AMBA AXI随笔记
AXI4 exclusive/locked
Exclusive access,memory attribute
Outstanding Transfer
不需要等待前一笔传输完成就可以发送下一笔操作
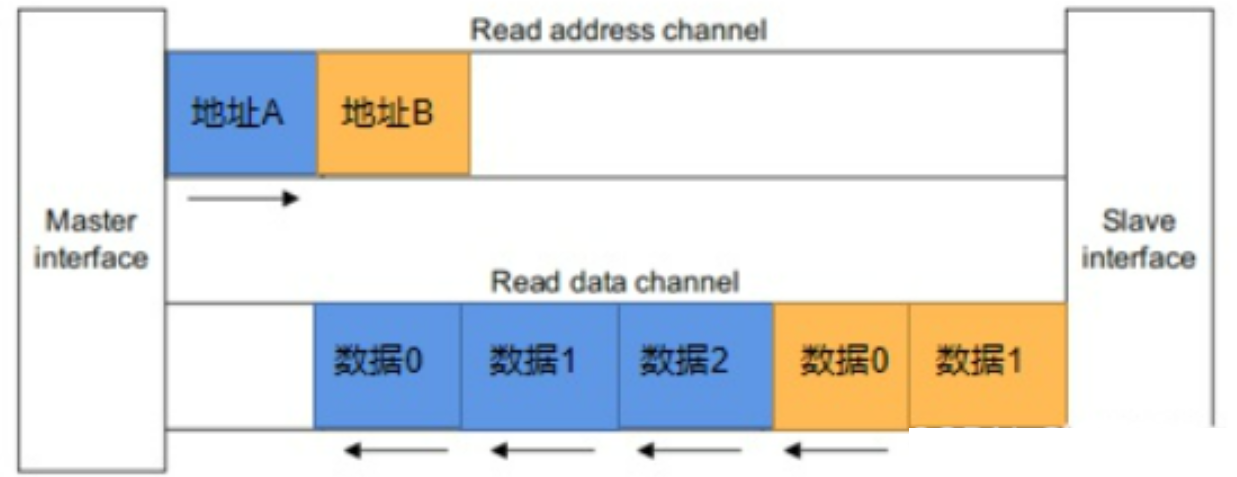
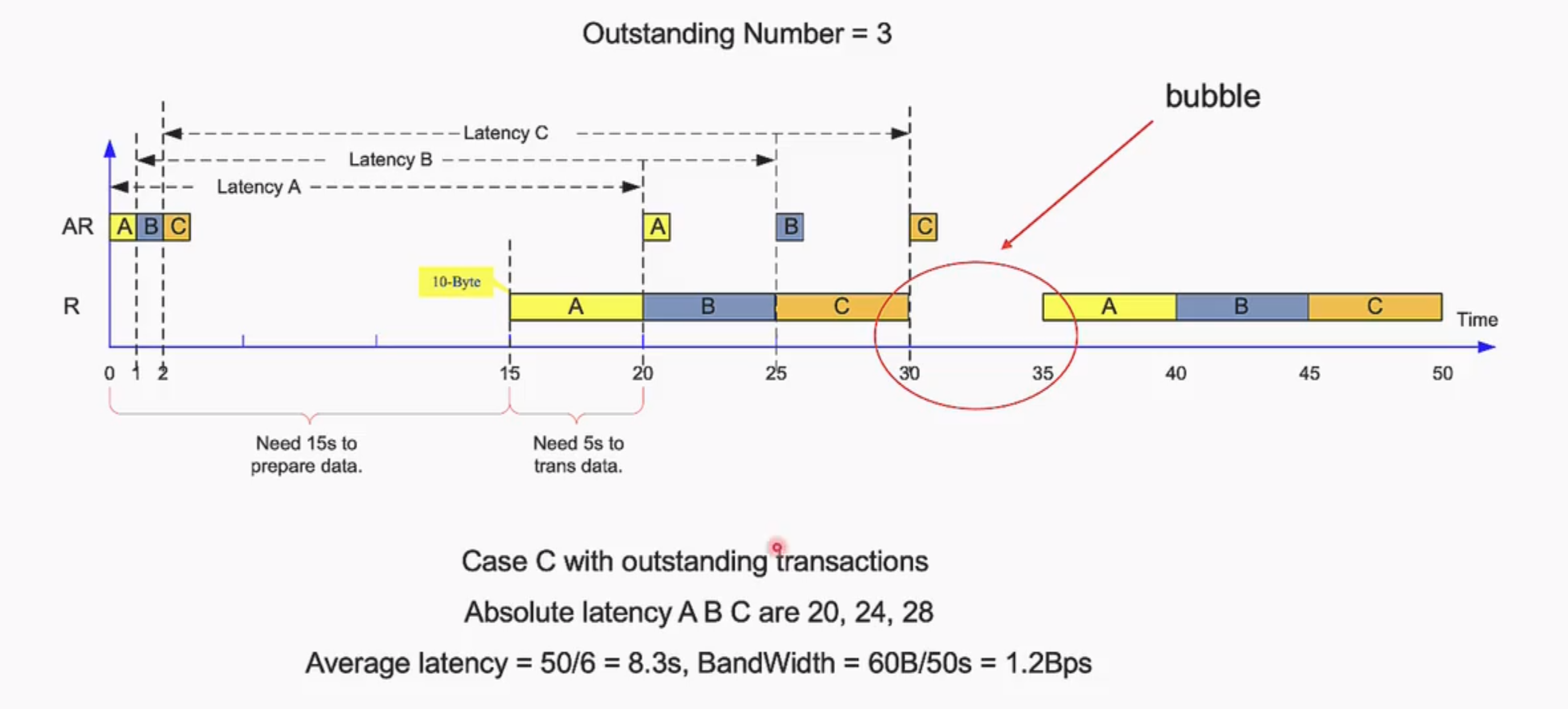
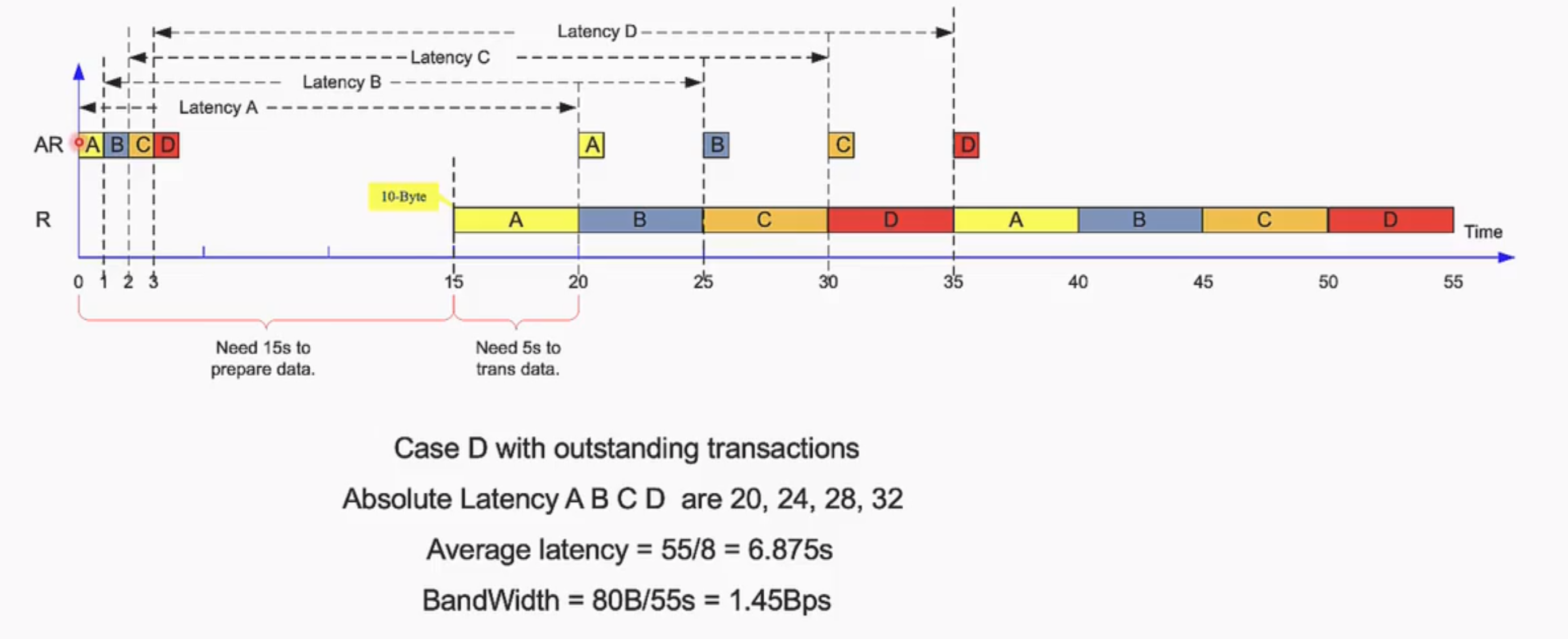
Outstanding的深度
合理选择好outstanding的深度(也叫做Write issuing capability)可以达到最大的带宽(tradeoff),最佳深度的范围在:$\frac{一次transaction传输所需要的时间}{数据传输需要的时间}$
Take a SoC for example:
- Suppose BUS@500MHz (period=2ns)
- Suppose AXI command is burst 8 (ideal: need 8 cycle to transfer)
- The latency is 200ns
Outstanding Num =200/ (2ns*8) =8~16
Outstanding的设计方法
你需要完整保存aw和ar通道的地址(addr)和控制信息(len,burst,id,size)
比如在D2D的设计中,将5个channel的各个信号打包成packet存储到异步fifo中,然后给LinkLayer读
Out-of-order Transfer
针对于多个从机,返回的response可以不按master访问的顺序。举个例子,master先向slave0发了读请求然后向slave1发了读请求。由于从机速度可能不一样,支持出现先返回slave1的数据然后返回slave0的数据
这里的bubble就可以先返回CD
排序规则:
- 所有的transfers in a trapsaction有相同的 ID,相同的ID的传输顺序must be ordered as issued,不同的ID没有顺序要求
- 写数据的顺序需要和地址顺序一致
Out-of-order的设计
需要使用多个同步Queue的队列来存储支持Out-of-order,每个Queue存储相同的ID,这项工作是由发起者完成的,无需在interconnect中考虑,但是interconnect需要考虑多master的ID填充
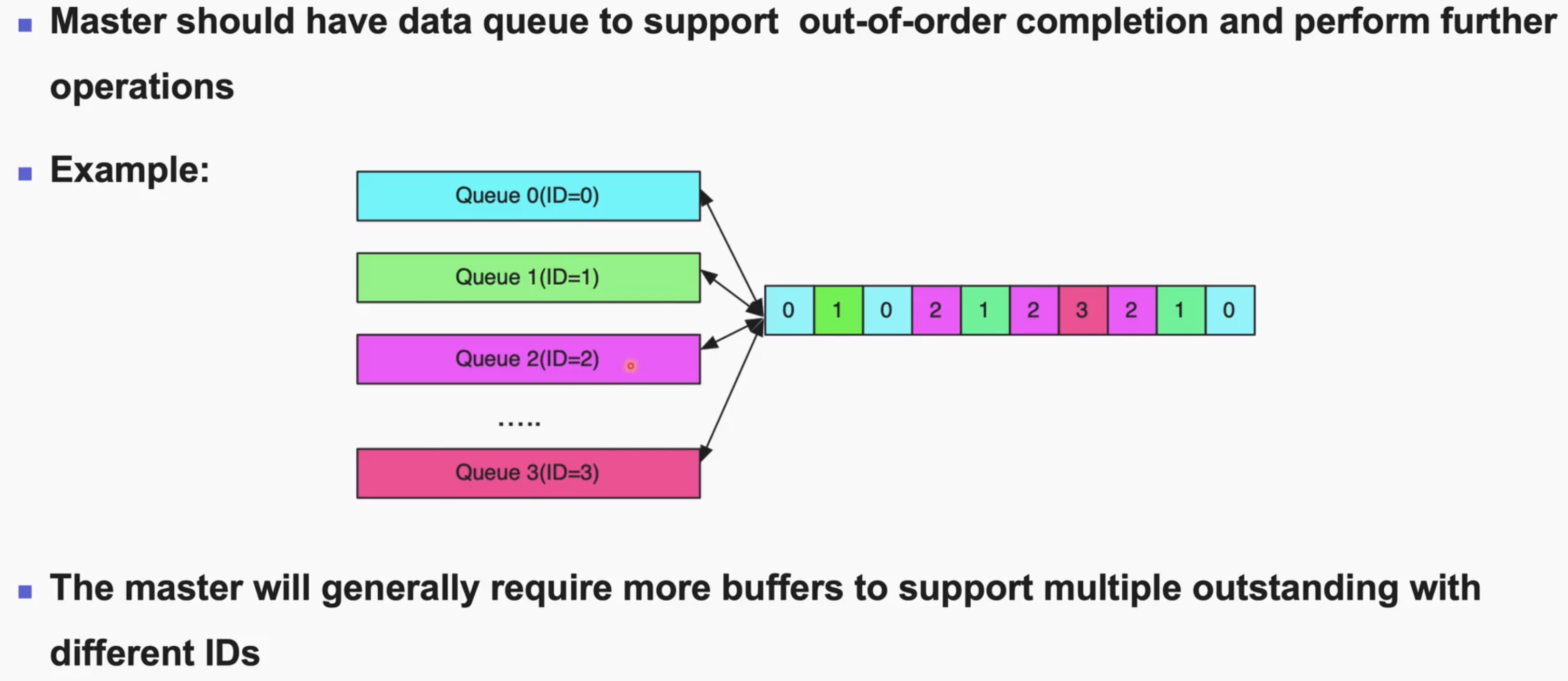
ordering model
- 对于相同ID而言:
- 对于同一个外设的事务:
- 必须按照它们被发出的顺序到达外设设备,无论这些事务的地址如何。
- 对于内存事务:
- 使用相同或重叠地址的事务,必须按照它们被发出的顺序到达内存。
- 对于同一个外设的事务:
- 如果两个具有相同 ID 的事务方向不同(如一个是读,一个是写),但需要有顺序关系:
- 主设备必须等待第一个事务的响应,然后再发出第二个事务。
拓展一个问题
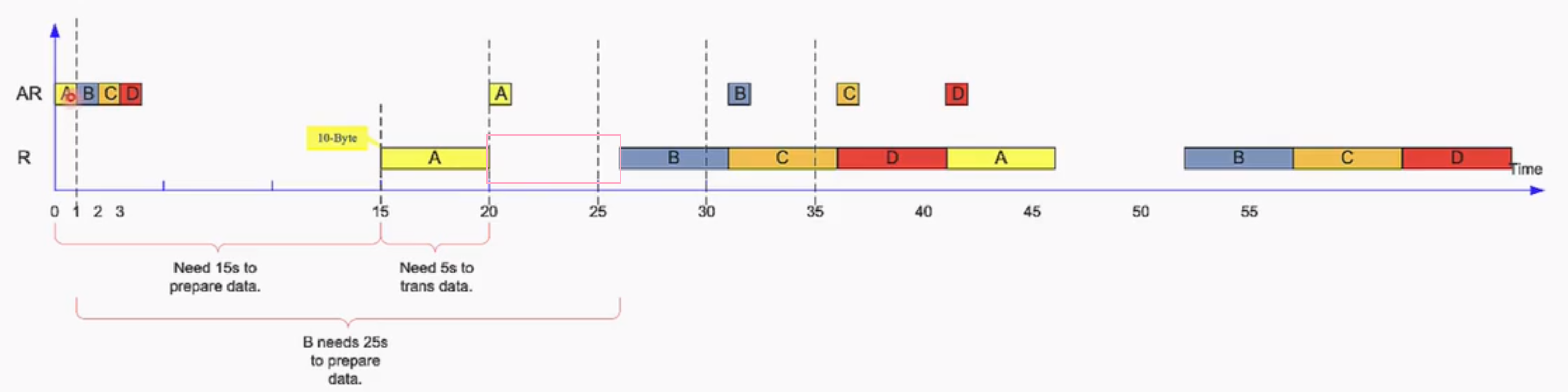
这里会存在一个switch死锁问题(Interconnect需要考虑的):返回的(B/R)由于需要按issue的顺序返回,提前返回的需要存到Queue中,当Queue满了还没有获得最开始发送的响应,就堵死了。我们需要预留空位(stall住master的发送),不让Queue占满,直到期待的响应发回,再放开stall
Interleaving Transfer
写Interleaving已经在AXI4中移除了读Interleaving是在乱序(Out-of-order Transfer)的基础上支持不同ID间数据之间的乱序
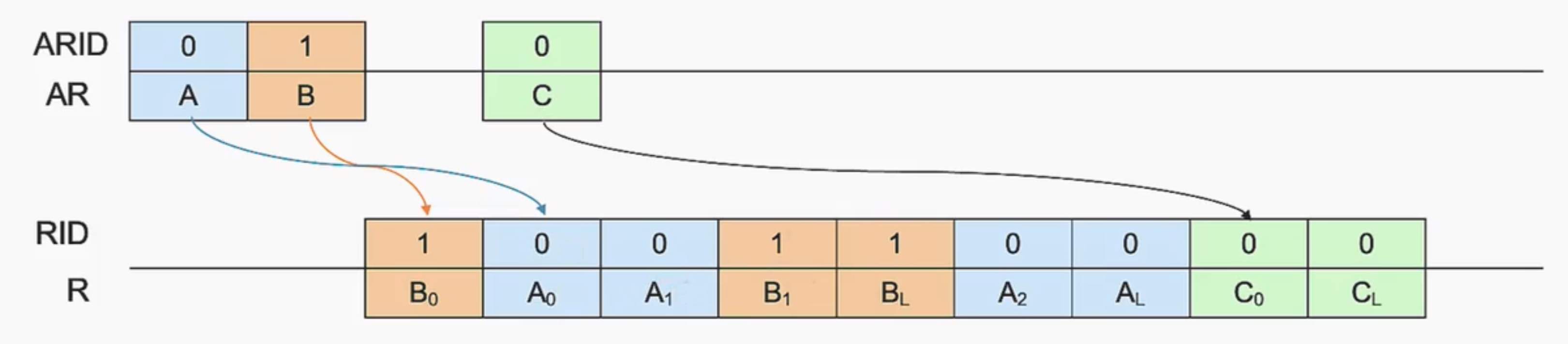
拓展
下面这张图解释了write interleaving出现死锁的情况 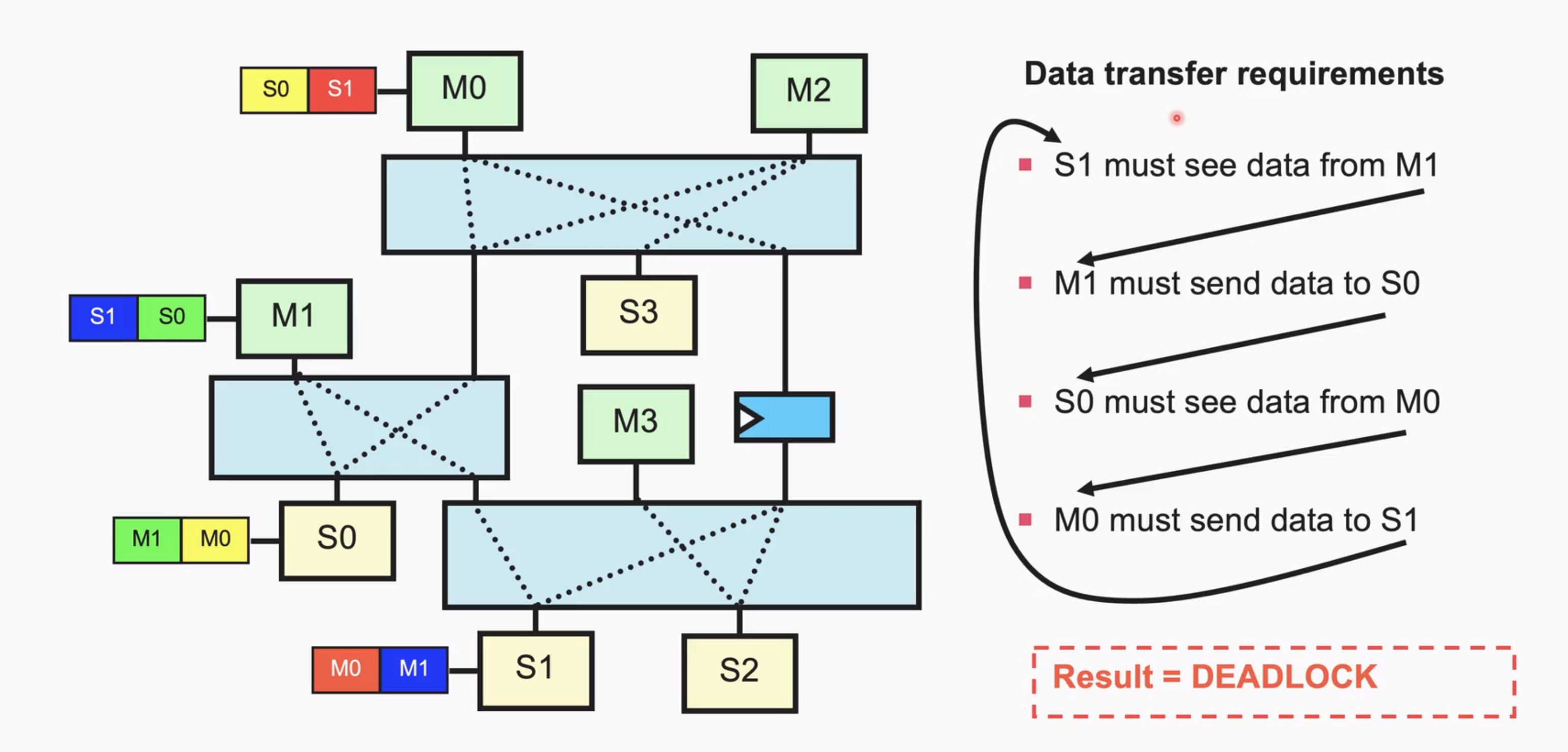
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
assign OffsetAddr = {12{ASIZE[1:0] == 2'b00}} & AddrIn |
{12{ASIZE[1:0] == 2'b01}} & {1'b0 ,AddrIn[11:1]} |
{12{ASIZE[1:0] == 2'b10}} & {2'b00 ,AddrIn[11:2]} |
{12{ASIZE[1:0] == 2'b11}} & {3'b000, AddrIn[11:3]} ;
assign IncrAddr = OffsetAddr + 1'b1;
assign WrapAddr[11:4] = OffsetAddr[11:4];
assign WrapAddr[3:0] = (ALEN & IncrAddr[3:0]) | (~ALEN & OffsetAddr[3:0]);
//wrap的burst_len只能为2 4 8 16,所以只改变低四位的地址
//~ALEN & OffsetAddr[3:0]保证在边界内,ALEN & IncrAddr[3:0]保证地址正常incr
assign MuxAddr = (ABURST == 2'b01) ? IncrAddr: WrapAddr;
assign CalcAddr = {12{ASIZE[1:0] ==2'b00}} & MuxAddr |
{12{ASIZE[1:0]==2'b01}} & {MuxAddr[10:0], 1'b0} |
{12{ASIZE[1:0] =2'b10}} & {MuxAddr[9:0], 2'b00} |
{12{ASIZE[1:0] == 2'b11}} & {MuxAddr[8:0], 3'b000};
assign AddrOut = CalcAddr;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//也可以这么写:
val CurAddr = IO(Input(UInt(AddrWidth.W)))
val Len = IO(Input(UInt(8.W)))
val Size = IO(Input(UInt(3.W)))
val Burst = IO(Input(UInt(2.W)))
val NextAddr = IO(Output(UInt(AddrWidth.W)))
val iCurAddr = CurAddr(11, 0)
val iNextAddr = Wire(UInt(12.W))
// Size Numeric Value
val iSize = MuxLookup(Size, 0.U, (0 to 7).map(x => x.U -> x.U))
// Word Address
val wordAddress = iCurAddr >> iSize
// INCR Next Addr
val incrNextAddr = (wordAddress + 1.U) << iSize
// WRAP Next Addr
val wrapBound = Cat(wordAddress(11, 4), (wordAddress(3, 0) & ~Len(3,0))) << iSize
val totSize = (Len(3,0) +& 1.U) << iSize
val wrapNextAddr = Mux(incrNextAddr === wrapBound + totSize, wrapBound, incrNextAddr)
iNextAddr := MuxLookup(Burst, CurAddr, Seq(0.U -> CurAddr, 1.U -> incrNextAddr, 2.U -> wrapNextAddr))
NextAddr := Cat(CurAddr(AddrWidth-1, 12), iNextAddr)
在AXI中,当地址增加到边界的时候,地址要回到起始值,公式为:
wrapaddr=(int( start_addr / (size * burst))) * (size * burst)
当地址等于wrapaddr+(size*burst)的时候, 地址回到wrapaddr
比如:size为4,burst_len为4(burst_len必须为2 4 8 16之一)。起始地址为 24(这个必须整除size)
则地址为:24 28 16 20 这个地方,16是关键点,当地址等于32的时候,地址回到起始int(24/16)*16=16
如何用代码实现这个功能呢?如下是个参考:
- 24/4=6
- 取低4bit做为起始地址a
- 将地址加1作为b
- len为(1 3 7 15)的二进制(AXI中规定长度为len+1)
| 则nextaddr = (len & b) | (~len & a); |
讲解一个AXI2SRAM的设计例子
下面两张图展示了读写的时序,下面讲解一下各个信号之间的关系
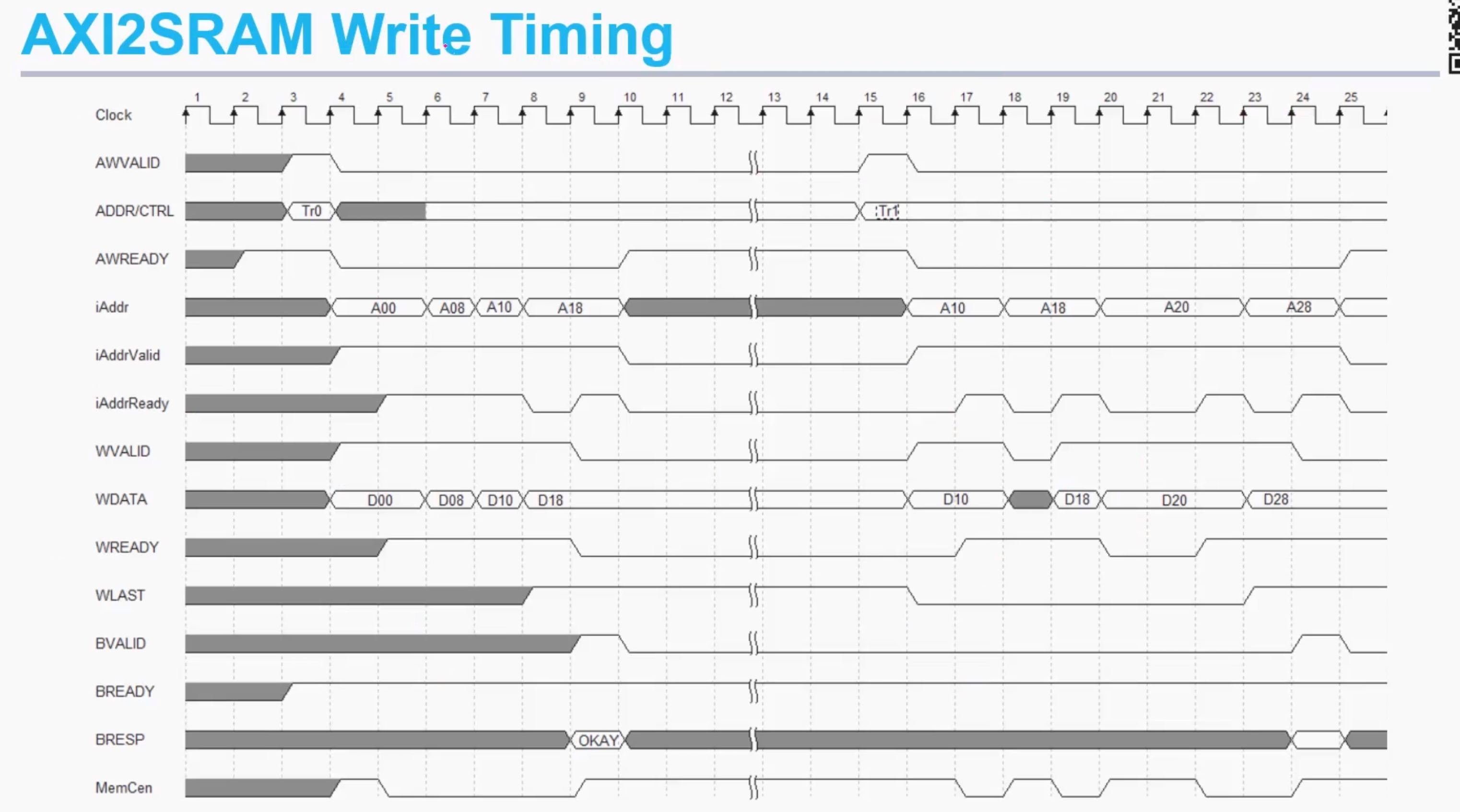
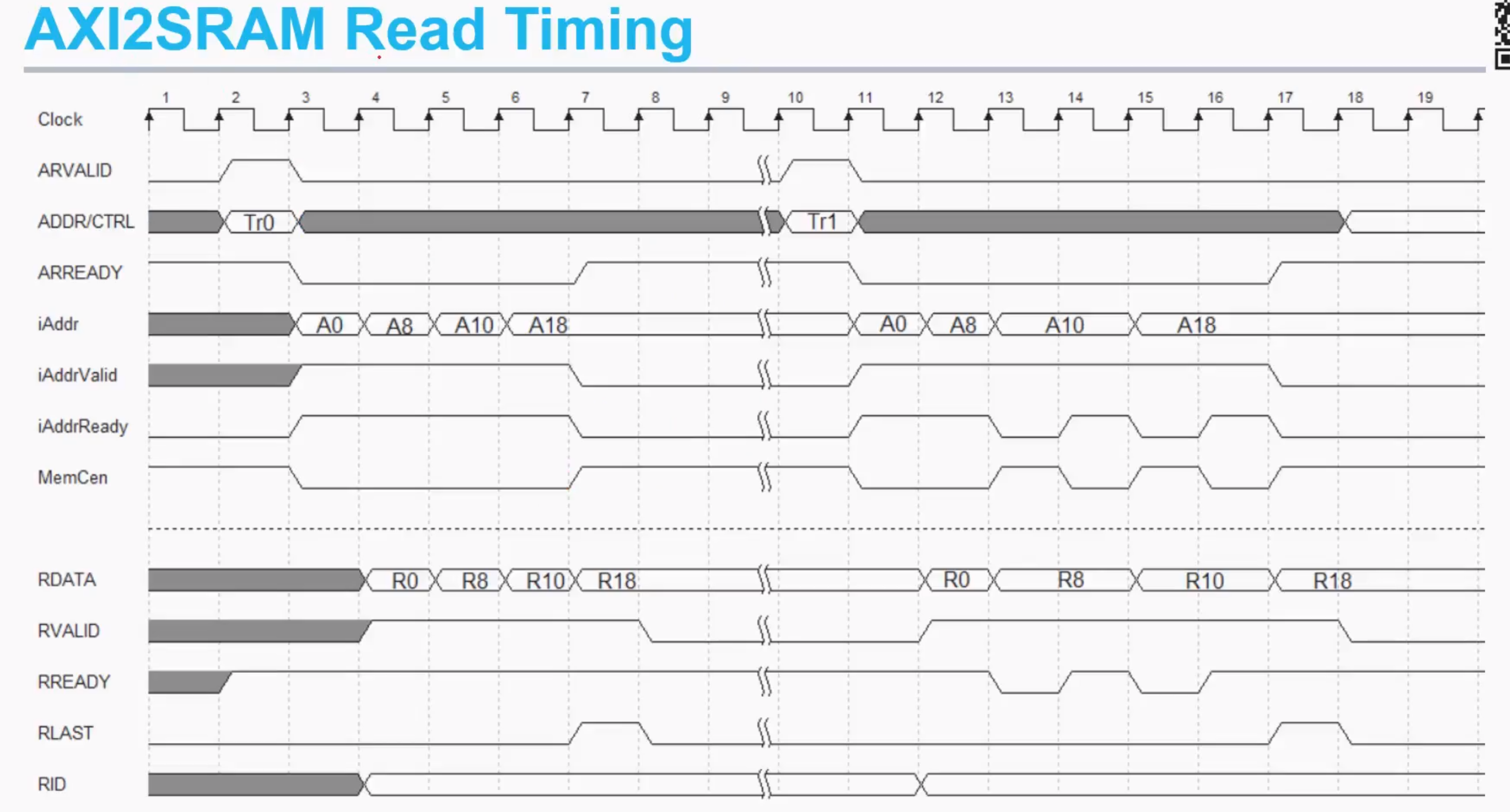
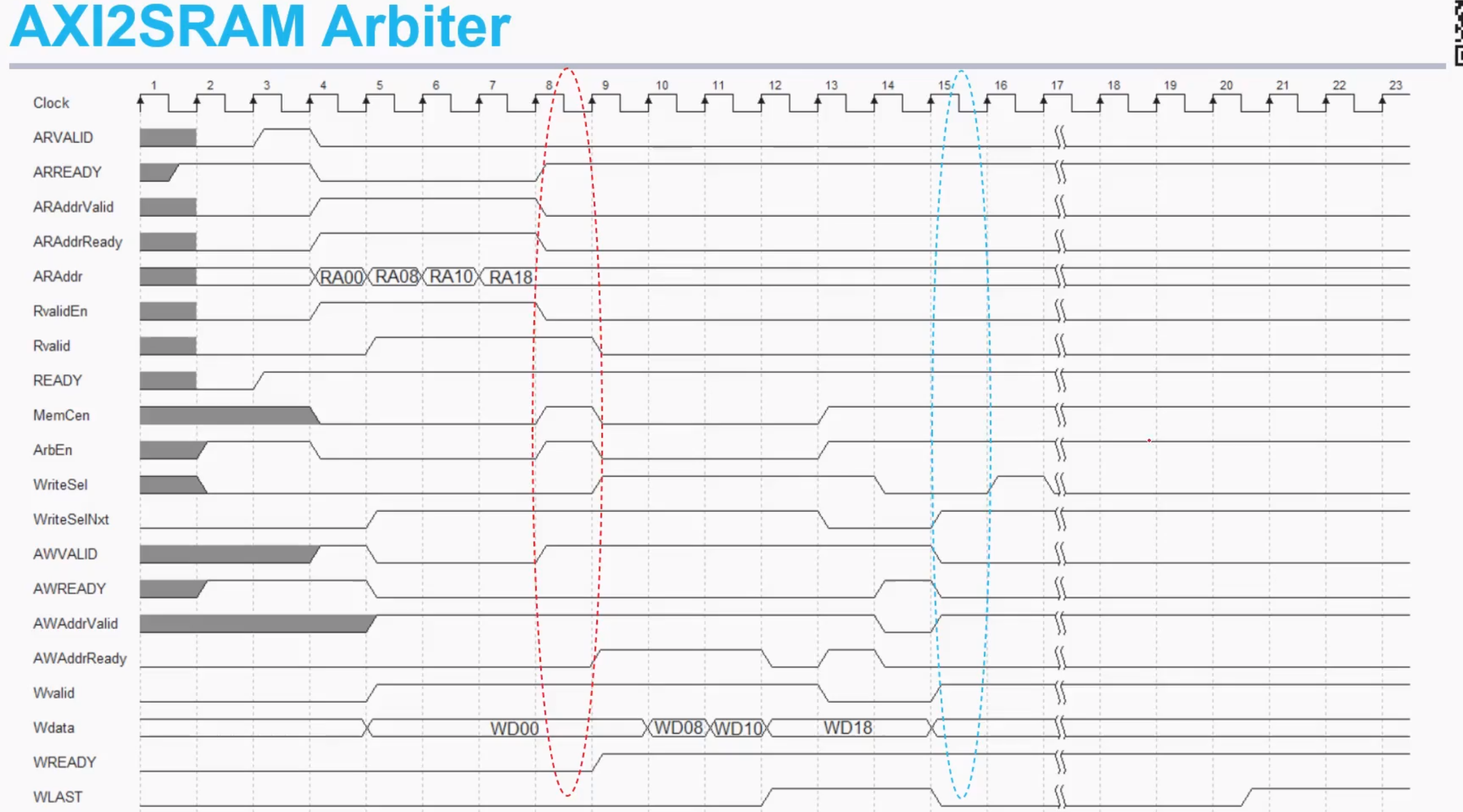
感觉arbiter的时序图有点问题,后面用到再说
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
//-------------------- AXItoSRAM --------------------//
SRAM.ADDR := Mux(WriteEngine.Ready, WriteEngine.Addr, ReadEngine.Addr)
SRAM.CEn := ~((wrIE.Ready & wrIE.Valid) | (rdIE.Ready & rdIE.Valid))
SRAM.WDATA := wrIE.Data
SRAM.WEn := ~(wrIE.Ready & wrIE.Valid)
SRAM.WBEn := ~wrIE.Strb
//-------------------- WriteEngine --------------------//
val Ready = IO(Input(Bool())) // for arbiter
val Valid = IO(Output(Bool()))// for arbiter, Valid := iValid
val Addr = IO(Output(UInt(AddrWidth.W)))// for SRAM
val Data = IO(Output(UInt(DataWidth.W)))// for SRAM
val Strb = IO(Output(UInt((DataWidth/8).W)))// for SRAM
val iAddrValidNext= Mux(S_AXI.AW.fire,
true.B,
Mux(S_AXI.B.fire,
false.B, iAddrValid))
iAddrValid := iAddrValidNext
S_AXI.AW.ready := ~iAddrValid
S_AXI.W.ready := iAddrValid & Ready //这个Ready是Arbiter给的arbiter.WrReady
iValid := iAddrValid & S_AXI.W.valid
Valid := iValid
//iLast := S_AXI.W.bits.LAST
//Data := S_AXI.W.bits.DATA
val iBValidNext = Mux(iValid & iLast & Ready,
true.B,
Mux(iBValid & S_AXI.B.ready,
false.B, iBValid))
iBValid := iBValidNext
S_AXI.B.valid := iBValid
//在aw.fire~b.fire期间,保持采样到的iLen(aw.len)、iSize、iBurst
NextAddr := SramAddrGen(AddrWidth, iAddr, iLen, iSize, iBurst)
val iAddrNext = Mux(iAwReady & S_AXI.AW.valid,
S_AXI.AW.bits.ADDR,
Mux(iValid & Ready,
NextAddr,iAddr))
iAddr := iAddrNext
Addr := iAddr
//-------------------- ReadEngine --------------------//
val Ready = IO(Input(Bool()))
val Valid = IO(Output(Bool()))
val Addr = IO(Output(UInt(AddrWidth.W)))//for SRAM
val Data = IO(Input(UInt(DataWidth.W)))//from SRAM to axi
val iRValidNext=Mux(iValid & Ready,
true.B,
Mux(iRValid & ~S_AXI.R.ready,
true.B,
Mux(iRValid & S_AXI.R.ready,
false.B,iRValid)))
iRValid := iRValidNext
S_AXI.R.valid := iRValid
val iRLastNext= Mux(iValid & iLast & Ready,
true.B,
Mux(iRValid & S_AXI.R.ready,
false.B, iRLast))
iRLast := iRLastNext
S_AXI.R.bits.LAST := iRLast
val iValidNext= Mux(S_AXI.AR.fire,
true.B,
Mux(iLast & Ready,
false.B, iValid))
iValid := iValidNext
Valid := iValid
val iCounterNext=Mux(S_AXI.AR.fire,
S_AXI.AR.bits.LEN,
Mux(iValid & Ready,
iCounter - 1.U, iCounter))
iCounter := iCounterNext
iLast := iCounter === 0.U
//-------------------- SramArbiter --------------------//
//这里的仲裁感觉不是很好,并不需要时时刻刻都在仲裁
//只需要在读完和写完的时候change
// Write Channel
val WrValid = IO(Input(Bool()))
val WrReady = IO(Output(Bool()))
// Read Channel
val RdValid = IO(Input(Bool()))
val RdReady = IO(Output(Bool()))
switch (Cat(WrValid, RdValid)) {
is (0.U) {
choiceNext := choice
}
is (1.U) {
choiceNext := false.B
}
is (2.U) {
choiceNext := true.B
}
is (3.U) {
choiceNext := ~choice
}
}
WrReady := choice
RdReady := ~choice
AXI VIP
JTAG to AXI Master IP可以驱动AXI Slave,这样就不需要硬核的参与,烧录比特流之后在终端使用Tcl控制
该IP不是用来仿真的,只有在使用Vivado逻辑分析仪Debug的时候,才能利用该IP进行动态实时交互
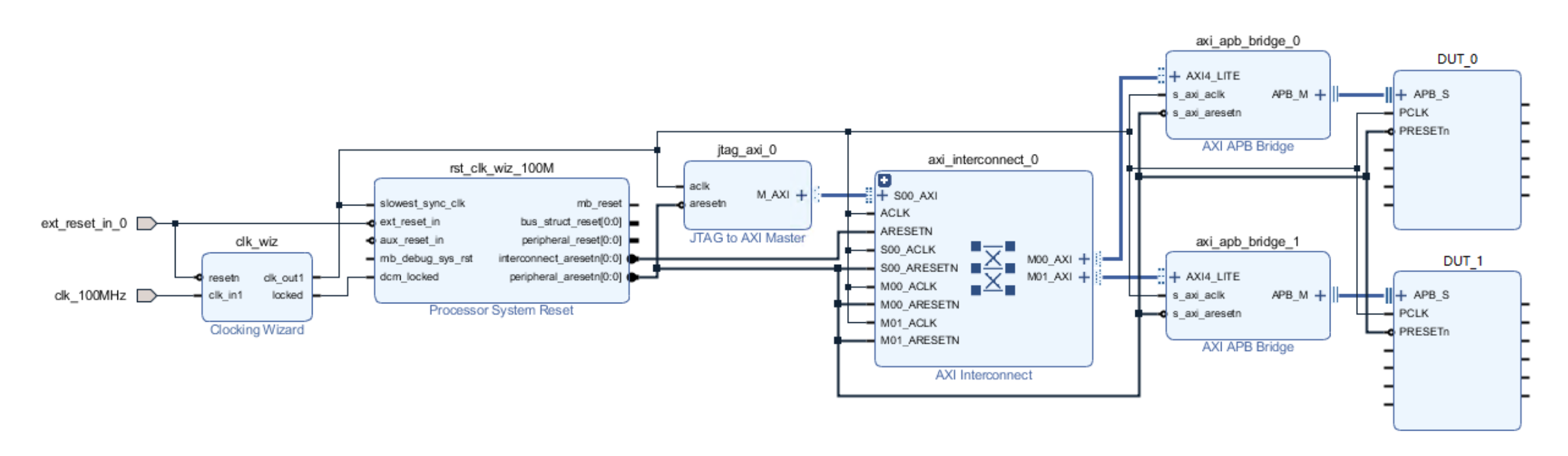
AXI 事务创建范例
事务创建范例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#--------------------------- AXI4 事务创建范例 -------------------------#
#-------- 1. 创建8个32bit数据的AXI突发写事务(32位地址) --------
create_hw_axi_txn wr_txn [get_hw_axis hw_axi_1] -address 00000000 -data\
{11111111_22222222_33333333_44444444_55555555_66666666_77777777_88888888} -len 8\
-size 32 -type write
//-------- 2. 创建8个32bit数据的AXI突发读事务(32位地址) --------
create_hw_axi_txn rd_txn [get_hw_axis hw_axi_1] -address 00000000 -len 8 -size 32\
-type read
#--------------------------- AXI4-Lite 事务创建范例 -------------------------#
create_hw_axi_txn wr_txn_lite [get_hw_axis hw_axi_1] -address 00000000 -data
12345678 -type write
create_hw_axi_txn rd_txn_lite [get_hw_axis hw_axi_1] -address 00000000 -type read
运行事务及删除事务
注:不能出现重名事务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#完整写法(我也不知道为什么要这么写。。。,如果有人知道望指教)
run_hw_axi [get_hw_axi_txns wr_txn ]
run_hw_axi [get_hw_axi_txns rd_txn]
run_hw_axi [get_hw_axi_txns wr_txn64 ]
run_hw_axi [get_hw_axi_txns rd_txn64 ]
run_hw_axi [get_hw_axi_txns wr_txn_lite ]
run_hw_axi [get_hw_axi_txns rd_txn_lite ]
#简略写法(我这样写也行)
run_hw_axi wr_txn
run_hw_axi rd_txn
run_hw_axi wr_txn64
run_hw_axi rd_txn64
run_hw_axi wr_txn_lite
run_hw_axi rd_txn_lite
#完整写法(我也不知道为什么要这么写。。。,如果有人知道望指教)
delete_hw_axi_txn [get_hw_axi_txns wr_txn ]
delete_hw_axi_txn [get_hw_axi_txns rd_txn]
delete_hw_axi_txn [get_hw_axi_txns wr_txn64 ]
delete_hw_axi_txn [get_hw_axi_txns rd_txn64 ]
delete_hw_axi_txn [get_hw_axi_txns wr_txn_lite ]
delete_hw_axi_txn [get_hw_axi_txns rd_txn_lite ]
#简略写法(我这样写也行)
delete_hw_axi_txn wr_txn
delete_hw_axi_txn rd_txn
delete_hw_axi_txn wr_txn64
delete_hw_axi_txn rd_txn64
delete_hw_axi_txn wr_txn_lite
delete_hw_axi_txn rd_txn_lite
一个调试的Tcl脚本示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
#注:这里使用的是AXI-Lite接口
#**************W/R CONTROL**************
set data_list ""
set num 1
proc ReadReg { address } {
global data_list
global num
create_hw_axi_txn read_txn [get_hw_axis hw_axi_1] -address $address -type read
run_hw_axi read_txn
set read_value [lindex [report_hw_axi_txn read_txn] 1];
append data_list [format %3i $num]
append data_list [format %3s r]
append data_list [format %10s $address]
append data_list [format "%10s\n" $read_value]
delete_hw_axi_txn read_txn
incr num
set tmp 0x
append tmp $read_value
return $tmp
}
proc WriteReg { address data } {
global data_list
global num
create_hw_axi_txn write_txn [get_hw_axis hw_axi_1] -address $address -data $data -type write
run_hw_axi write_txn
set write_value [lindex [report_hw_axi_txn write_txn] 1];
append data_list [format %3i $num]
append data_list [format %3s w]
append data_list [format %10s $address]
append data_list [format "%10s\n" $write_value]
delete_hw_axi_txn write_txn
incr num
}
#**************USER**************
WriteReg 00000000 12345678
if {[ReadReg 00000000] == 0x00005678} {
puts "**************\n\
write success!\n\
**************\n"
} else {
puts "**************\n\
write fail!\n\
**************\n"
}
#**************IO CONTROL**************
set currentTime [clock seconds]
set ctime "The time is: \
[clock format $currentTime -format %D] \
[clock format $currentTime -format %H:%M:%S] \n"
#需编辑自定义文件路径
set file_name "D:/data.txt"
set fp [open $file_name a+]
puts $fp $ctime
puts $fp $data_list
close $fp
set fp [open $file_name r]
set file_data [read $fp]
puts $file_data
close $fp
这是一个用什么VS来用c的api调试替换tcl的教程,但是我觉得没必要
附录-信号释意
- AxPROT[2:0] :给CPU用的,AxPROT[0]特权模式;AxPROT[1]Non-secure;AxPROT[2] Instruction
- AxCACHE[3:0]: [WA:RA:C/M:B] write/read allocate;Cacheable(AXI3)/Modifiable(AXI4);Bufferable (Modifiable:The burst and transfer characteristics can change between source and destination)
- AxLOCK:normal和exclusive
- locked access:Blocks(阻止) access from all other masters to the slave.(AXI4取消了)
- exclusive access:阻止其他对memory region in the slave的访问
- The exclusive access mechanism enables the implementation of semaphore type operations without requiring the bus to remain locked to a particular master for the duration of the operation.
- semaphore:Requires slave hardware support.Exclusive Access Monitor.对share的region进行lock
- exclusive:先进行读某个地址空间的地址,获取lock之后可以写,写成功会清除lock
- AxQOS:[3:0],Encoding of 0xF is highest priority 可以用作arbiters和slave对访问的顺序进行调整
- AxREGION:[3:0],Usage Models:
- 可以借助master的信号来区分访问memory的哪一块region,简化slave对地址的译码操作
- slave可以限制不同区域的访问等行为
- AXI3升级到AXI4
- 从之前的16长度的burst support (up to 256 beats. i.e.AxLEN is 0-255)
- 去除了write data interleaving和LOCK
- AXI4 增加了2个4-bit QoS 命令信号,增加了user信号。
- AXI4为了支持区域标识,增加了两个4-bits的region区域标识符
- AXI-Lite:和AXI4的区别
- All accesses are Non-modifiable, Non-bufferable,不支持Exclusive
- data bus必须为32 or 64 的full width,且burst length为1
- AXIStream 没看
- Slaves建议设计的ID width可配置,因为master可能的宽度是不确定的