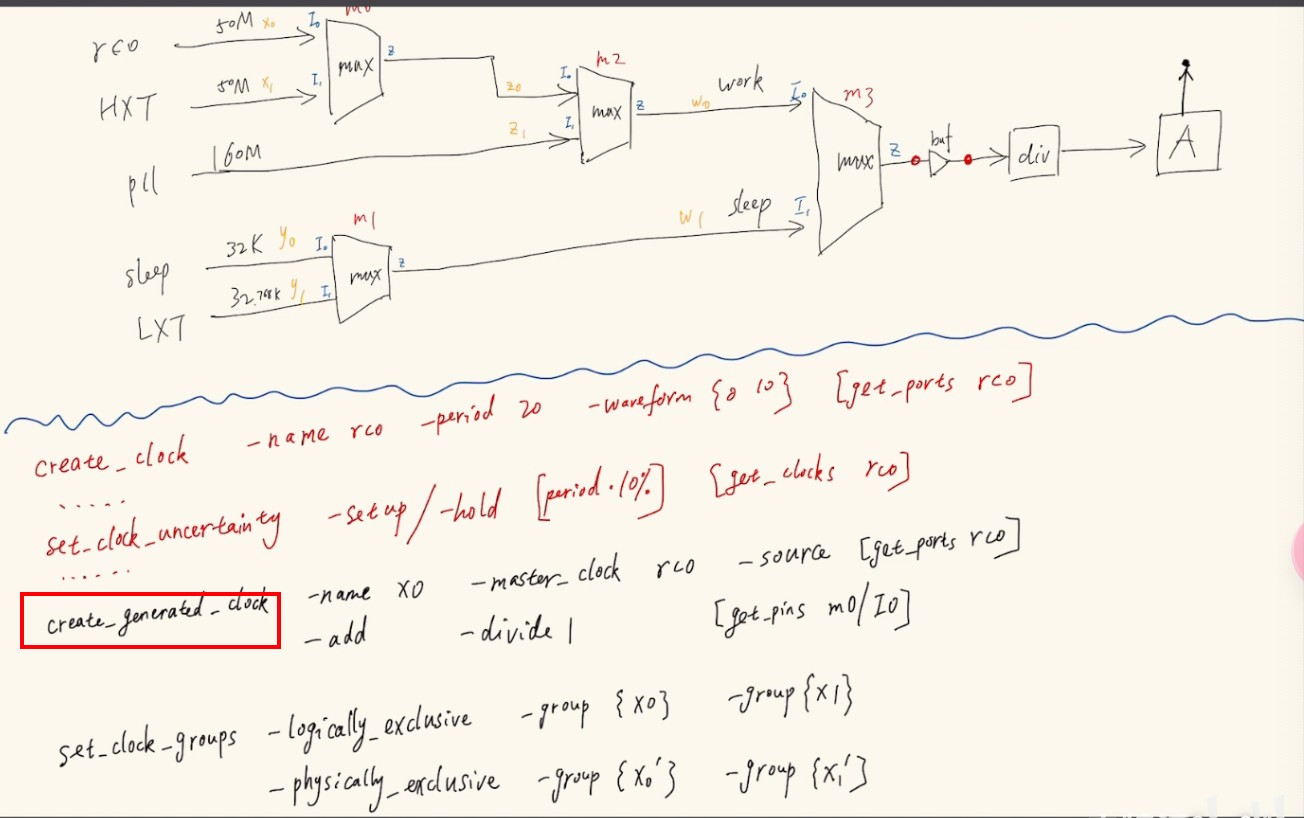
- 同一时钟源产生的时钟(x0和a0,两者默认为同步信号),用到驱动两个不同的模块。需要告诉工具两者之间没有关系(异步信号)

- clock balance:同一时钟到达两个寄存器的时间不一样,所以需要在某个路径上插buffer保证两条路的延时是一样的(当两个寄存器的输出有关系的时候才需要,否则可以不考虑)
一般我们不在综合阶段对复位树进行构建,在PR布局布线的时候再考虑
- 在CDC打拍设计的时序约束,需要在第一个寄存器和第二个寄存器之间设置false_path 在第二个和第三个之间设置max_delay
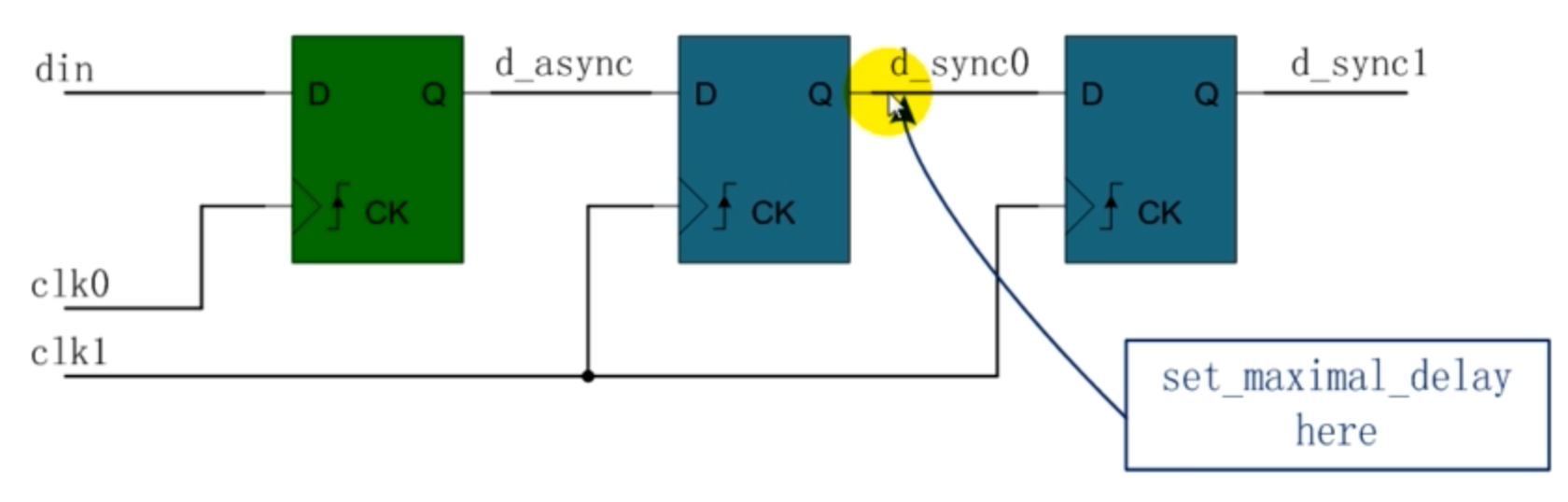
关于input和output delay的讲解
STA的一些思考
- (1)STA setup/hold time可以是负数么?
- 工作原理上存在的原因 以reg2reg为例(上升沿触发)假设时钟上升沿到达CK pin之后数据并不是被立即触发,这里存在一段延迟时间Dd,
则RT = T + Dclks + Dd - setup =T+Dclks + (Dd - setup)=T+Dclks - (-Dd + setup)
当Dd大于setup的时候 (-Dd + setup)就是负值了,假如我们在 FF 的内部,clock 路径上加一个 buffer,buffer 的延迟是 0.4ns,那么这个时候 setup time 便会是 -0.2ns。
setup的真实值不会是负值,这里的负值setup(-Dd+setup)已经不再是原来意义上的setup了。意义:当 setup time 为负数时,这意味着信号可以在时钟有效沿一段时间(setup time)之后再开始维持稳定,这意味着 data path 的延迟可以增加,timing 更好 closure
- (2)
set_timing_derate -early 0.8set_timing_derate —late 1.1都有什么用?
为了给OCV(片上偏差)留出一定的裕度,-late会在计算setup的时候,给arrive的path增大0.1,而捕获的路径减少0.1(让数据更晚来,时钟更早来)。反之hold也是同理。
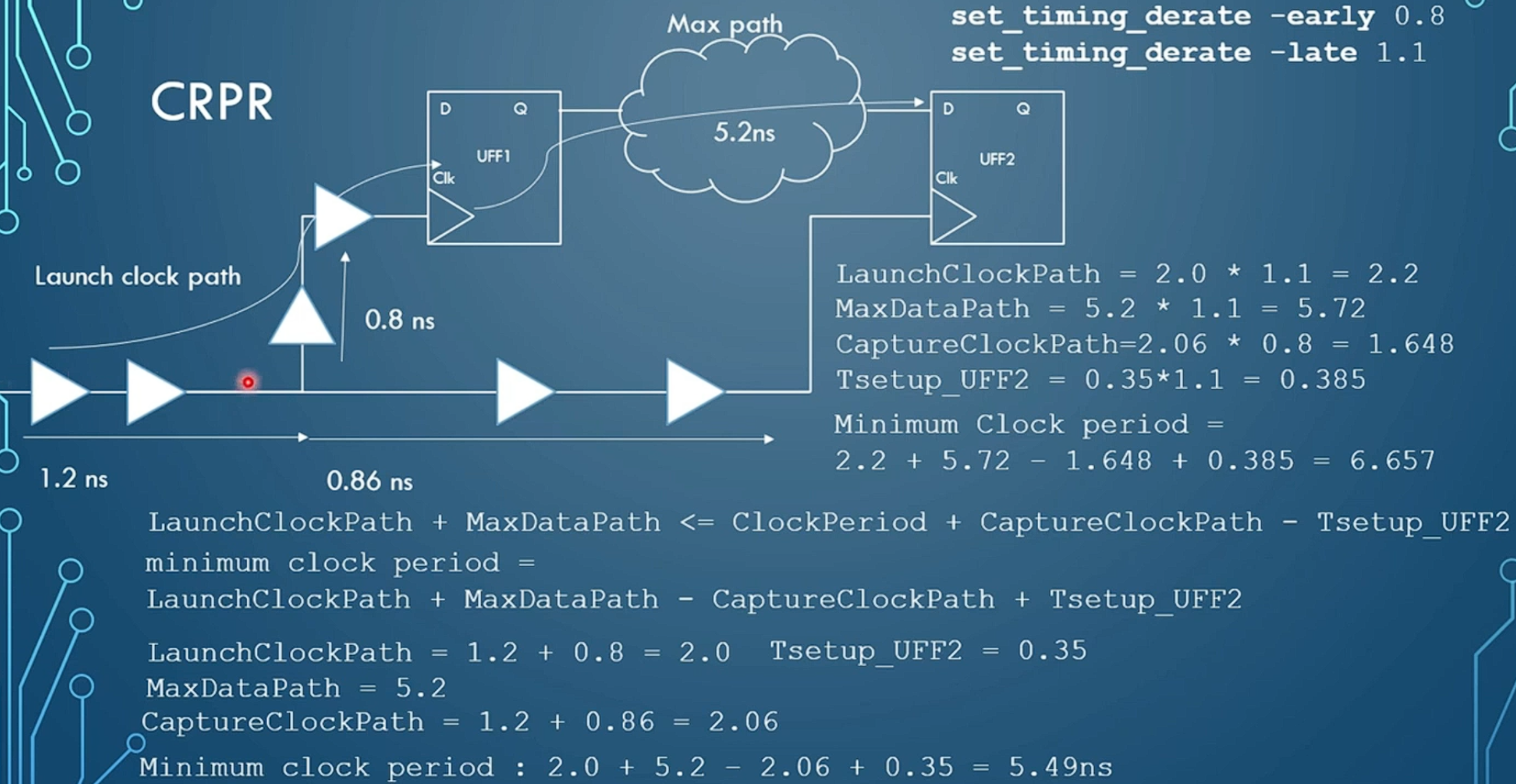
CRPR(Clock Reconvergence Pessimism Removel Concept)
- (3)使用virtual clock的原因在接口时序约束中为什么设置虚拟时钟
用于input_delay & output_delay,假设模块内的寄存器A输出到输出端口,该端口被外部的寄存器B捕获。如果我们参考clock_in本身指定output delay,就无法指定到达触发器(Reg-B)的clock latency。因为如果我们指定clock_in的延迟,则它也对Reg-A起作用。会导致output port约束变得更悲观。同理,会导致input port约束变得更乐观。
- (4)skew有时候可以修setup的原理? 在该数据路径的后续路径上,如果存在时序裕量,可以借用裕量来实现满足setup。(时钟晚到ff2,fix ff1->ff2 setup, ff3的数据来的更晚但是meet timing ),但是同时也要保证skew不能过大,因为在hold中要保证$T_d+T_{cq}>T_{hold}+skew$
二、跨时钟域
跨时钟域的数据同步主要可以分为:
单比特以及多比特数据(握手或者异步fifo)的处理。
FIFO
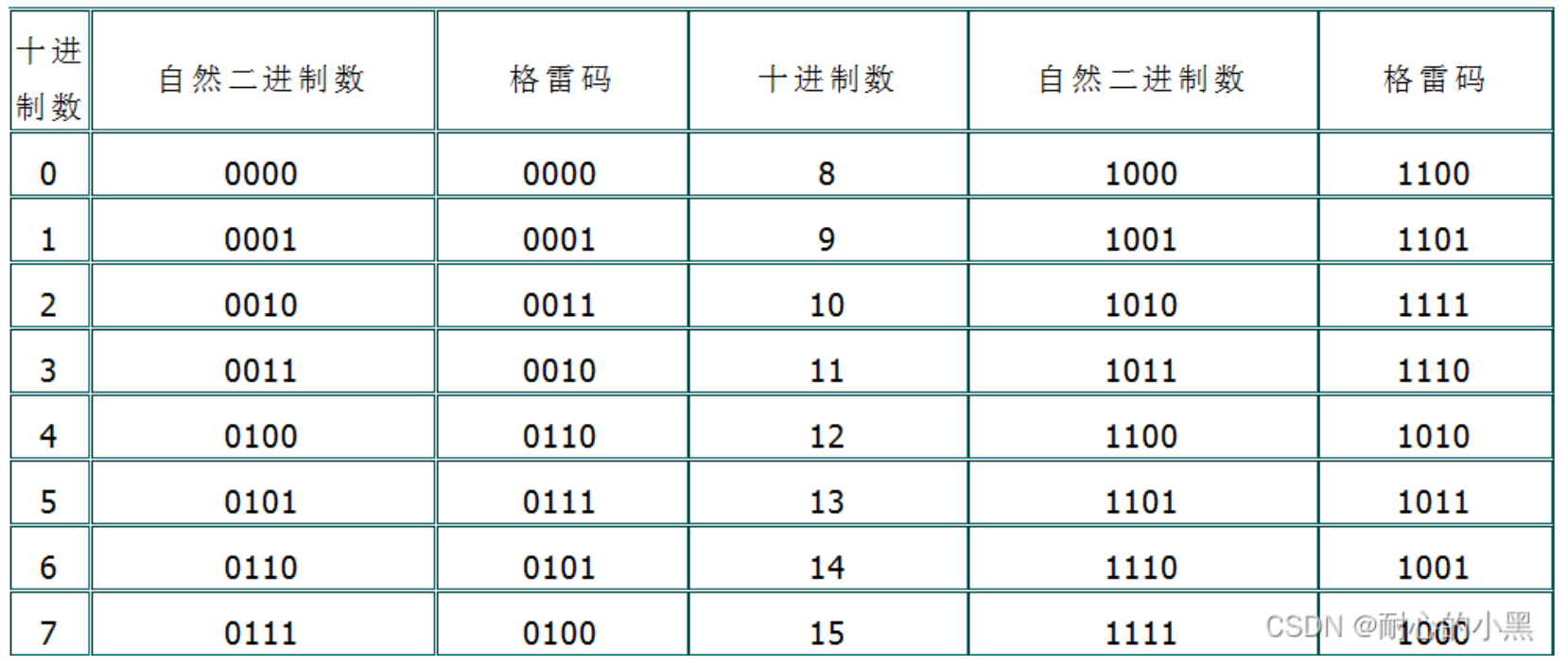
- 关于异步fifo深度计算
- 关于异步fifo的补充:(异步fifo用ip,不要自己写。sky讲过一个关于fifo深度的计算方法,另外格雷码只要在2N偶数的范围内就可以,不需要2^N。但深度可以是任意值)也就是说我们只要保证前后去除相同数量的格雷码就可以
异步fifo格雷码空满判断:
判断读空时:需要读时钟域的格雷码 rgray_next 和被同步到读时钟域的写 指针rd2_wp每一位完全相同。
判断写满时:需要写时钟域的格雷码 wgray_next 和被同步到写时钟域的读 指针wr2_rp高两位不相同,其余各位完全相同。
fifo的深度:
//---------------------- 对于同步fifo -----------------------//
每100个cycle可以写入80个数据(20cycle空闲),每10个cycle可以读出8个数据
最极端的情况:空闲—Burst突发—Burst突发—空闲—Burst突发—空闲 这样的背靠背传输
也就是说只要考虑160个cycle,FIFO_DEPTH = 160 - 160 * (8/10) = 32
//---------------------- 对于异步fifo -----------------------//
写时钟频率w_clk,读时钟频率r_clk
写时钟周期里,每B个时钟周期会有A个数据写入 读时钟周期里,每Y个时钟周期会有X个数据读出
这里主要从A计算出burst_length
fifo_depth = burst_length - burst_length * X/Y * r_clk/w_clk
fifo的sdc约束:跨时钟域的异步信号可以使用set_clock_groups,但这两种约束方式将会导致跨时钟域的信号完全没有受到约束,所以需要max_delay,涉及到 :
- 读地址(格雷码)寄存器Clock端口—写时钟域的同步寄存器的d端口
- 写地址(格雷码)寄存器Clock端口—读时钟域的同步寄存器的d端口
- 从格雷码寄存器的时钟端口—-> 另一个时钟域的读取输入端口,set_max_delay可设置为读写时钟中最快时钟周期的一半,也可以设置成源端时钟的一半,或者设置成源端时钟的倍数且bit间的skew明显小于一个源端时钟周期。
- **为什么要设置读写地址格雷码的max_delay?**
- 格雷码各bit位延时不一致—导致同步器采样的地址不符合gray规律,afifo功能异常。
- 格雷码到同步器的延时有好多个周期—-异步afifo性能下降
不写约束会造成:
- 格雷码各bit位延时不一致—导致同步器采样的地址不符合gray规律,afifo功能异常。
- 格雷码到同步器的延时有好多个周期—-异步afifo性能下降
电平和脉冲
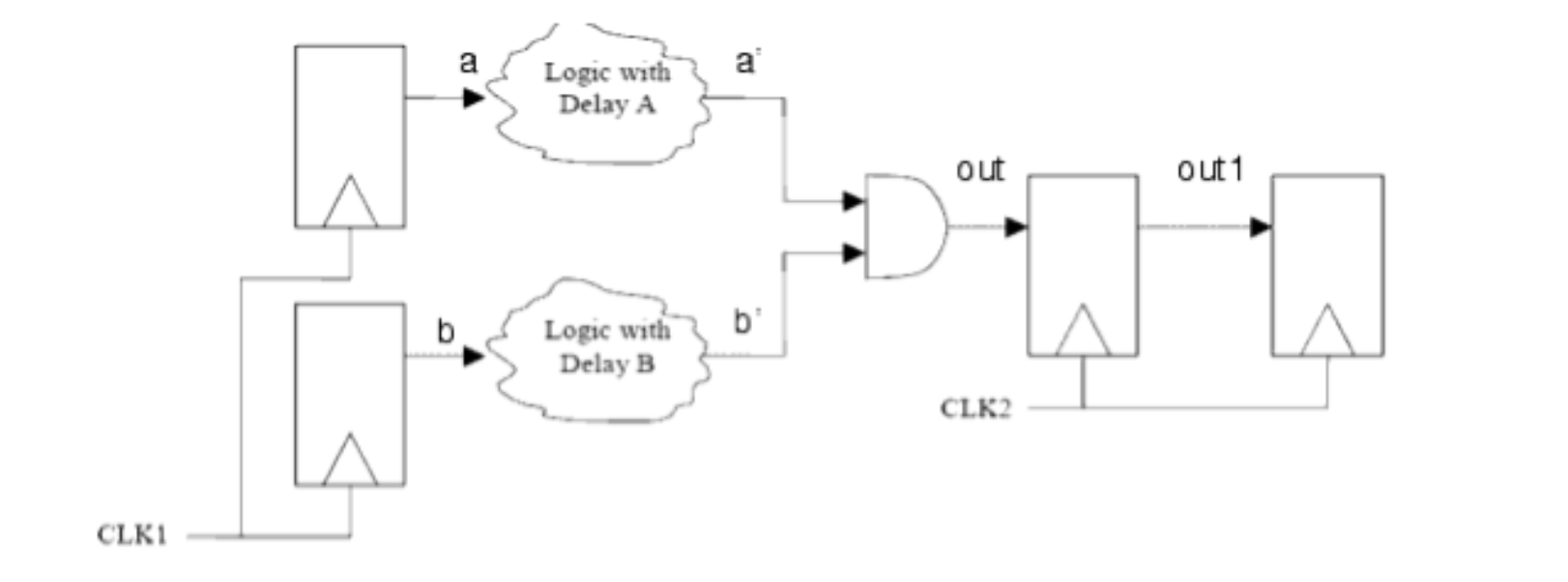
- 慢时钟域同步到快时钟域和从快时钟域同步到慢时钟域,
- 电平同步和脉冲同步,电平同步是:同步后的信号至少在目的时钟域维持两个及两个以上的高(低)电平;而脉冲同步则是同步后的信号在目的时钟域维持一个时钟周期。
注意同步到另一个时钟的信号不能经过组合逻辑,多路跨时钟信号通过组合逻辑进入同步器,这会导致源时钟域的glitch 传递到目标时钟域
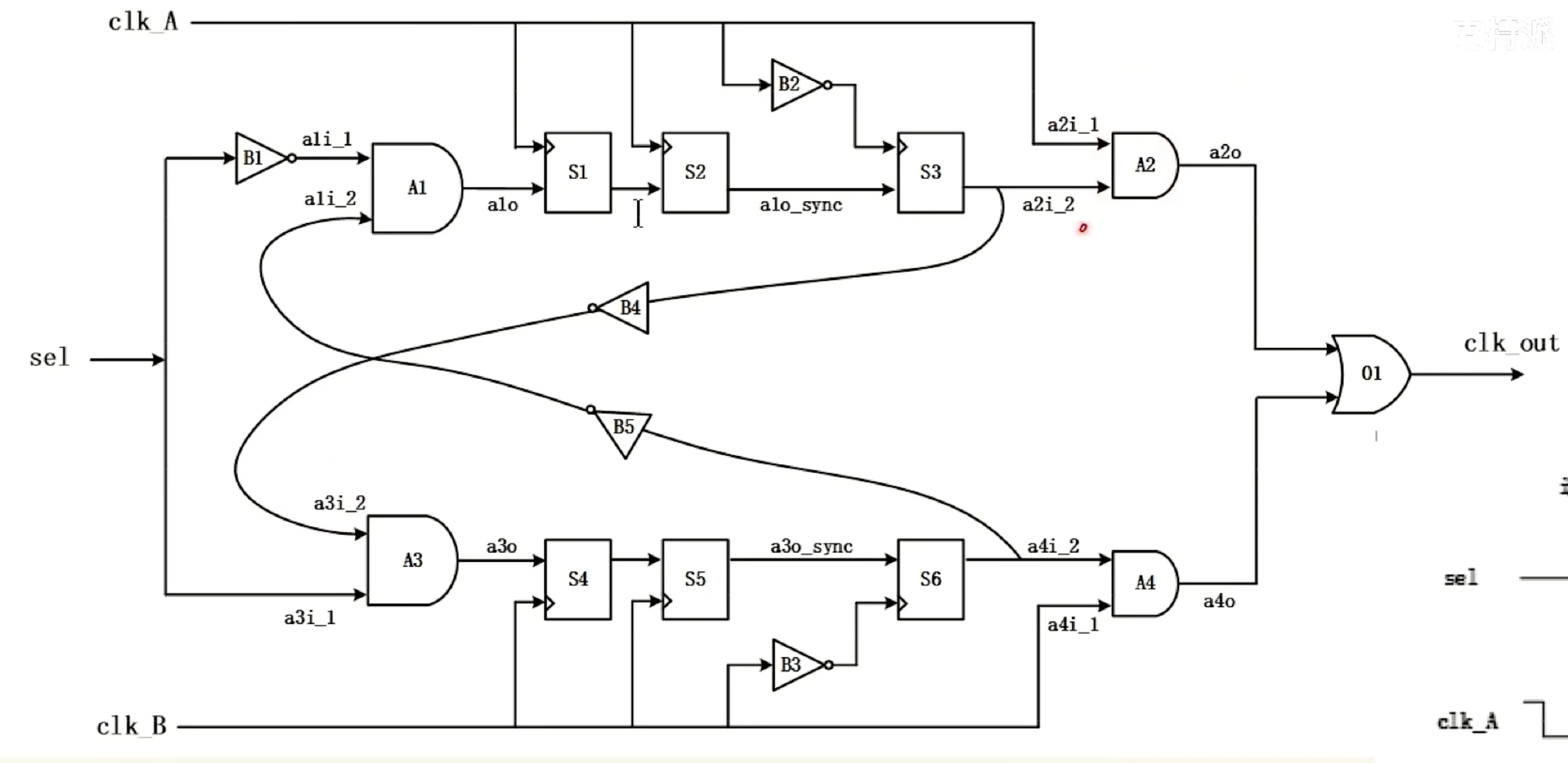
握手与反压
简单来说就是当AXI的master、slave这一族信号出现setup违例时: 需要打拍的信号间存在时序的耦合,所以需要在打拍的同时处理valid-ready协议。也就是在下图的中间两个空白处打拍
下面是通用的低频脉冲,转电平信号,双向握手,clk1和clk2可以任意谁快谁慢,通用
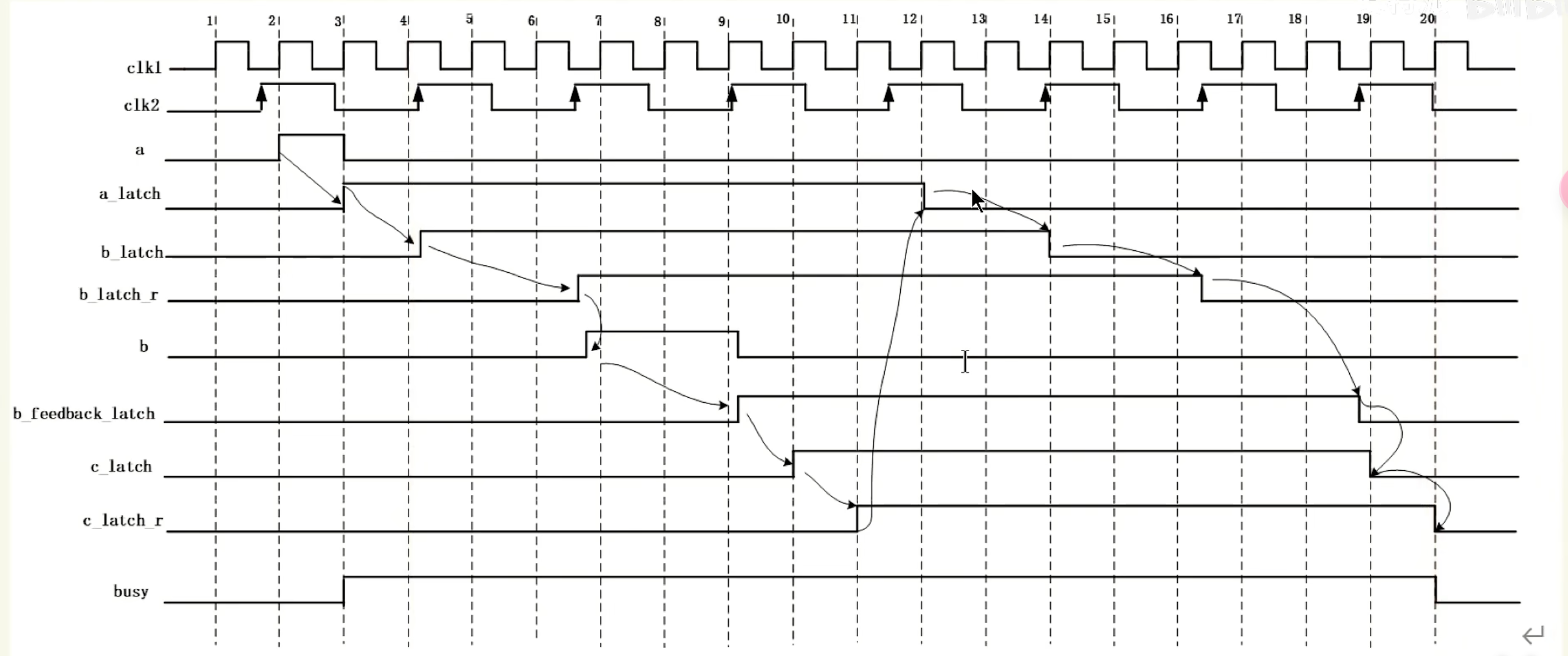
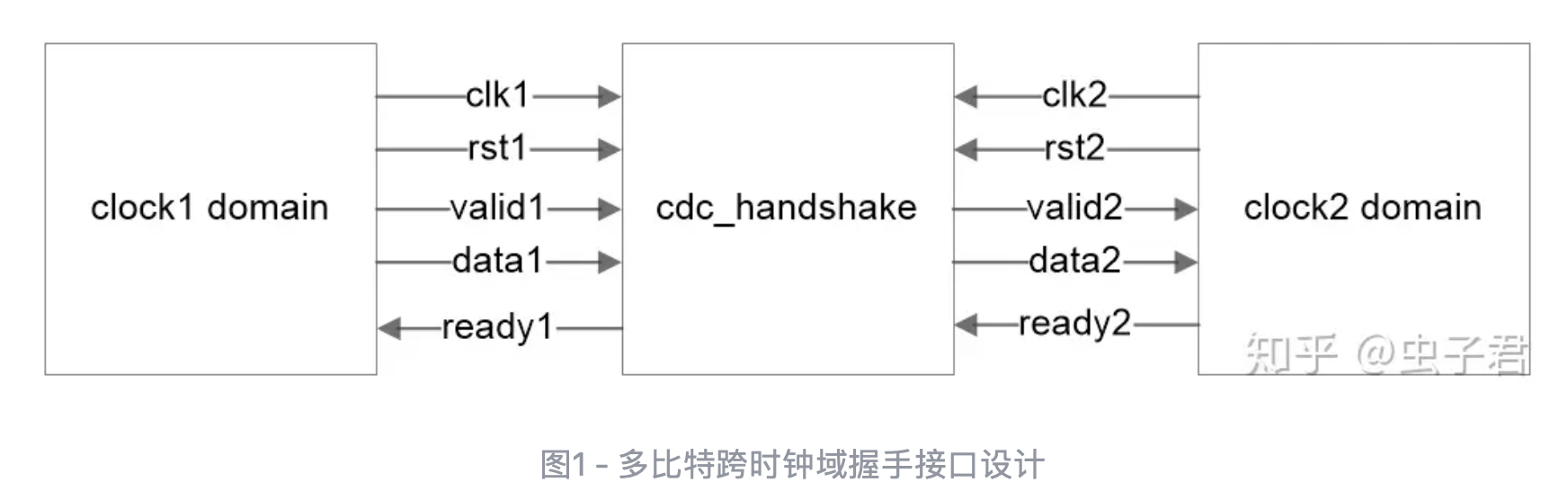
握手信号valid/ready的打拍技巧(slice)
当流水线的级数较多时,ready(通常是接收端通过组合逻辑输出的)反压信号一级一级往前传递,时序将会变得更差。其中打拍的三种方法:
- Forward Register Slice:仅处理valid和data信号的打拍
- Backward Register Slice:仅处理ready信号的打拍
- Full Register Slice:同时处理valid信号与ready信号的打拍
skidbuffer 我觉得这里的skidbuffer没有Backward Registered清晰,但其实两者的概念是一致的
Forward Registered
1
2
3
4
5
6
7
8
9
10
11
1️⃣
else if(valid_src) //将valid_dst一直latch到dst握手成功。
//也可以在(valid_src == 1'd1 && ready_src == 1'd0)时进行赋值,因为此时payload_src输入应该约束保持原始数据。
valid_dst <= #`DLY 1'd1;
else if(ready_dst == 1'd1)
valid_dst <= #`DLY 1'd0;
2️⃣
else if(valid_src && ready_src )
payload_dst <= #`DLY payload_src;
3️⃣
assign ready_src = (~valid_dst) | ready_dst //这里的意思是,下游即使不可以收数据,由于寄存器的存在,也可以收一拍数据
- Backward Registered
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
always @(posedge clk or negedge rst_n)begin//将valid一直latch到dst握手成功。
if(rst_n == 1'd0) valid_tmp0 <= 1'd0;
else if(valid_src == 1'd1 && ready_dst == 1'd0 &&valid_tmp0 == 1'd0)
valid_tmp0 <= #`DLY 1'd1;
else if(ready_dst == 1'd1)
valid_tmp0 <= #`DLY 1'd0;
end
always @(posedge clk or negedge rst_n)begin
if(rst_n == 1'd0) payload_tmp0 <= 'd0;
else if(valid_src==1'd1 && ready_dst==1'd0 &&valid_tmp0==1'd0)
payload_tmp0 <= #`DLY payload_src;
end
assign payload_dst = (valid_tmp0 == 1'd1) ?payload_tmp0 : payload_src;
// 对ready通路直接进行打拍
always @(posedge clk or negedge rst_n)begin
if(rst_n == 1'd0) ready_src <= 1'd0;
else ready_src <= #`DLY ready_dst;
end
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//这是看到的另一个方法:https://zhuanlan.zhihu.com/p/578660413,我没仔细看
assign kick_off = src_vld & src_rdy;
DFFRE(.clk(clk), .rst_n(rst_n), .en(kick_off & (!dst_rdy)), .d(src_pld), .q(pld_tmp));
assign dst_vld = src_rdy ? src_vld : 1'b1 ;
assign dst_pld = src_rdy ? src_pld : pld_tmp;
always @(***)
if(!rst_n)
src_rdy <= 1'b1;
else if (kick_off & !dst_rdy)
src_rdy <= 1'b0;
else if (!src_rdy & dst_rdy)
src_rdy <= 1'b1;
//src_rdy默认有效,此时若src valid并且发pld,则直接挂到dst端口上。dst端可以当拍取pld使用。
//但是如果dst端没rdy,则先将pld暂存到pld_tmp,下一拍要关闭src_rdy,这样src不能再更新pld过来。
//下一拍开始pld_tmp会挂到dst端口上。直到等dst_rs_rdy,表示dst端可以了,rs_src_rdy恢复开启,src端更新新的data送达。
- *Fully Registered
用fifo解决,使用非空信号做valid_dst;payload的非满信号做ready_src
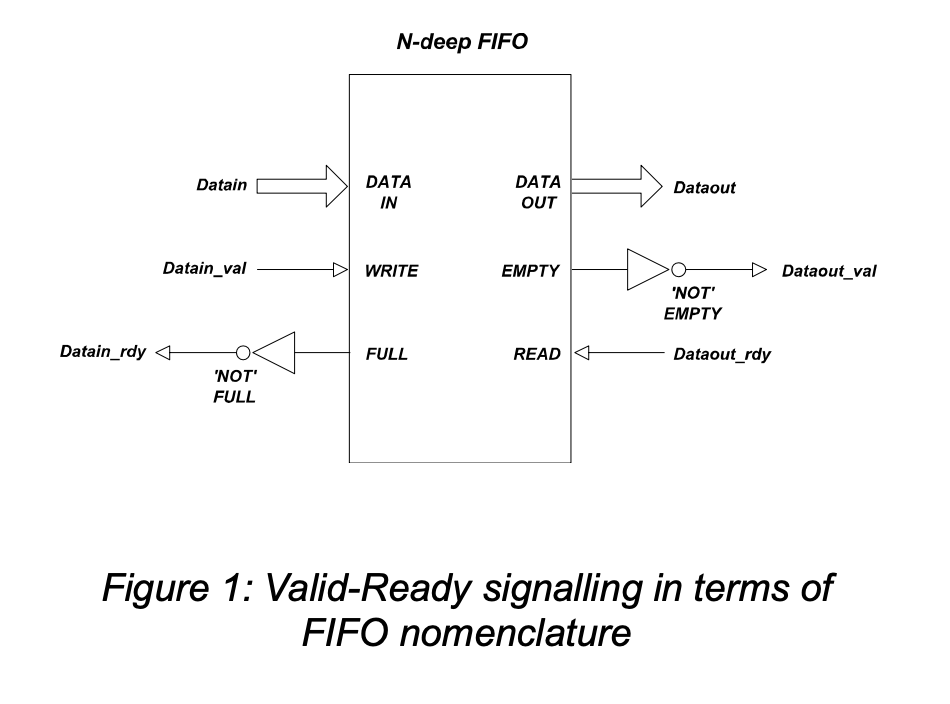
- 1V多或者多V1的情况握手打拍:看这个文章
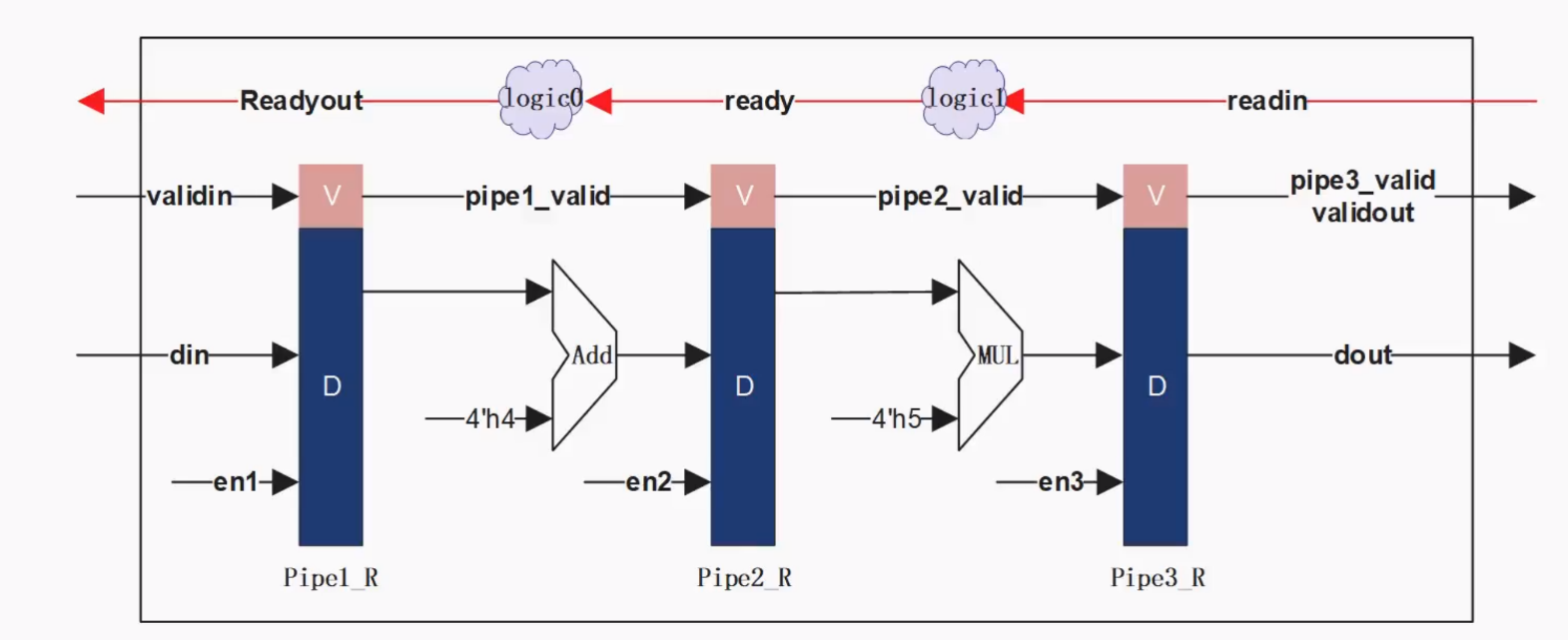
valid-ready的pipeline
这里Add需要1cycle,Mul需要3个cycle,用这个case来展示ready的反压设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
// Slave interface input
input valid_i;
input [31:0] data_i;
output ready_o;
input ready_i;
output valid_o;
output [31:0] data_o;
//================ Pipeline 1 stage ================
assign pipe1_done = 1'b1; //only need 1 cycle
assign pipe1_ready = !pipe1_valid || pipe1_done && pipe2_ready;
//pipe1内部没有数据;或者是pipe2_ready反压过来且pipe1已经完成了运算
assign pipe1_2_pipe2_valid = pipe1_valid & pipe1_done;
always @(posedge clk or negedge rstn)begin
if(!rstn)
pipe1_valid <= 1'b0;
else if (pipel_ready)
pipe1_valid <= valid_i;
end
always @(posedge clk or negedge rstn)begin
if (!rstn)
pipe1_data <= 32'h0;
else if(valid_i && pipe1_ready)
pipe1_data <= data_i;
end
//================ Pipeline 2 stage ================
assign pipe2_done = mul_done[2];
assign pipe2_ready = !pipe2_valid || pipe2_done && pipe3_ready;
assign pipe2_2_pipe3_valid = pipe2_valid && pipe2_done;
assign mul_result = pipe2_data * 4'h5;
always @(posedge clk or negedge rstn)begin
if(!rstn)
mul_done <= 3'b000;
else if(pipe2_ready && pipe1_2_pipe2_valid)
mul_done <= 3'b000;
else if(pipe2_valid)
mul_done <= {mul_done[1:0],1'b1};
end
always @(posedge clk or negedge rstn)begin
if(!rstn)
pipe2_valid <= 1'b0;
else if (pipe2_ready)
pipe2_valid <= pipe1_2_pipe2_valid;
end
always @(posedge clk or negedge rstn)begin
if(!rstn)
pipe2_data <= 32'h0;
else if(pipe2_ready && pipe1_2_pipe2_valid)
pipe2_data <= pipel_data + 4'h4;
end
//================ Pipeline 3 stage ================
assign pipe3_done = 1'b1;
assign pipe3_ready = !pipe3_valid || pipe3_done && ready_i;
always @(posedge clk or negedge rstn)begin
if(!rstn)
pipe3_valid <= 1'b0;
else if (pipe3_ready)
pipe3_valid <= pipe2_2_pipe3_valid;
end
always @(posedge clk or negedge rstn)begin
if(!rstn)
pipe3_data <= 32'h0;
else if(pipe3_ready && pipe2_2_pipe3_valid)
pipe3_data <= mul_result;
end
assign valid_o = pipe3_valid;
assign data_o = pipe3_data;
assign ready_o = pipe1_ready;
D2D 重传机制
TxLinkLayer
在数据链路层TxLinkLayer接受RxLinkLayer传来的rx2TxPackageIDUsed和rx2TxPackageIDOut
其中rx2TxPackageIDUsed用来更新内部packageTmpId、replayState、replayQ,用来驱动重传状态
以及rx2TxPackageIDOut用来更新内部replayPkgIDReg、replayPkgIDOutReg从而串行输出给Phy的replayPkgID接口,指定现在传输的pkgID
RxLinkLayer
在数据链路层RxLinkLayer输出rx2TxPackageIDUsed和rx2TxPackageIDOut
其中rx2TxPackageIDUsed由串行输入的Phy接口replayPkgID拼接驱动
rx2TxPackageIDOut的驱动逻辑如下:指定下一个传输的pkgID
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//pkgIdOut是解析传过来的数据包中的packetId字段
pkgIdCorrect := (dataOutValid && pkgIdOut === (lastCorrectPkgID + 1.U))
dataCorrect := crcCorrect && pkgIdCorrect
when(dataOutValid && dataCorrect){
lastCorrectPkgID := lastCorrectPkgID + 1.U
io.rx2TxPackageIDOut.valid := true.B
io.rx2TxPackageIDOut.bits := pkgIdOut
}.elsewhen(dataOutValid && !dataCorrect){
lastCorrectPkgID := lastCorrectPkgID
io.rx2TxPackageIDOut.valid := true.B
io.rx2TxPackageIDOut.bits := lastCorrectPkgID
}.otherwise{
lastCorrectPkgID := lastCorrectPkgID
io.rx2TxPackageIDOut.valid := false.B
io.rx2TxPackageIDOut.bits := 0.U
}
重传包存储机制
存在两个fifo,所以存在三种传输情况
- 绝大多数情况:无error发送,数据正常传输,每次传输都会将包临时存储在第一级fifo中,直到收到传输成功信号,释放第一级fifo中的包。
- 第一级fifo传输出现error,那么此时replayState会被拉高,包会再次发送,同时临时存储在第二级fifo中。此时如果传输成功,第二级释放。如果传输失败,出现第三种情况
- 此时可以看作第二级fifo传输失败,数据会被挪到第一级fifo种继续发送
为了防止死锁(一直在持续发送第二级fifo中的包,当计数到达上限,就默认视作发送失败,挪回第一级fifo)