AI互联
0、电路上的问题
serdes 铜缆信道损耗大,功耗高,带宽利用率低
并行的phy功耗低,但频率有限
一、模拟器仿真软件调研
- BookSim2 网络拓扑结构自由搭建;专注于交换机级别的网络层仿真(端到端的延迟、带宽、路由算法效率)
不包含AllReduce高层次的通信逻辑,算法需要你自己实现;
- SimAI SimAI 支持的主要运行模式:(1)SimAI-Analytical (2)SimAI-Simulation(NS-3) (3)SimAI-Physical(TODO)
包含(1)AICB (2)SimCCL (3)astra-sim-alibabacloud (4)ns-3-alibabacloud
1)SimAI-Analytical:SimAI-Analytical 通过直接指定 busbw 来抽象底层网络细节,以估算集体通信时间。目前busbw需要靠自己自定义
SimAI-Analytical 的设计目的在于:
性能分析 :比较不同模型的完成时间(例如,研究专家数量对 MoE 模型训练性能的影响)
框架级并行参数优化 :平衡 TP/EP/PP 参数,分析端到端时序效应
Scale-up和Scale-out带宽需求探索
1)AICB提供三种主要使用场景:
- Running on physical GPU clusters
- Generating workload descrption files for simulation
- Customized parameters.
- 记录真实训练时的通信计算耗时,参见文件aicb/scripts/megatron_workload_with_aiob.sh,会输出两个csv文件,
results/comm_logs/megatron_gpt_13B_8n_log.csv - Generate Workload for Simulation(SimAI),参见文件
./scripts/megatron_workload_with_aiob.sh. 模型的计算部分可以通过–aiob_enable 选择使用 aiob,不使用 aiob 时,使用默认的固定时间来填充 Workload。启用--aiob_enable时,如果不指定--comp_filepath,则会使用当前 GPU 的计算时间来填充 Workload - Run AICB with customized cases,目前运行自定义案例的入口文件是 aicb.py
二、一些概念
当将神经网络的训练并行化到许多GPU上时,我们关注一种称为数据并行随机梯度下降( SGD )的技术。 集群通信原语&NCCL
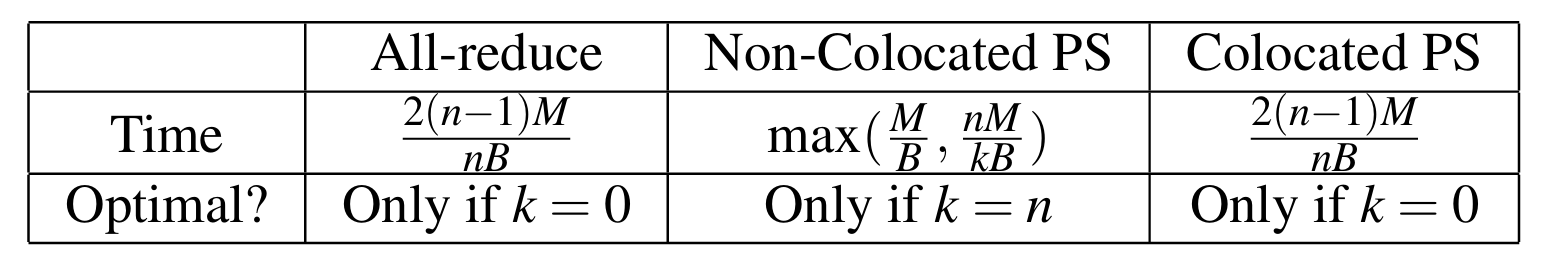
并行范式:
- 模型并行 :把一个完整的模型切分成若干部分,每个worker运行模型的不同部分,如果切分时能够做到不同部分没有依赖,能够独立运行,则可以并行运行不同部分而达到提高效率的目的
- 数据并行:每个worker都运行完整的模型,每个worker使用的数据不一样,训练时同一个模型参数在不同worker上的梯度就会不一样,因此数据并行在训练时会需要一个梯度的聚合机制 主流的有两种大的数据并行范式:PS和all-reduce
PS中主要有server和worker,server主要用于存储模型参数,并接收来自worker的梯度然后执行优化更新参数。不同的server一般会存储模型的不同部分参数;worker主要执行模型训练的前后向计算,将后向计算的梯度发送给server,并从server拉取最新的参数值。论文中把PS按照部署方式分成了两种方式:Non-colocate PS和Colocate PS。
- Non-colocate PS即server和worker是分开部署在不同的机器上的
1.1 NCCL互联方案
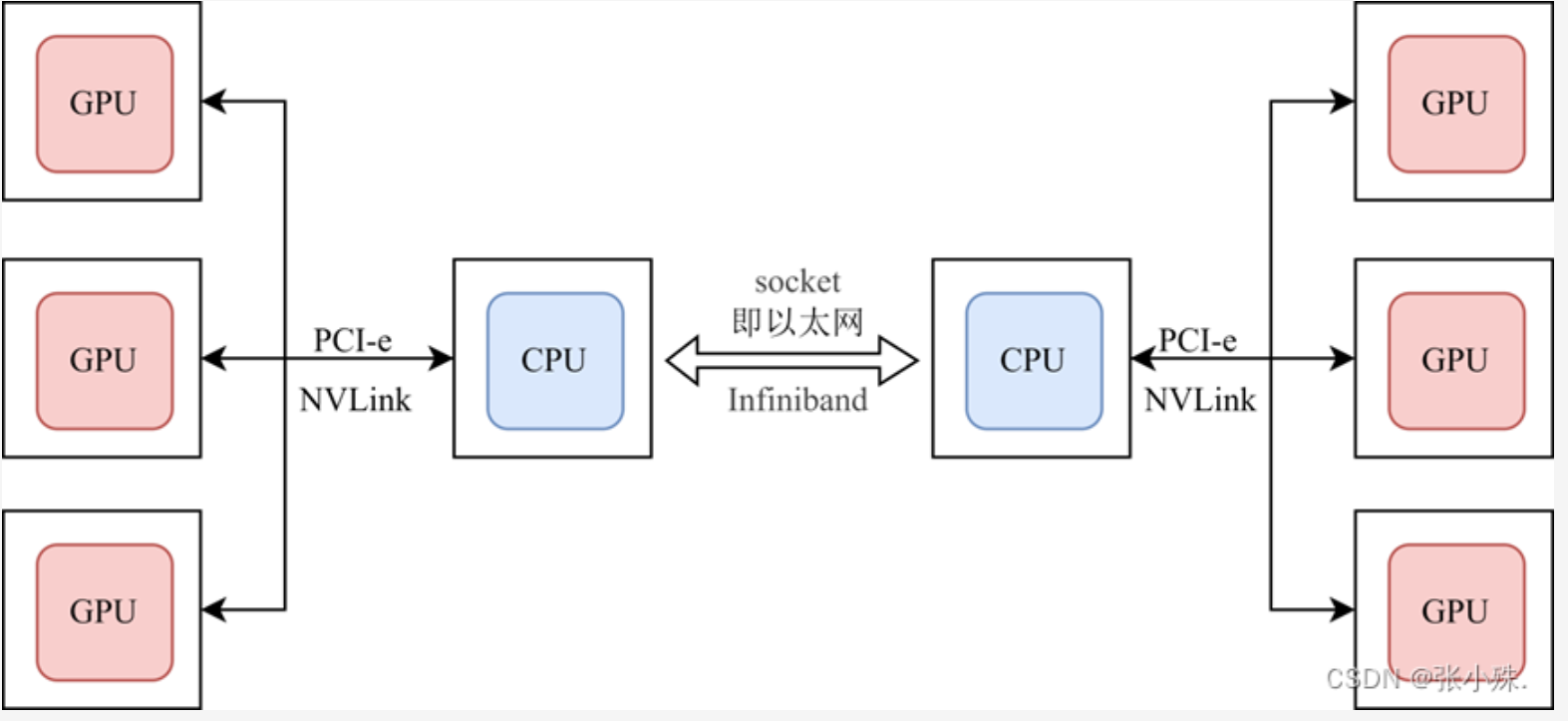
在常见的分布式训练加速设备中,常常是多节点多加速卡的形式,节点也可被称之为主机或CPU,加速卡的种类很多,常见的有GPU、DCU、FPGA等。如下图所示
- 在单节点多加速卡的情况下,节点和加速卡以及加速卡之间的数据通信依靠PCIe或NVLink实现
- 多节点多加速卡的情况下,节点之间的数据通信依靠
以太网或Infiniband实现。
在跨节点加速卡通信的过程中,往往需要先将加速卡的数据传输到相应节点的CPU上,然后CPU通过以太网传输数据,之后又将数据传给加速卡,这种数据在节点和加速卡之间频繁移动所造成的通信开销是很大的,鉴于此,英伟达公司发布了 GPU Direct技术,用于提高加速卡之间通信的效率。
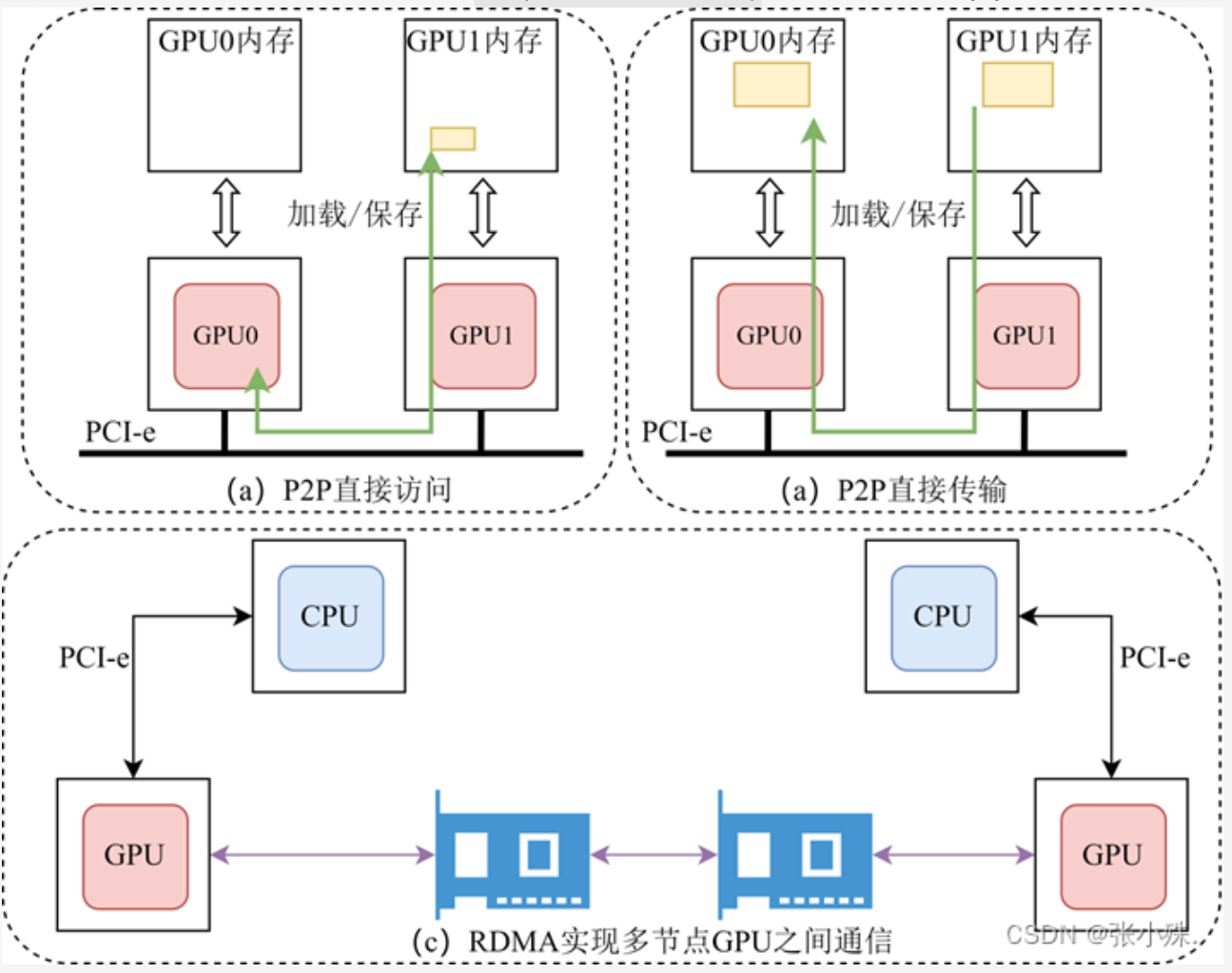
- 在单节点多加速卡通信中,提出
P2P(GPU Direct peer-to-peer)技术。如下图(a)(b)所示,它实现了节点内部加速卡的直接通信,即加速卡可以直接访问另一个加速卡的内存并实现数据的直接传输,避免了加速卡的数据复制到节点CPU内存上作为中转。 - 在多节点多加速卡通信中,提出了
GDR(GPU direct RDMA)技术,如下图(c)所示,加速卡和网卡可以直接通过PCIe进行数据交互,避免了跨节点通信过程中内存和CPU的参与。从而实现加速卡可以直接访问其他节点的加速卡内存。
1.2 通信原语Collective communication
- Reduce:从多个sender那里接收数据,最终combine到一个节点上面
- All-reduce:从多个sender那里接收数据,最终combine到每一个节点上面
- #传统的TCP/IP通信
- 数据发送方要将数据从
用户空间Buffer复制到内核空间的Socket Buffer中。 - 在
内核空间中添加数据报头,进行数据封装。通过一系列多层网络协议的数据包处理工作,这些协议包括传输控制协议(TCP)、用户数据报协议(UDP)、互联网协议(IP)、以及互联网控制消息协议(ICMP)等。经历如此多个步骤,数据才能被Push到NIC网卡中的Buffer进行网络传输 - 在消息接收方,从远程主机发送来的数据包,要先将其
从NIC Buffer拷贝至Socket Buffer - 经过一系列的多层网络协议对数据包进行解析,解析后的
数据被复制到相应的用户空间应用程序的Buffer中。此时,再进行系统上下文切换,用户应用程序才被调用。
- 数据发送方要将数据从
- #TCP/IP存在的问题
传统的TCP/IP网络通信是
通过内核发送消息. 需要在内核中频繁进行协议封装和解封操作,造成很大的数据移动和数据复制开销。RDMA提供了给基于IO的通道,这种通道允许一个应用程序通过RDMA设备对远程的虚拟内存进行直接的读写。 目前,有三种支持RDMA的通信技术:IB(InfiniBand)、以太网RoCE(RDMA over Converged Ethernet)、以太网iWARP(internet Wide Area RDMA Protocal).它们有着不同的物理层和链路层。
1.3 Allgather vs Alltoall
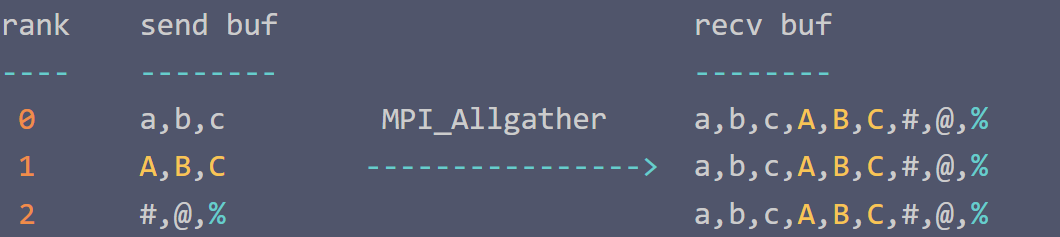
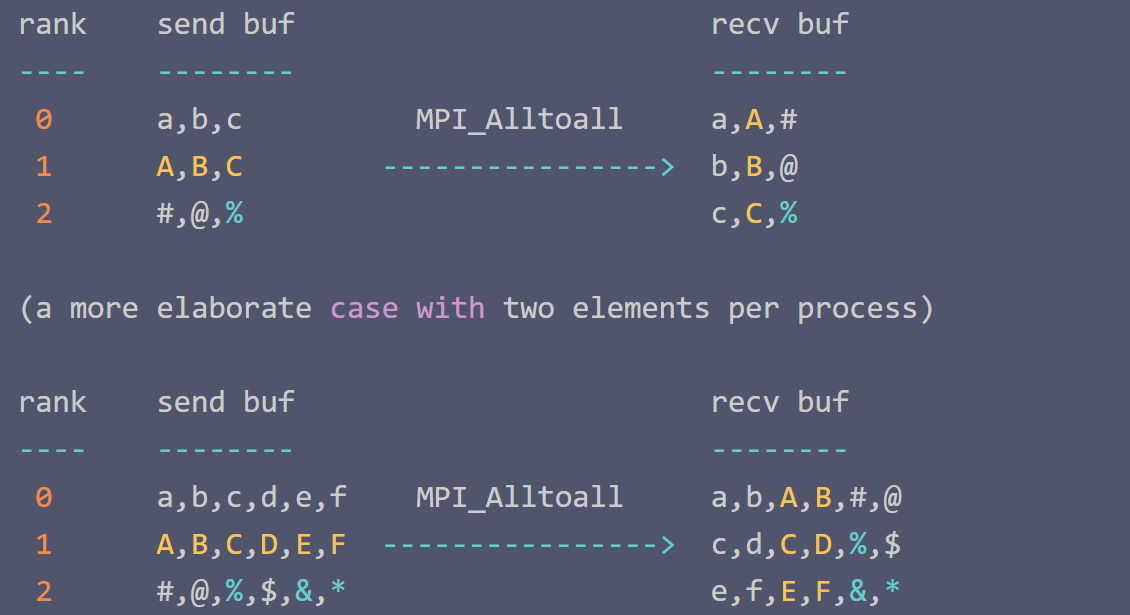
简单分析发送缓冲区中数据的大小和接收缓冲区中数据的大小:
1
2
3
4
operation send buf size recv buf size
--------- ------------- -------------
MPI_Allgather sendcnt n_procs * sendcnt
MPI_Alltoall n_procs * sendcnt n_procs * sendcnt
Ring算法在中等规模的运算中非常有优势,较小的传输数据量,无瓶颈,带宽完全利用起来。
缺点则是在大型规模集群运算中,巨大的服务器内数据,极长的Ring环,Ring的这种切分数据块的方式就不再占优势。
三、一些算法
#Halving-Doubling-AllReduce
该算法的优点是通信步骤较少,只有$2 * log2^N$次(其中N表示参与通信的节点数)通信即可完成,所以其有更低的延迟。相比之下Ring算法的通信步骤是2* (N-1)次;缺点是每一个步骤相互通信的节点均不相同,链接来回切换会带来额外开销。
拓扑结构
并行方式和通信需求
Allreduce=Reduce+BroadcastAllreduce=reduce-scatter+Allgather
- DP和TP:需要Allreduce
- MoE并行:需要All2All
PP:需要Send/Recv
- mesh让通信算法带来挑战
- ring能最大化利用带宽,节点内采用Nvlink,节点间采用IB/Ethernet
统计一下不同结构noc(mesh,torus,tree,buttfly,benes,ring)做reduce-satter和all gather的延时:
Double Binary Tree、Ring Reduce、2D-Torus Reduce、Butterfly Reduce 时间消耗
集合通信没有哪个算法是最优的,不同情况下表现不一样
假设每个节点上的数据Size是D,单向带宽为B;Node to Node传输1个byte的延迟为$\alpha$;
我总觉得比较起来不是很公平,因为物理上的端口是不一样的数量
- Double Binary Tree(NCCL 2.4之后都用DBT了,可以利用满双向带宽)√√√
- allreduce=reduce+broadcast;两棵树同时工作,在每一步中从父节点中收数据,并将上一步中收到的数据发送给子节点,在偶数步骤中使用红色边,奇数步骤中使用黑色边;
- 集群通信优化算法双二叉树及其构建,tree的问题在于,交换机带来的竞争;
- 朴素的树状 Reduce 带宽利用不充分,broadcast时叶节点只接收数据,不发送。reduce时叶节点只发送数据,不接收。Double Binary Tree 分别构造两棵树。Tree1和Tree2会同时运行,这样使得双向带宽能被同时利用
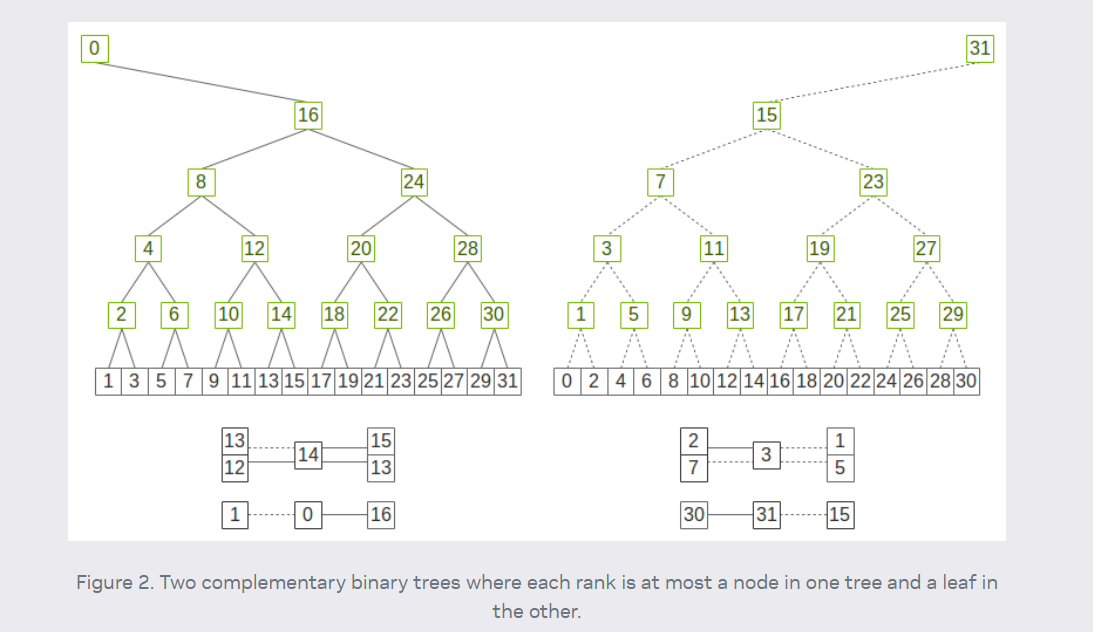
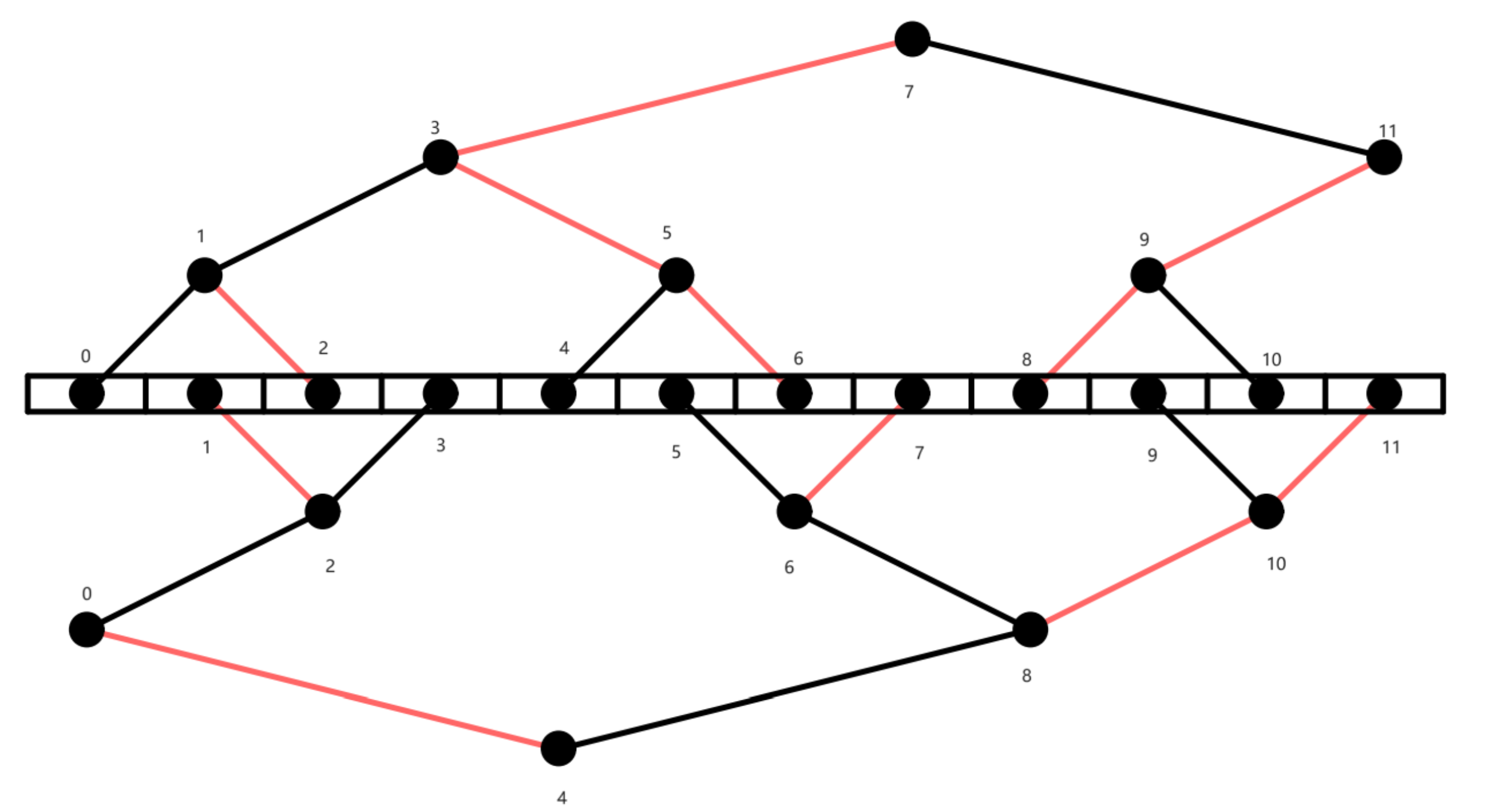
- Two-tree algorithms for full bandwidth broadcast, reduction and scan 论文
- 两棵树各处理一般的数据,先reduce后broadcast。reduce和broadcast通信时间均为:$log_2 N (\alpha +\frac{D}{2BW})$, (这里假设的是在物理上只有一个端口,所以两个输入需要仲裁等待,每个节点的发射耗时是(D/2)/B,总的时间还是D/B)。额外的computation cost为$\frac{D}{2}\log_2 N\gamma$
- Butterfly上按照RHD(Recursive Halving and Doubling)算法 √√√(一种假的crossbar)
- 通信次数 $2*\log_2 N$,缺点是每一个步骤相互通信的节点均不相同,链接来回切换引入额外开销,固定的TP并行度
- RHD每次通信数据量为$\frac{D}{2},\frac{D}{4},\frac{D}{8},…\frac{D}{N}$,通信总量为$D-\frac{D}{N}$
- reduce-scatter和allgather耗时均为:$\log_2 N * \alpha + \frac{D-\frac{D}{N}}{BW}$,额外的computation cost为$(D-\frac{D}{N})*\gamma$
- Ring√√√
- 通信次数 $2*(N-1)$,通信总量和RHD一样。Ring算法每一步骤发送数据量为D/N,通信总量为$D-\frac{D}{N}$
- reduce-scatter和allgather耗时均为:$(N-1)\alpha + \frac{D-\frac{D}{N}}{BW}$,额外的computation cost为$(D-\frac{D}{N})*\gamma$
- 目前广泛采用服务器内双向ring(reduce scatter),服务器间RHD(allreduce),再服务器内双向ring(all gather)
- 置换排列的数学表达与Benes网络
- 和allreduce没关系
- torus
- 两个方向的ring,mxn的结构,N=n*m,实现allreduce需要横向reduce-scatter+纵向allreduce+横向allgather
- ring的耗时为:$T_{ring_time}(N,D)=2[(N-1)\alpha + \frac{D-\frac{D}{N}}{BW}]$
- torus allreduce耗时为$T_{ring_time}(n,\frac{D}{m}) + T_{ring_time}(m,\frac{D}{n*m})$
- mesh√√√

- 普通的mesh网路需要先完成横向AllReduce+再纵向AllReduce
- D=C*M,(一般取C为N),$k=\frac{C}{2N}$,注意这里的设备一共有 NxN个
- 那么有 $T_{sparse}=((k+1)N-2)(N+1)\frac{M}{NBW}+((3k+1)N-4)* \alpha$
总结,小数据量下,butterfly和DBT都比较不错,大数据下,torus好。DBT在服务器之间的可扩展性最好
这里讲一个看到的All-Reduce Schedule Management的方法,原文在Communication Algorithm-Architecture Co-Design for Distributed Deep Learning
首先你大概需要一个软件的东西,来figure out每个accelerator需要执行哪些操作来完成一次allreduce,分别包含不同的tree不同的opcode不同的Parent & children
将上述信息 → 写入每个节点的 Schedule Table
Schedule Table会根据step等控制信息来有序地完成allreduce拆分后地子操作
…….、一些Paper
3.1 TidalMesh: Topology-Driven AllReduce Collective Communication for Mesh Topology
introduction部分讲述了:
- 节点被划分成多个子集或子集群(称为 “pod”),在实际使用过程中,一个pod可能并不会完全占满(例如64个节点中,实际仅使用了其中的32个节点或更少)。因为有些节点根本未使用,所以本该提高对称性的环绕通道失去了作用,甚至会增加额外的延迟(节点间跳数增加),没有充分利用网络的潜力,Torus在节点未充分利用时退化成了mesh网络。mesh拓扑因缺少环绕链路(wrap-around),导致边界节点之间的通信不对称,从而降低了环形AllReduce算法的效率。
- topology-aware是确定算法后,再考虑物理拓扑如何更好地适配已确定的算法。即让物理拓扑尽可能匹配算法的逻辑结构。本质上,这类方法是算法驱动的:算法逻辑在前,拓扑适配在后。缺点是:若物理拓扑(如2D网格)与算法拓扑(如逻辑环)本身存在结构上的不对称或不匹配,尽管进行了适配优化,依旧无法彻底避免通信路径长、节点间负载不均衡等问题。
- Topology-driven,首先观察物理拓扑的固有特性,然后据此设计出直接与物理拓扑相匹配的算法逻辑。
- Torus拓扑和Mesh拓扑的权衡:环绕链路通常较长,信号质量会下降,因此实际通信速率可能降低,即使跳数减少了,但整体数据流过边界链路时的吞吐率可能反而更低。所以Mesh网络单个链路的高带宽也能在一定程度上弥补路径更长的缺点
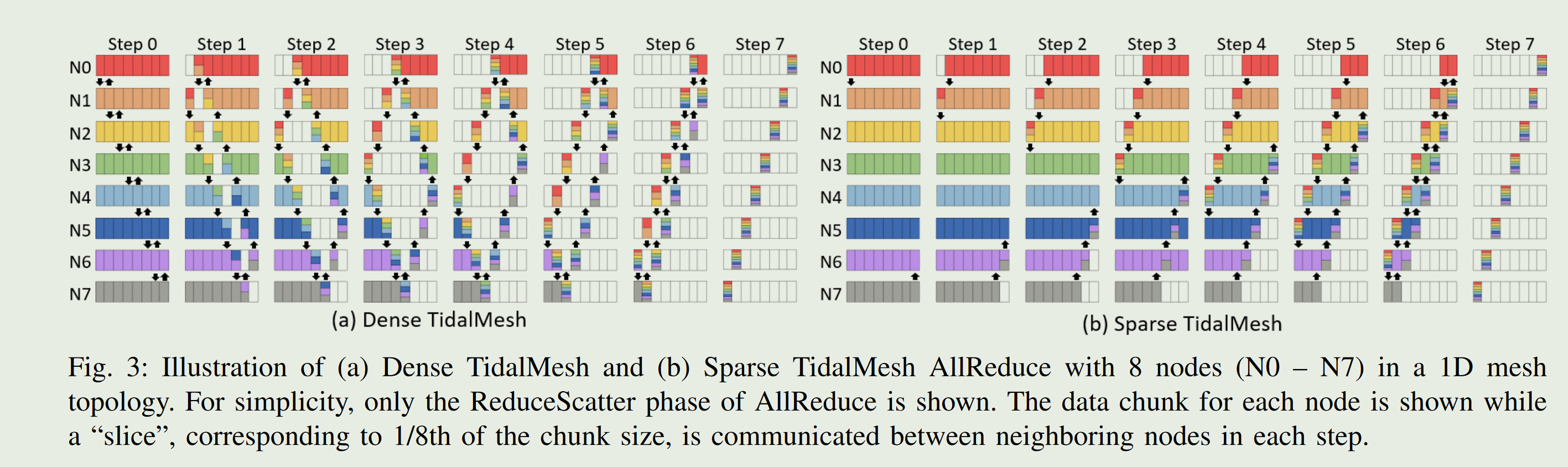
在步骤 0 中,非边节点在两个方向上传输相同的数据切片,但是对于其余的步骤,在每个方向上传输不同的切片
左边存在一部分的冗余传输,右边是优化后的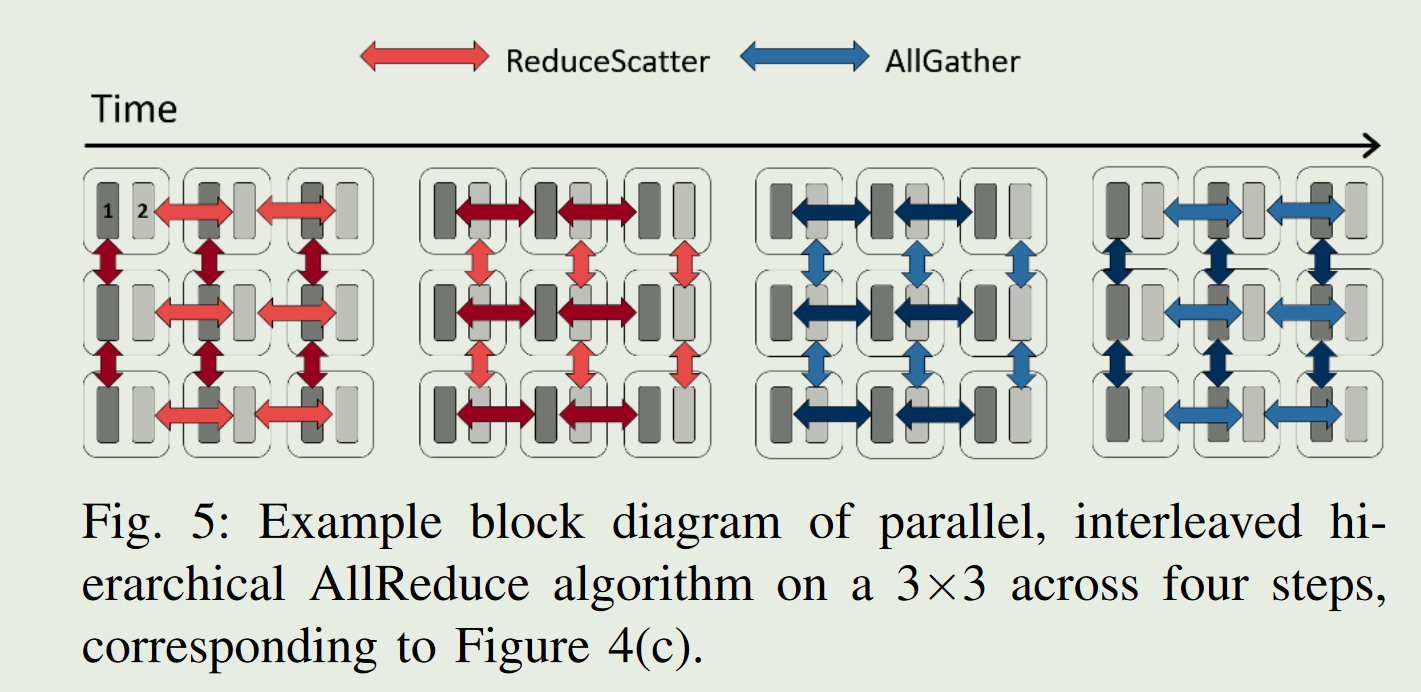
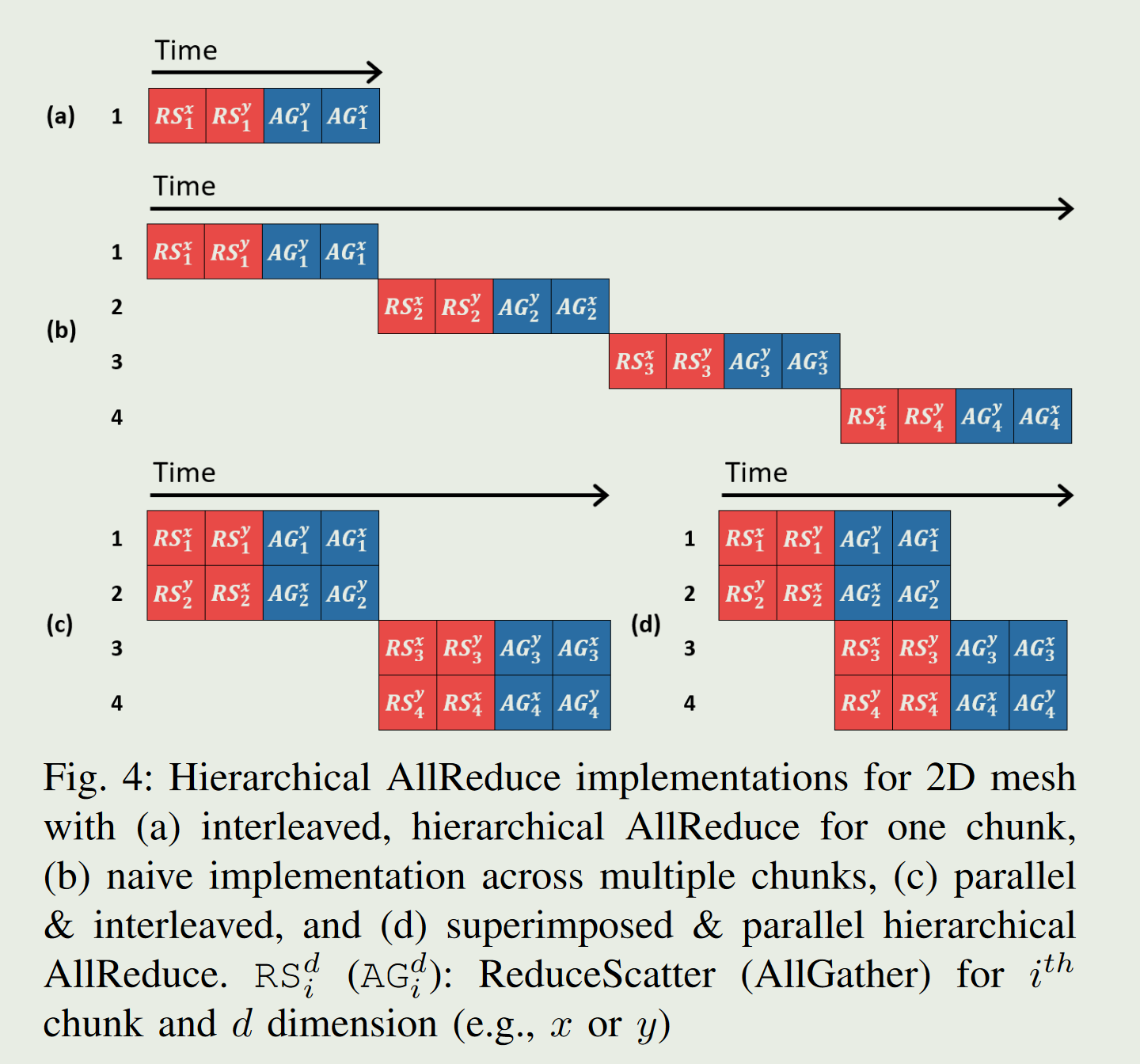
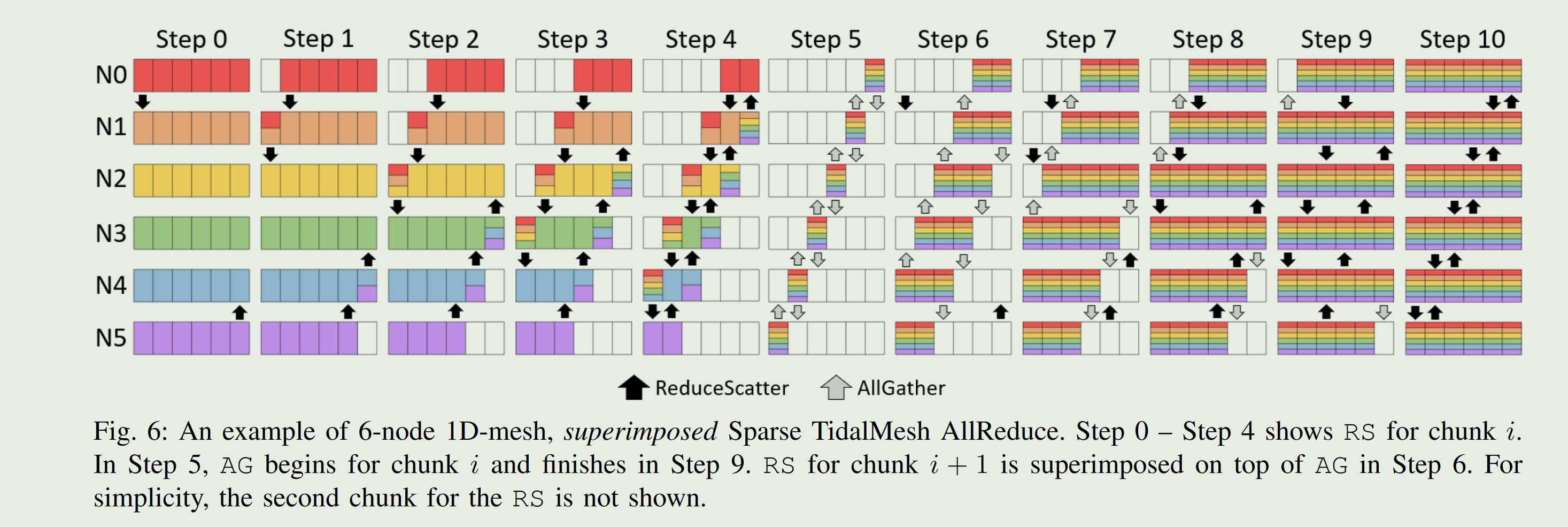
不同chunk的数据可以并行执行,并且每个node的数据可以减小拆分的大小。并且RS和AG可以并行
AllGather的运行顺序和前面的ReduceScatter是相反的。
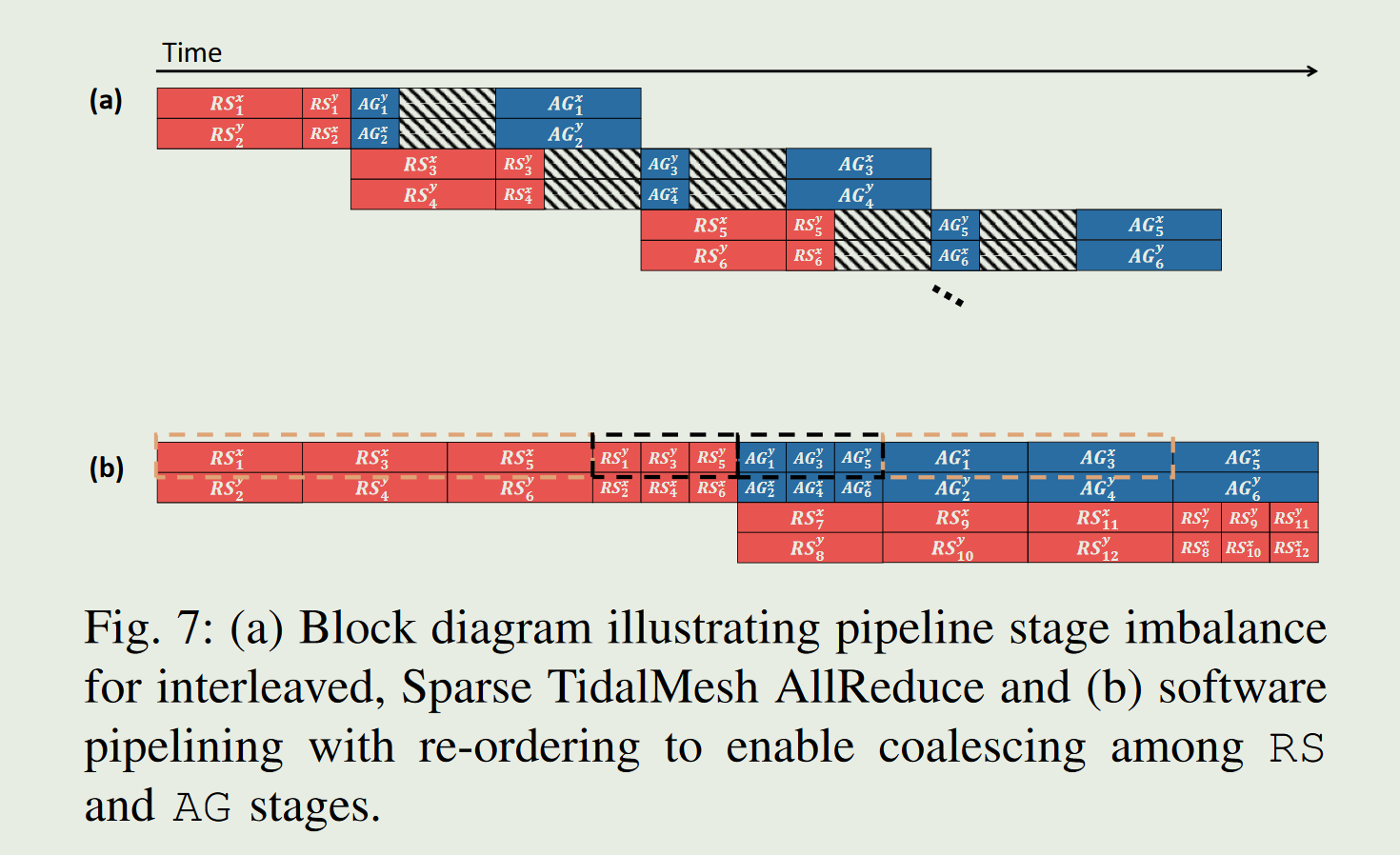
实际上RS在x维度的chunk1数据完成RS之后,需要传输的数据会被压缩掉1/N,所以你会发现数据整个链路存在stall的情况。可以利用软件的调度计算来解决这样的情况
Bandwidth Optimal All-reduce Algorithms for Clusters of Workstations
这篇文章讲述了一个基于ring的算法,butterfly在SMP/多核集群中会引起网络竞争,在数据量足够大时,对于具有不同节点架构和网络技术的集群,该算法比其他算法更高效。
这篇论文和
- 美国国家超级计算应用中心(NCSA)的 Teragrid IA - 64 Linux 集群, NCSA Teragrid IA - 64 Linux 集群是一个 Myrinet 集群,SMP 节点。
- 佛罗里达州立大学计算机科学系的 Draco 集群,Draco 集群是一个 InfiniBand 集群,具有 Dell PowerEdge 1950 节点,节点通过 20Gbps 双倍数据速率 InfiniBand 交换机连接。
- 一个以太网交换集群。以太网交换集群由 32 个计算节点组成,通过 Dell Powerconnect 2724 千兆以太网交换机连接。
使用 Mpptest 方法 测量算法的性能,和原生MPI、butterfly、一个特定于 SMP 的实现基于最近为 SMP 集群开发的算法(表示为 SMP - binomial,该算法不会引起网络竞争,但节点间通信不是带宽最优的)、 SMP - butterfly(SMP - butterfly 可以被视为对 butterfly 的改进:通过将节点内通信分组在一起消除网络竞争。)对比。结果如下
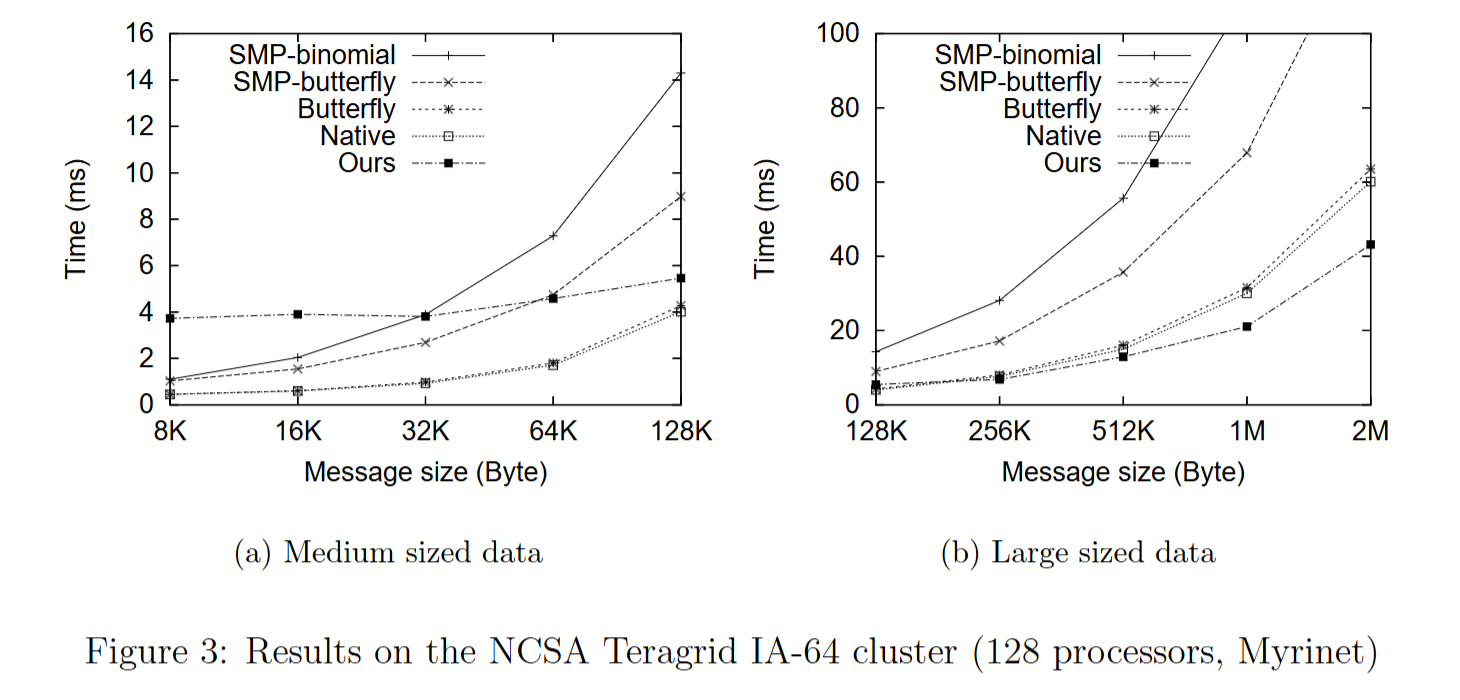
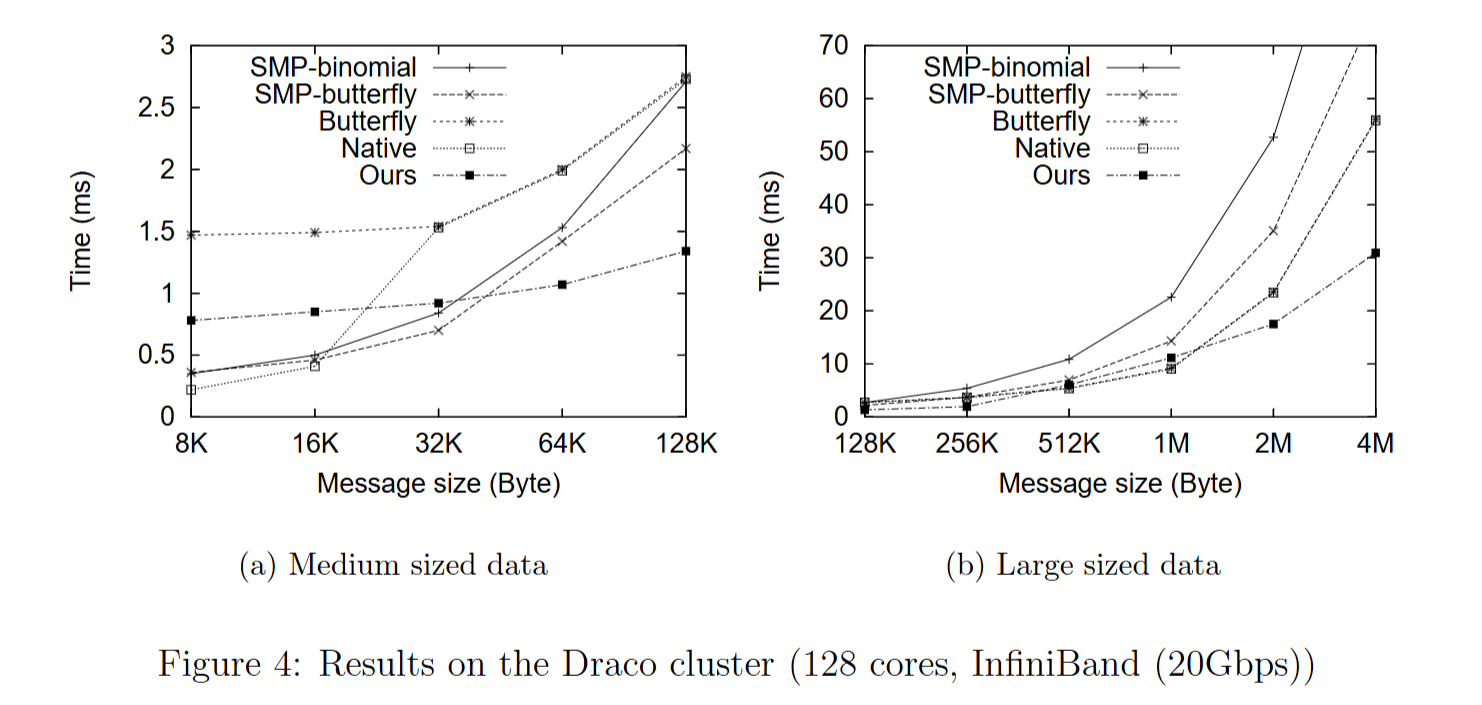
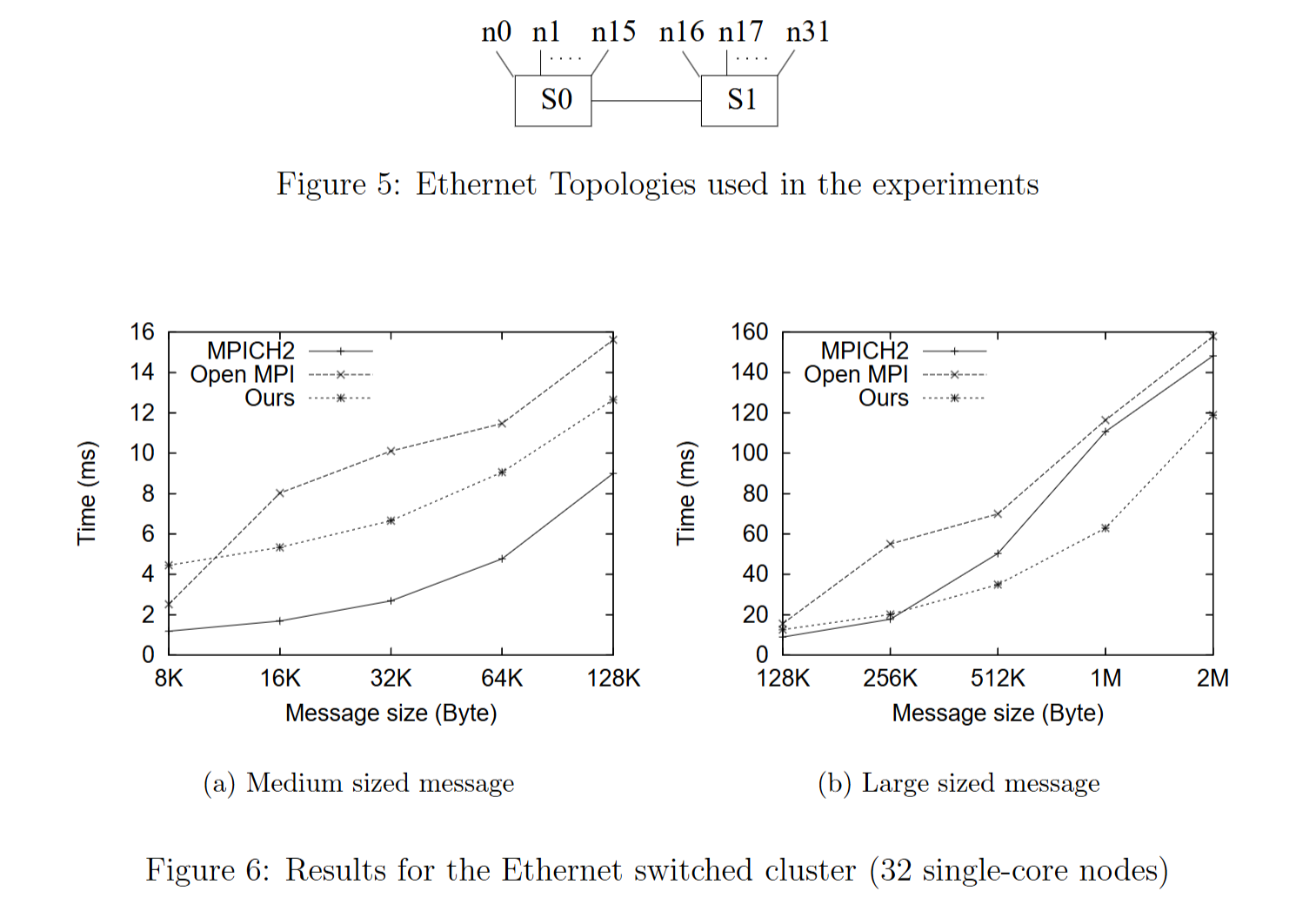
结果表明:
- 随着数据大小的增加,网络竞争会降低性能。ring对比其他算法在某个阈值下会表现出性能的优越性。当节点增多,这个阈值会变大
- 在具有千兆交换机的以太网交换集群中,ring算法通信启动开销比高端集群大得多,阈值会更大。当数据大小更大时,网络竞争和带宽效率成为问题
Optimized Broadcast for Deep Learning Workloads on Dense-GPU InfiniBand Clusters: MPI or NCCL?
感觉这个文章的对比思路很合适IOD,这里测试的是广播工作。或许可以考虑NCCL+Tensor计算展示基于纯 MPI 的设计在深度学习工作负载上能够提供与基于 NCCL 的解决方案相当或更好性能的研究。随着深度学习应用的出现,非常大的消息传输和相对较少的节点(GPU)数量正成为 MPI 运行时的新用例
下图展示了intra-node (up to 16 GPUs) performance using the CUDA-Aware osu_bcast benchmark,在小和中等消息范围内 NCCL 的性能下降。对于大型和非常大型的消息范围,我们看到 NCCL 提供了可扩展的性能。这里面的benchmark应该不止广播,文章提到
这是因为 MVAPICH2 - GDR 中可用的高级点对点设计允许有效地解决各种瓶颈,如跨套接字的 GDR 读取瓶颈 [26]。
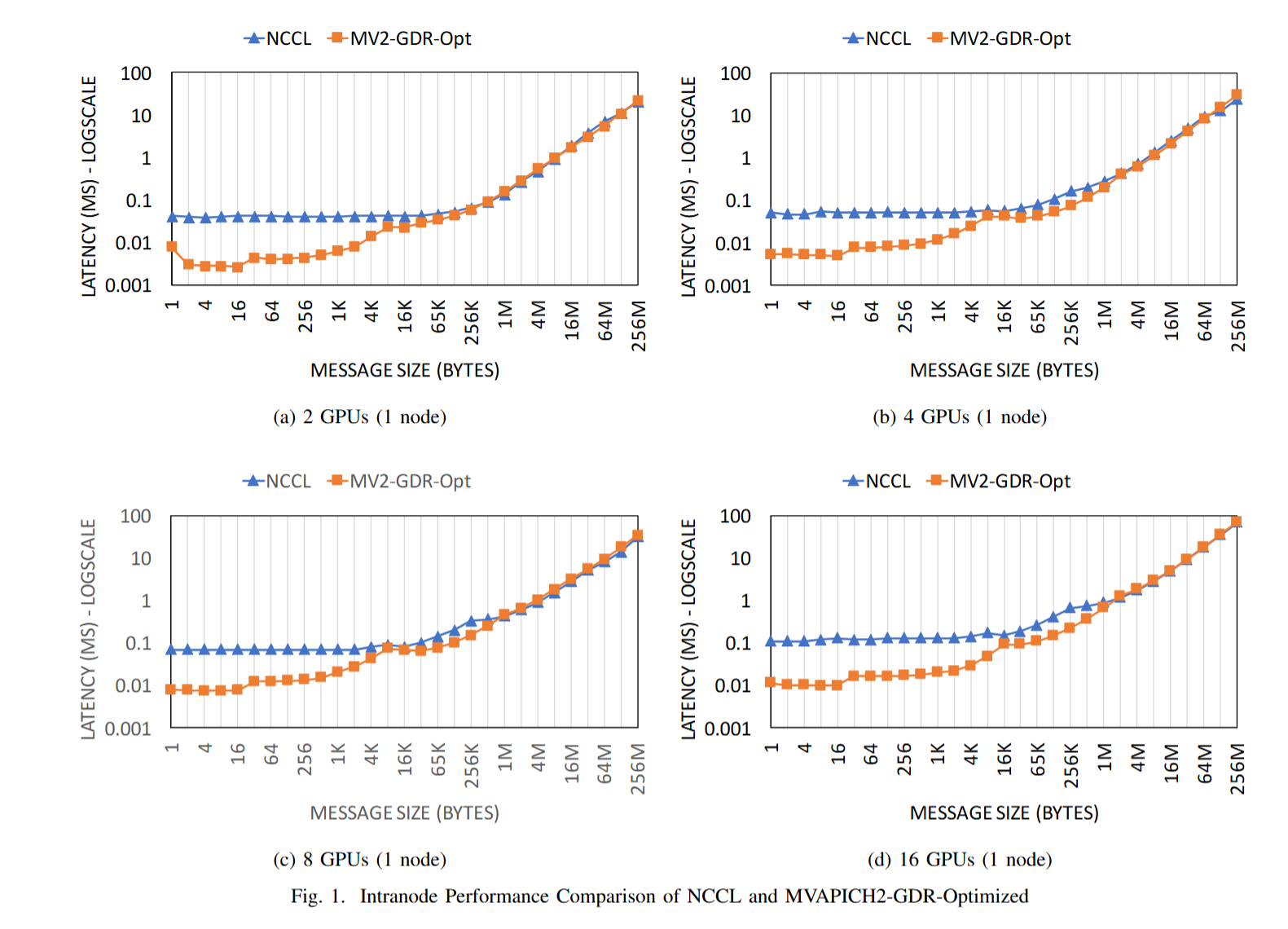
在集成 NCCL 的 MPI Bcast 设计中,利用 ncclBroadcast(NCCL)来实现节点内广播。测试不同GPU数量下,不同datasize
we exploit the ncclBroadcast (NCCL) to realize the intranode broadcast in the NCCL-integrated MPI Bcast design.(NCCL 1.x不支持节点间的访问,只能在intra-node),下面的文章能够完成全面的多节点间性能比较。
[4] A. A. Awan, K. Hamidouche, A. Venkatesh, and D. K. Panda, “Efficient Large Message Broadcast using NCCL and CUDA-Aware MPI for Deep Learning,” in Proceedings of the 23rd European MPI Users’ Group Meeting. ACM, 2016, pp. 15–22.
A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters —- BytePS
理论上看,PS的通信效率是大于等于all-reduce的,但是在实际使用中,PS的表现却往往不如all-reduce,为什么呢?
- 在上述的PS最优效率是在参数能够在不同server上均匀分配前提下的,这点在实际模型中可能难以做到,模型的参数总是有大有小;
- 传统的PS server是需要实现优化器逻辑的且一般是运行在CPU上,这部分计算量在上面的分析中并没有考虑,当模型参数量较大,优化器逻辑又相对复杂(比如adam等带动量的优化器)时,这部分计算耗时是无法忽略的,这一点在论文后面也有提到;
- 在PS中,worker和server是n对n的通信,这在节点数较大时,对整个集群的通信带宽也是个挑战。
Reference [8] T. Chiba, T. Endo, and S. Matsuoka, “High-Performance MPI Broadcast Algorithm for Grid Environments Utilizing Multi-lane NICs,” in Seventh IEEE International Symposium on Cluster Computing and the Grid (CCGrid ’07) , May 2007, pp. 487–494. Reference [33] R. Thakur, R. Rabenseifner, and W. Gropp, “Optimization of Collective Communication Operations in MPICH,” Int. J. High Perform. Comput. Appl. , vol. 19, no. 1, pp. 49–66, Feb. 2005. Reference [36] H. Zhou, V. Marjanovic, C. Niethammer, and J. Gracia, “A BandwidthSaving Optimization for MPI Broadcast Collective Operation,” in 2015 44th International Conference on Parallel Processing Workshops , Sept 2015, pp. 111–118.
Reference [9] C.-H. Chu, X. Lu, A. A. Awan, H. Subramoni, J. Hashmi, B. Elton, and D. K. Panda, “Efficient and Scalable Multi-Source Streaming Broadcast on GPU Clusters for Deep Learning,” in 46th International Conference on Parallel Processing (ICPP-2017) , Aug 2017, [To appear]. Reference [12] T. Hoefler, C. Siebert, and W. Rehm, “A Practically Constant-time MPI Broadcast Algorithm for Large-scale InfiniBand Clusters with Multicast,” in Proceedings of the 21st IEEE International Parallel & Distributed Processing Symposium (CAC’07 Workshop) , Mar. 2007, p. 232. Reference [19] A. R. Mamidala, L. Chai, H.-W. Jin, and D. K. Panda, “Efficient SMPaware MPI-level Broadcast over InfiniBand’s Hardware Multicast,” in Proceedings 20th IEEE International Parallel Distributed Processing Symposium , April 2006, p. 8. Reference [35] A. Venkatesh, H. Subramoni, K. Hamidouche, and D. K. Panda, “A High Performance Broadcast Design with Hardware Multicast and GPUDirect RDMA for Streaming Applications on Infiniband Clusters,” in 2014 21st International Conference on High Performance Computing (HiPC) , Dec 2014, pp. 1–10.