编译器+AI
编译器+AI
1. llama.cpp
1
2
3
4
5
6
7
8
9
10
11
12
typedef struct llama_batch {
int32_t n_tokens;
llama_token * token;
float * embd;
llama_pos * pos;
int32_t * n_seq_id; //共享于多少个序列
llama_seq_id ** seq_id;//共享序列的id
int8_t * logits; // TODO: rename this to "output"
} llama_batch;
int llama_context::decode(const llama_batch & batch_inp)将llama_ubatch送进ggml计算图执行的入口为
const auto res = process_ubatch(ubatch, LLM_GRAPH_TYPE_DECODER, mstate.get(), status);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//output mappings
for (int64_t i = 0; i < n_outputs; ++i) {
int64_t out_id = out_ids[i];
output_ids[out_id] = i;
if (out_id != i) {
sorted_output = false;
}
}
假设一个批次只有 4 个需要输出的 token,原始索引为 0,1,2,3,但经过微批处理后 out_ids = [2,0,3,1],循环执行后:
- output_ids[2] = 0
- output_ids[0] = 1
- output_ids[3] = 2
- output_ids[1] = 3
因此 output_ids 变成 [1,3,0,2]:例如用户想读取原始索引 3 的 logits,只要查 output_ids[3] 得到 2,就知道应该从输出缓冲的第 2 行取值。
现在我的编译器需要兼容多cu的场景 那么现在需要解决node_id的问题,所以需要额外添加一个dma_offset_id, 因为refine_dump_data.coffee中是根据graph来进行的搜索,但我不想弄脏graph的json
2. 什么是TVM&LLVM
https://github.com/WuDan0399/Integrate-NVDLA-and-TVM.git
- TVM可以将高层次的(TensorFlow、PyTorch 等等模型)转换为高效的中间表示(IR),然后进一步优化和编译成特定硬件(如 CPU、GPU、TPU)的可执行代码,TVM使用LLVM作为其后端编译器之一。通过LLVM,TVM可以将中间表示(IR)进一步优化和编译成目标机器代码,从而支持多种CPU和GPU架构。LLVM的优化功能也有助于提高生成代码的运行性能
- LLVM (Low Level Virtual Machine)提供了一套编译器前端和后端的基础设施,可以将高级语言(如C、C++)的源代码编译成中间表示(IR),然后进一步优化并生成目标机器代码(如x86、ARM等)
TVM允许你定义算法和调度:


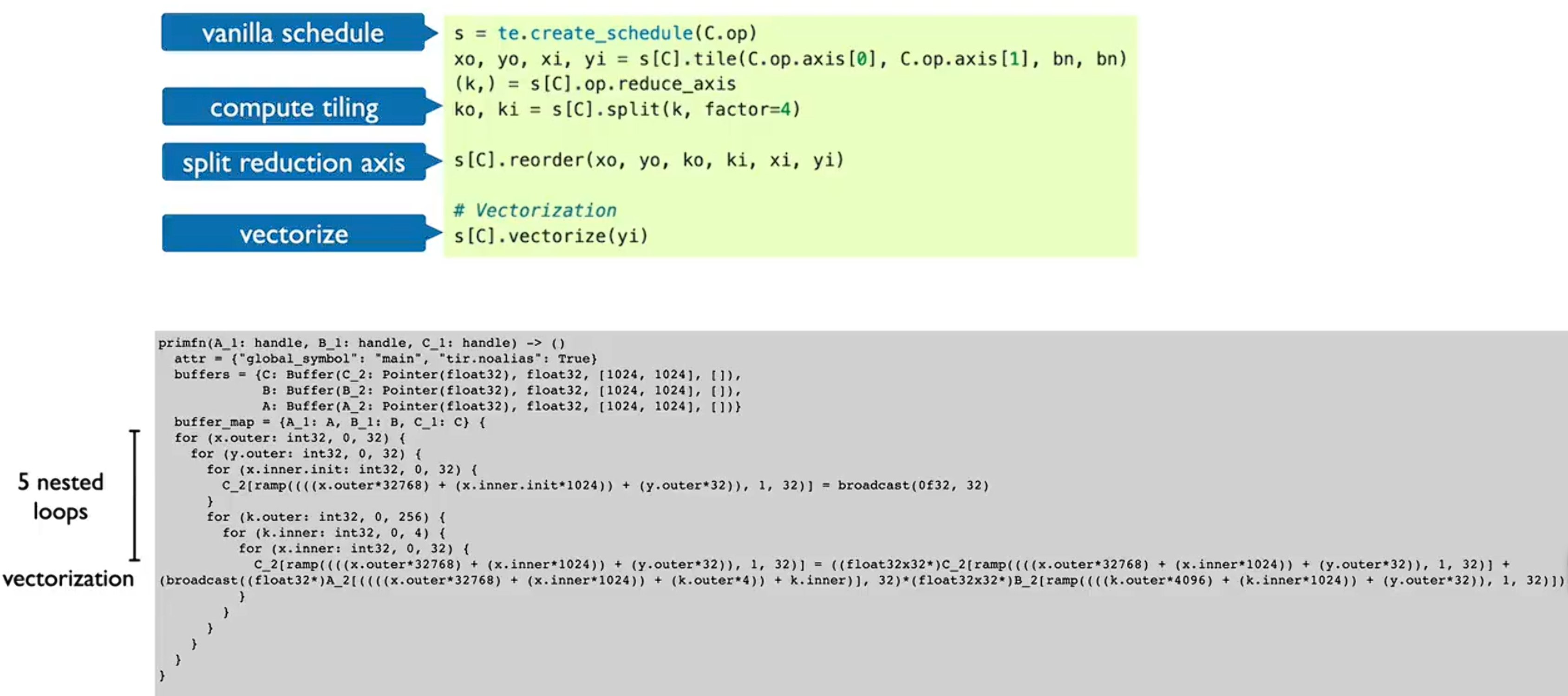
TODO
- /home/qluo/workspace/CIM-Accelerator-Compiler-based-on-TVM/tvm/tvm-for-cim/src/runtime/contrib/cim/cim_runtime.cc
- /home/qluo/workspace/CIM-Accelerator-Compiler-based-on-TVM/tvm/tvm-for-cim/src/relay/backend/contrib/codegen_c
x. gguf文件格式
GGML第三方工具作为llama.cpp的依赖,GGML源码阅读
gguf只有模型参数,没有模型结构

This post is licensed under CC BY 4.0 by the author.