AMBA CHI随笔记--放弃篇
overall
CHI的几个重要概念 【CHI】transaction事务汇总
无论是独占状态还是共享状态,缓存里面的数据都是clean,在独占状态下对应的Cache Line只加载到了当前CPU核所拥有的Cache里。其他的CPU核,并没有加载对应的数据到自己的Cache里。这个 时候,如果要向独占的Cache Block写入数据,我们可以自由地写入数据,而不需要告知其他CPU核。如果收到了一个来自于总线的读取对应缓存的请求,它就会变成共享状态。
在共享状态下,需要先向所有的其他CPU核心广播一个请求,把其他CPU核心里面的Cache,都变成无效的状态,然后再更新当前Cache里面的数据。这个广播操作,一般叫作RFO(Request For Ownership),也就是获取当前对应Cache Block数据的所有权。
CHI协议的发展 前置知识–Transaction Serialization和总线嗅探(Bus Snooping)
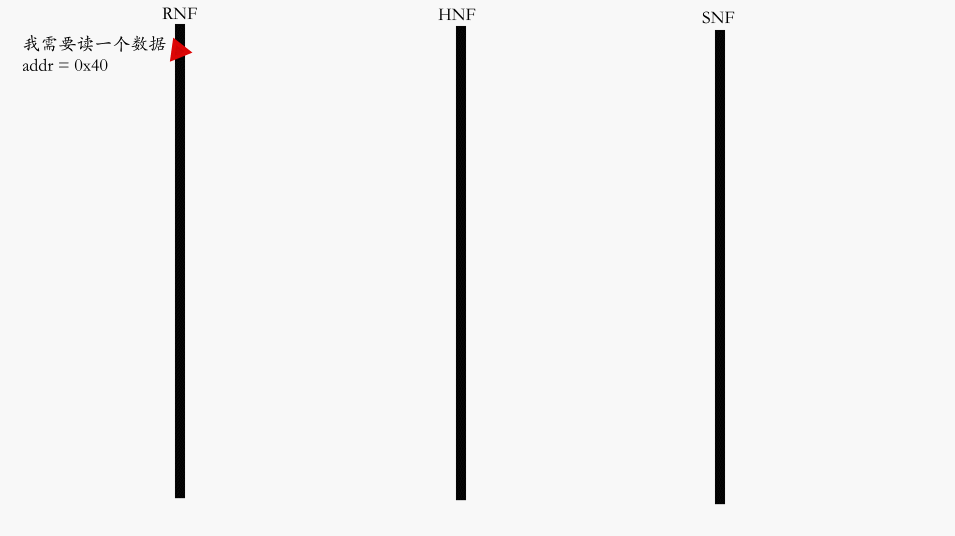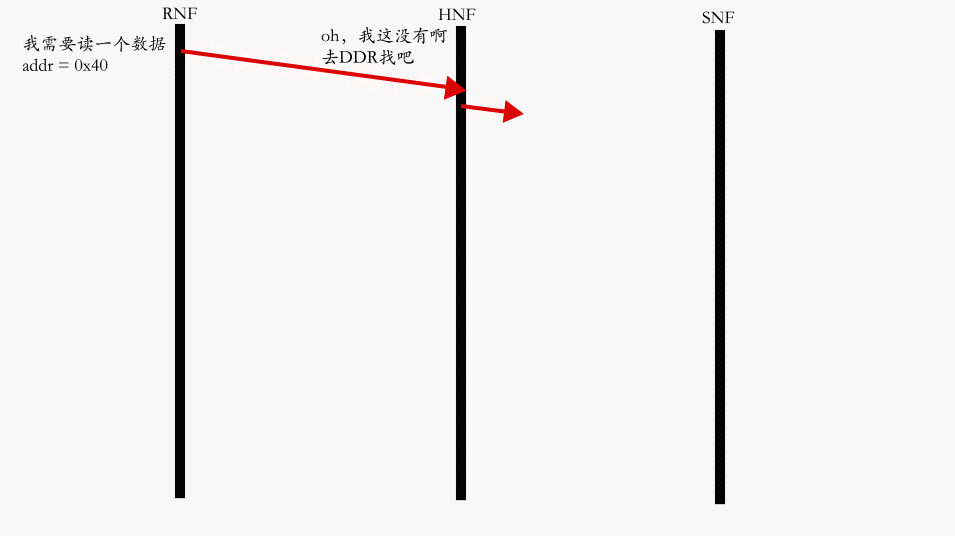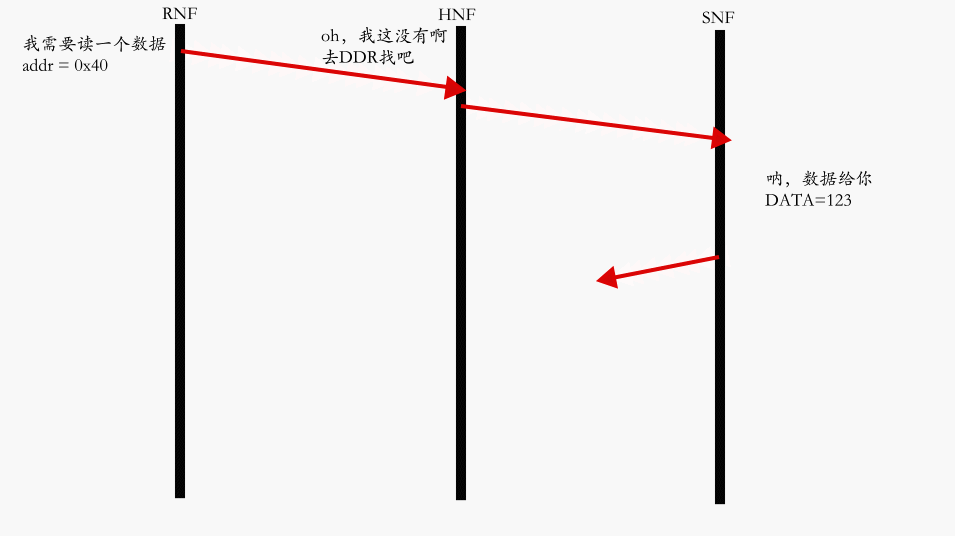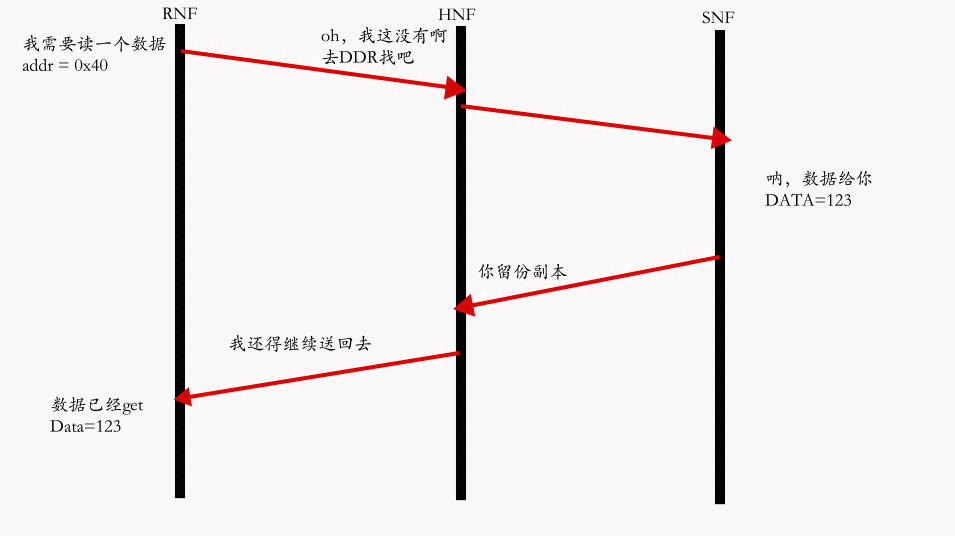
Core 未命中读路径最典型的 Flow:
体系结构层
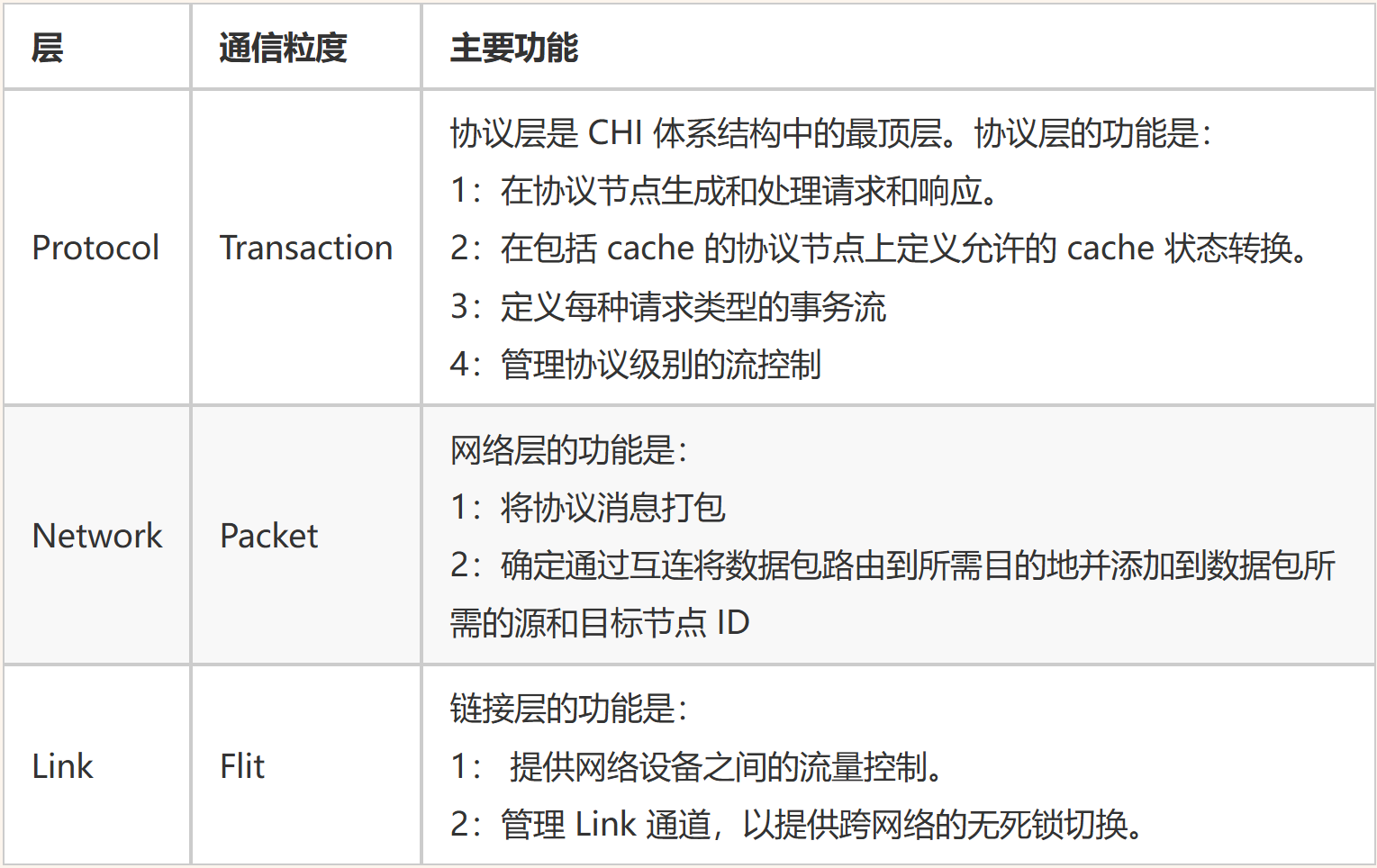
chap1 basic
Coherence overview:如果两个组件对同一存储器位置的写入可被所有组件以相同的顺序观察到,则存储器区域是一致的。
分布式虚拟内存DVM 接口主要用于 Broadcast TLB Invalidate
- 全面的分层(协议层、网络层、链路层)功能可从小到大的系统扩展
- 4 个统一通道(REQ、SNP、DAT、RSP),减少了连线的数量
- 通过 Link Credit 机制简化了传输流程(不再使用 valid 和 ready 握手)
- 协议中心化的流控,如每个通道 Link Credits 和 RetryAck 防止阻塞机制
- 更精细的 Cache 状态方案,使 Caches 更加及时响应
- 增加用于数据控制的 Cache stashing 和 atomic 操作(ACE5 也开始引入了)
1.5.1 缓存一致性模型
下图展示了一个一致性模型,该系统包括三个 Requester 组件,每个组件都具有本地 cache 和一致性协议节点。该协议允许同一存储器位置的 cache 副本驻留在一个或多个请求方组件的 local cache 中。
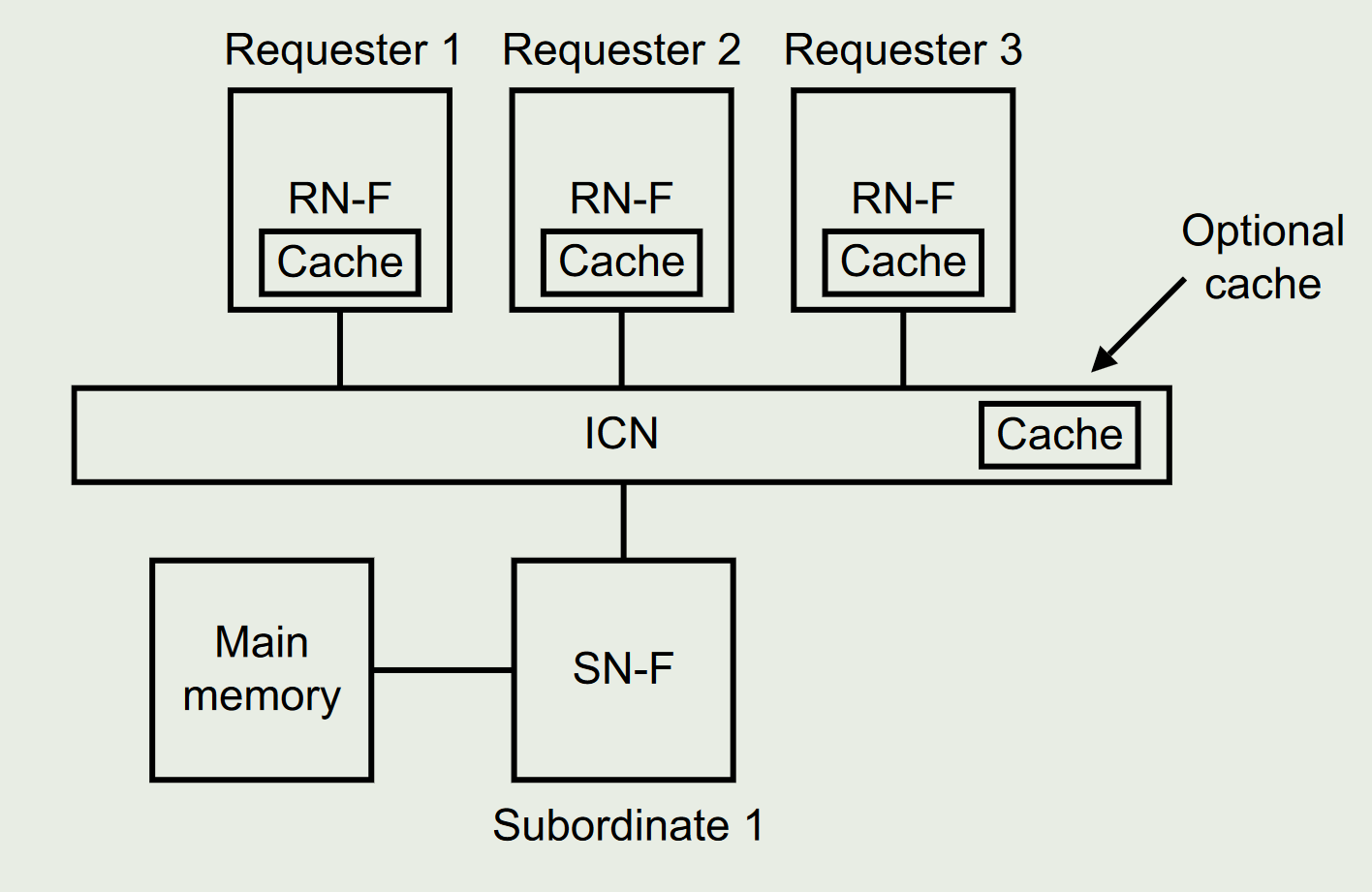
一致性协议强制规定,每当在某个地址位置发生写操作时,数据值的副本不得超过一份(也就是只有一个cache中存放了该地址的新数据)。一致性协议确保所有请求者在任何给定地址位置观察到正确的数据值。每次存储到某个位置后,其他请求者都可以为自己的本地缓存获取新数据的新副本,以允许存在多个缓存副本。写操作发生时,将其他缓存中该地址的副本无效化或更新
cache line 被定义为大小为 64 字节的以 64 字节对齐的存储器区域。所有一致性都以 cache line 为颗粒度
只有在内存位置的副本不再保存在任何 cache 中之前,才需要更新主内存(无效之前一刻)。该协议不要求主存储器始终保持最新。当某个cache要写主存的时候,该协议使 Requester 组件能够确定 cache line 是否是特定内存位置的唯一副本,如果是唯一的,可以直接改,不然就要用适当的事务通知其他 cache
1.5.2 Cache 状态模型
| 状态特征 | 描述 |
|---|---|
| Valid | 该 cache line 存在于 cache 中 |
| Invalid | 该 cache line 不存在于 cache line 中 |
| Unique | 该 cache line 仅存在于该 cache 中 |
| Shared | 该 cache line 可能存在于多个 cache 中(并不能保证) |
| Clean | 该 cache 不负责更新主存 |
| Dirty | cache line 已相对于主内存进行了修改,并且此 cache 必须确保最终更新主存 |
| Full/Partial/Empty | cache line的字节有效部分 |
1.6 组件协议node
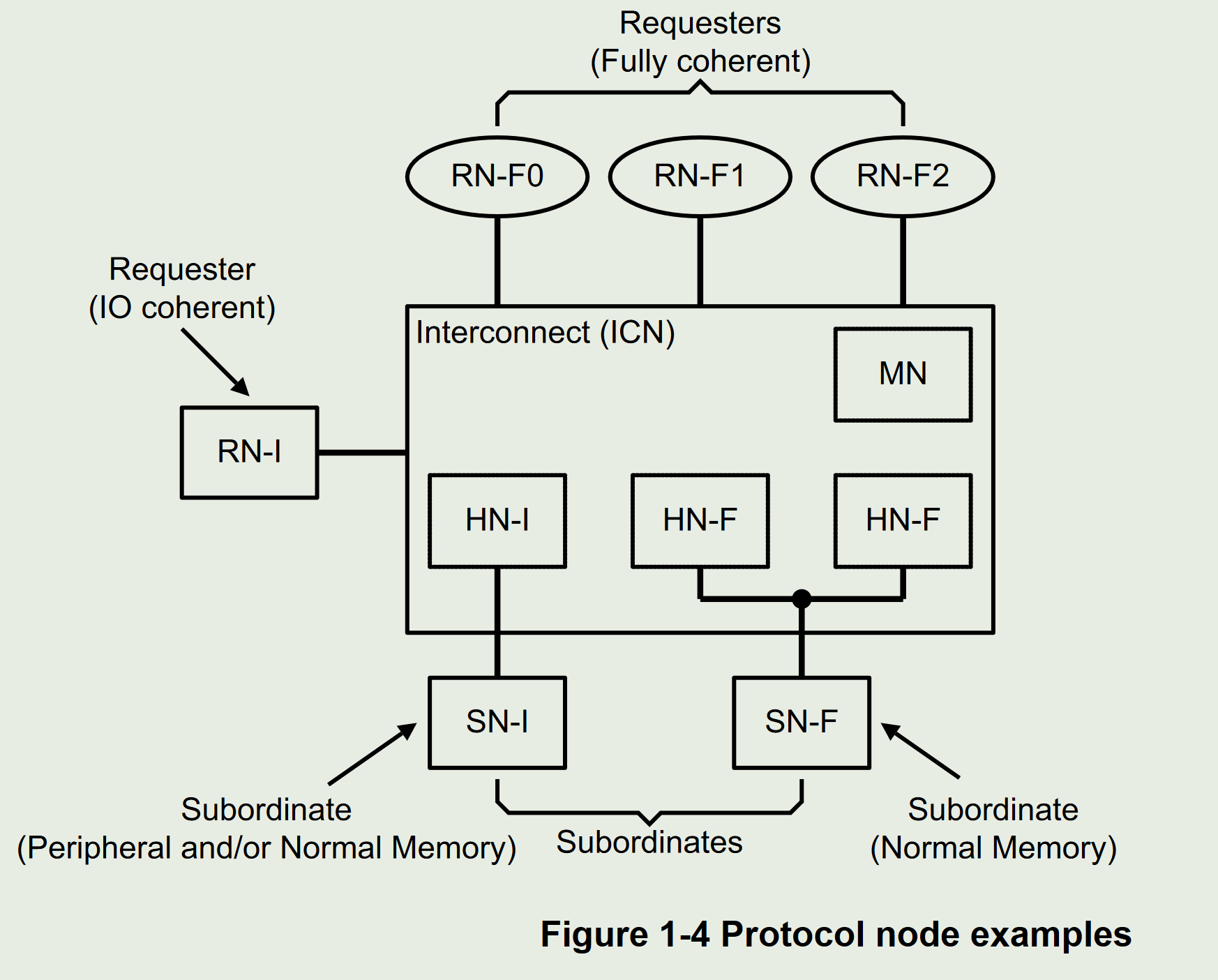
1.7 数据源
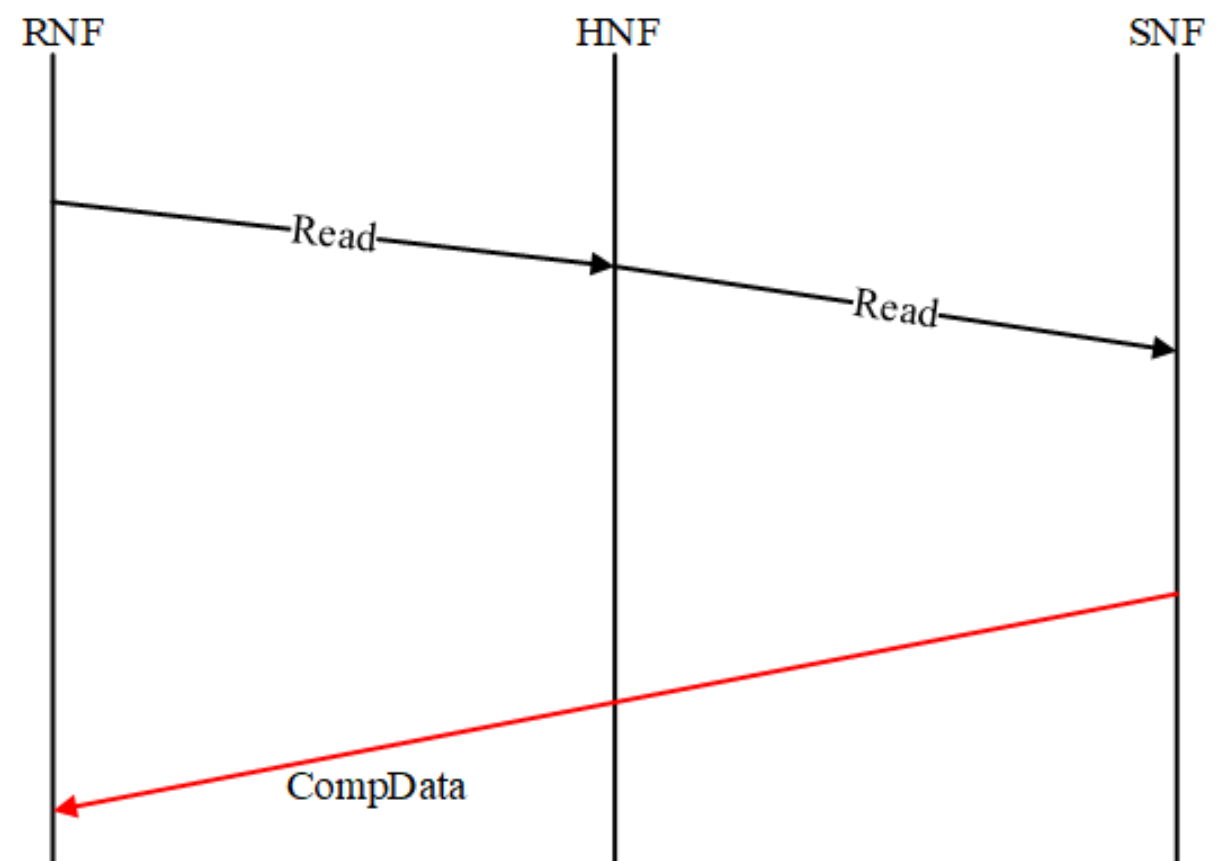
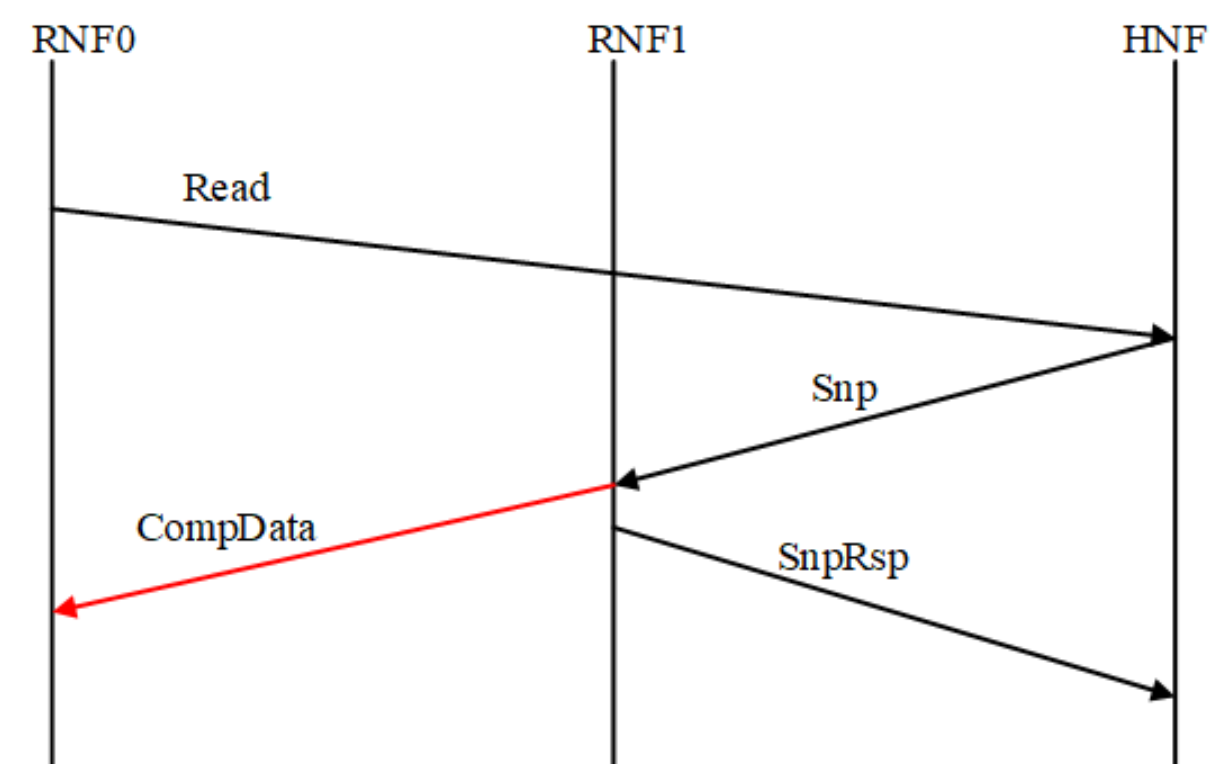
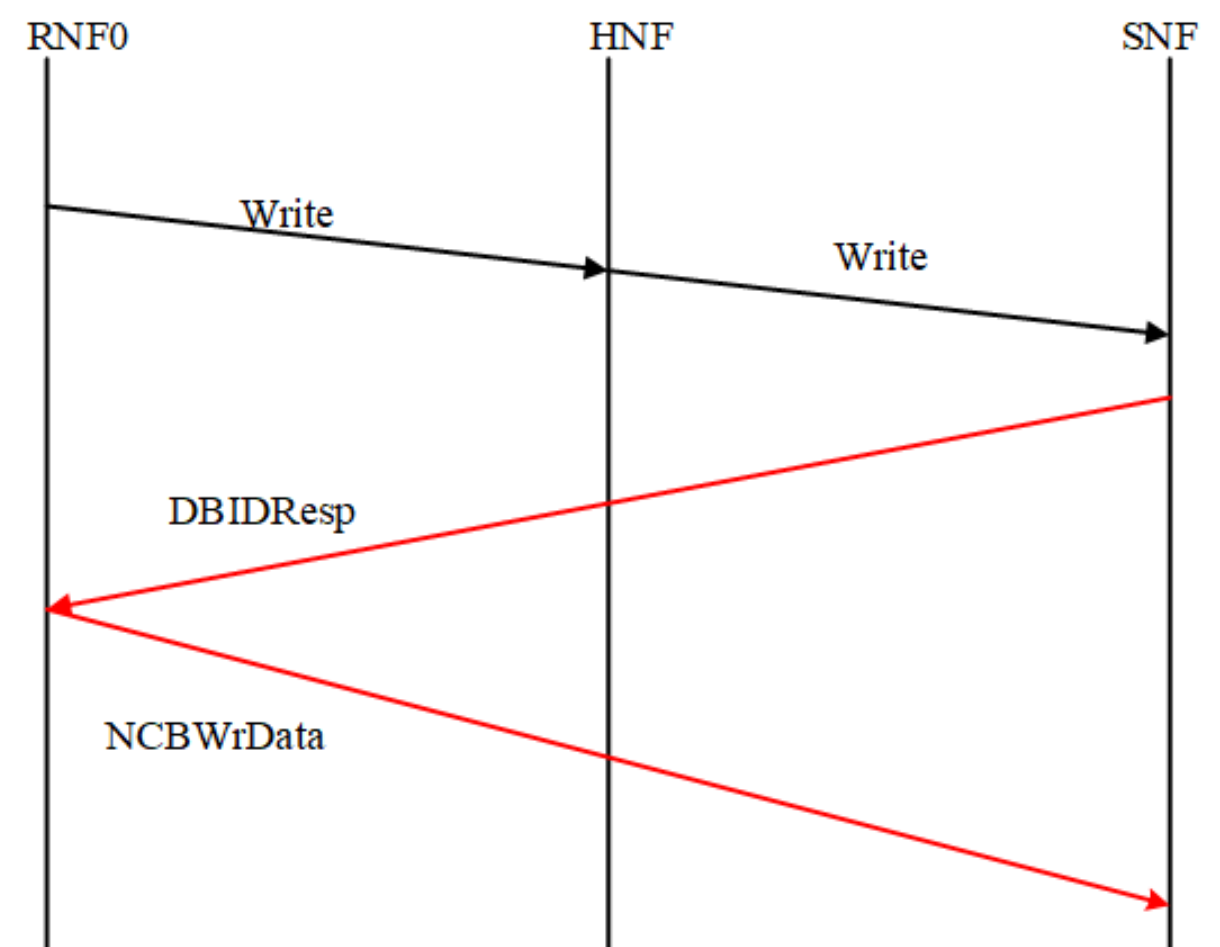
如果数据提供者能够将数据响应直接转发给请求者而不是通过 Home,则可以删除在此读取事务流中获取数据的跃点。
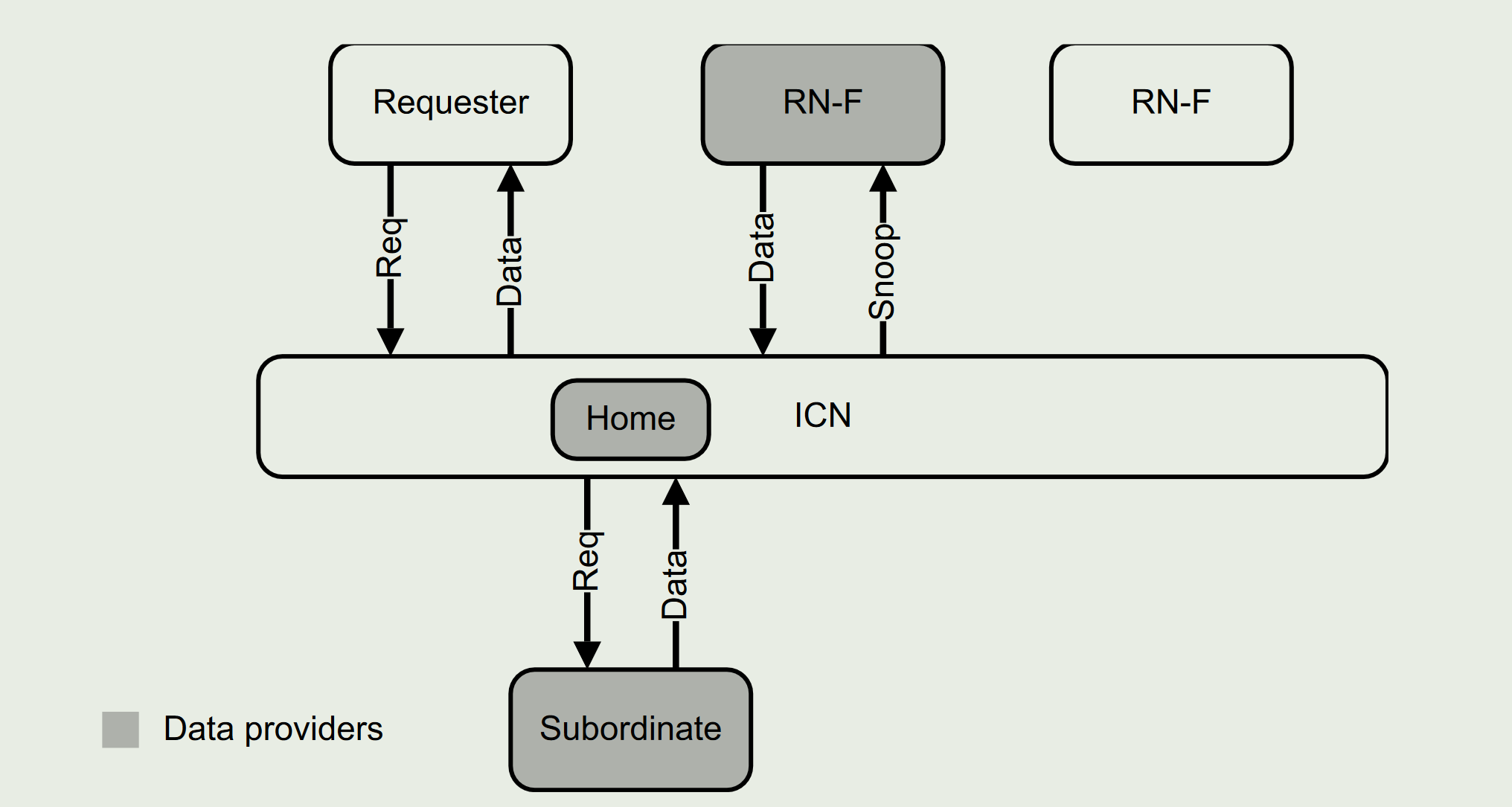
Direct Memory Transfer (DMT) 是有条件的,因为有些事务的响应必须要回到 HNF(Home 节点),后面深究。
Direct Cache Transfer (DCT) 读取事务流中的数据提供者必须通知 Home 它已经向请求者发送了数据,在某些情况下,它还必须向 Home 发送数据副本。
Direct Write-data Transfer (DWT)
chap2 Transactions
待看
chap4 一致性协议
个人认为这里用到的时候查阅就可以了
下面是request types–各种transactions
下面总结的有点烂 建议看上面文章链接4.2.1 Read transactions
有以下特性:
- 1.Requester会获得一个数据响应;
- 2.会导致数据在系统其它agents之间的搬移;
- 3.会导致Request中cacheline状态的改变;
- 4.会导致系统中其它Requesters的 cacheline状态改变,
read类型的操作分为两类,non-allocating read 和allocating read

TMP TRASH
> #### 4.2.1.1 **non-allocating read** {: width="972" height="589" } | read supporting transactions | description | |---------|------------------------------| | **ReadNoSnp** |- RN请求去Non—snoopable address region获取数据
- 不需要snoop其它RN或者HN访问任意空间
| | **ReadNoSnpSep** |- 与ReadNoSnp类似,只是告知Completer只需要返回data response
| | **ReadOnce** |- 该命令访问的是snoopable空间,用以获取一份数据,但是该数据不会在当前的RN中缓存
- 也就是说,只是用一下该地址的数据;无需allocate到本地私有cache.
| | **ReadOnceCleaninvalid** |- 访问的是snoopable的地址空间;获取该地址的数据
- 建议其他拥有该地址copy的RN,其状态变成invalid,但不是强制的
- 如果dirty的cacheline被invalid了,需要将数据写入主存
- 当application想要该地址的数据仍然是有效的,但是近期又不使用的时候,可以使用该命令,而不是readonce/readoncemakeinvalid
- 此命令可以提高cache效率,因为其主动将近期不使用的cache line从cache中invalid掉;
- 此命令不能代替CMO (Cache Maintenance Operation)操作,因为它不保证所有的cachline都变成了invalid;
- 由于这个命令会导致cache line的invalid,因此,当系统中有其他人在使用exclusive访问时,需要小心。
| |**ReadOnceMakelnvalid**|- 访问的是 snoopable 的地址空间;获取该地址的数据;
- 建议其他拥有该地址副本的 RN,其状态变成 invalid,但是不是强制的;
- 如果 dirty 的 cache line 被 invalid 了,则直接丢弃数据;
- 当 application 知道后续这个地址的数据不再使用,即不再需要该最新数据之后,可以发送该命令;
- 此种命令在上述场景下,减少了 writeback 数据到 DDR 的带宽和时间;
- 此命令不能代替 CMO(Cache Maintenance Operation)操作,因为它不保证所有的 cache line 都变成了 invalid;
- 由于这个命令会导致 cache line 的 invalid,因此,当系统中有其他人在使用 exclusive 访问时,需要小心;
- 此命令必须保证,在返回响应之前,先将该 cache line invalid 掉,并且在这个时刻点之后的所有写,都不受此次 invalid 的影响。
#### 4.2.1.2 **allocating read** 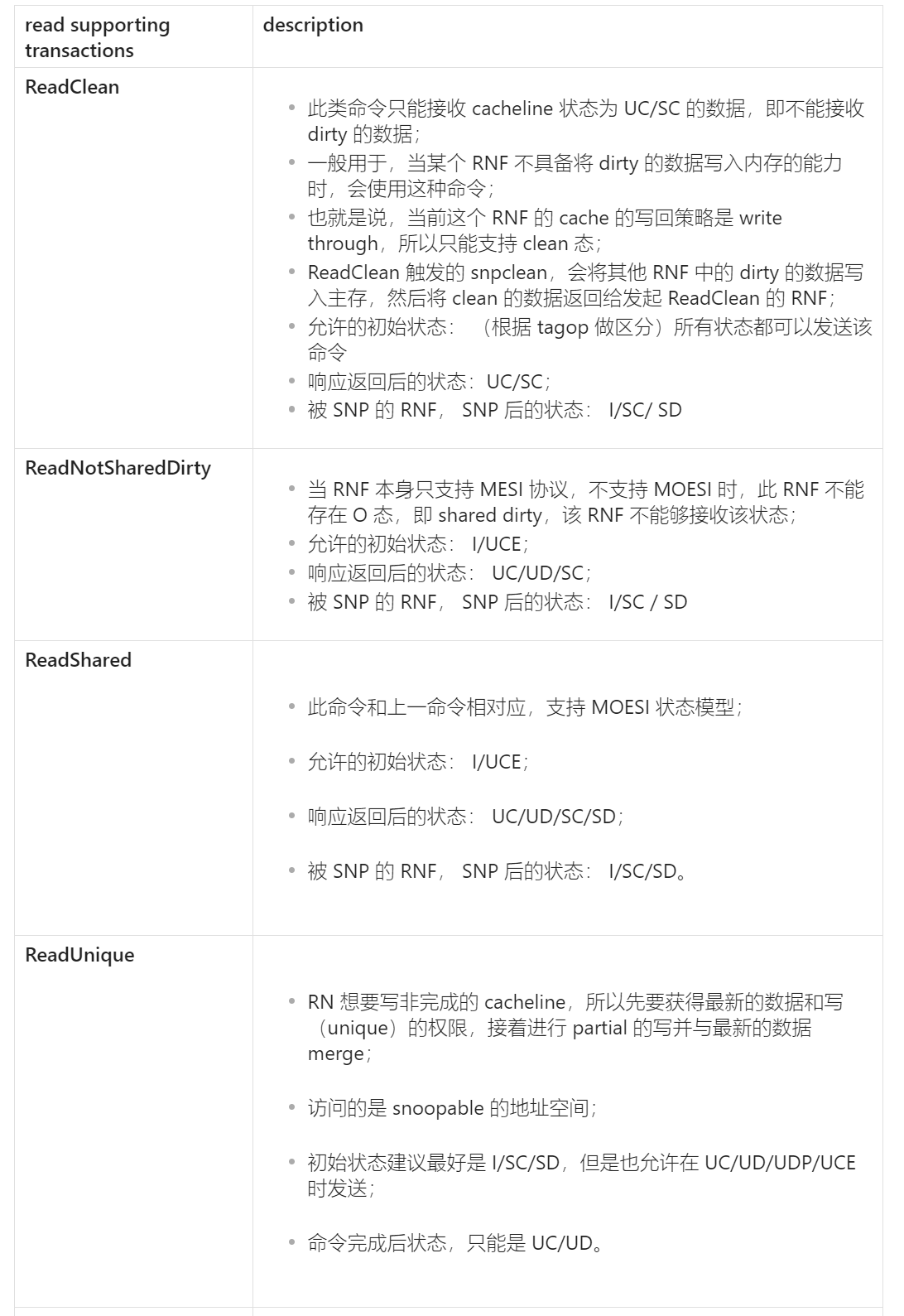{: width="972" height="589" } {: width="972" height="589" } non-allocating read
| read supporting transactions | description |
|---------|------------------------------|
| **ReadClean** |- 此类命令只能接收 cacheline 状态为 UC/SC 的数据,即不能接收 dirty 的数据;
- 一般用于,当某个 RNF 不具备将 dirty 的数据写入内存的能力时,会使用这种命令;
- 也就是说,当前这个 RNF 的 cache 的写回策略是 write through,所以只能支持 clean 态;
- ReadClean 触发的 snpclean,会将其他 RNF 中的 dirty 的数据写入主存,然后将 clean 的数据返回给发起 ReadClean 的 RNF;
- 允许的初始状态: (根据 tagop 做区分)所有状态都可以发送该命令
- 响应返回后的状态:UC/SC;
- 被 SNP 的 RNF, SNP 后的状态: I/SC/ SD
|
| **ReadNotSharedDirty** | - 当 RNF 本身只支持 MESI 协议,不支持 MOESI 时,此 RNF 不能存在 O 态,即 shared dirty,该 RNF 不能够接收该状态;
- 允许的初始状态: I/UCE;
- 响应返回后的状态: UC/UD/SC;
- 被 SNP 的 RNF, SNP 后的状态: I/SC / SD
|
| **ReadShared** |- 此命令和上一命令相对应,支持 MOESI 状态模型;
- 允许的初始状态: I/UCE;
- 响应返回后的状态: UC/UD/SC/SD;
- 被 SNP 的 RNF, SNP 后的状态: I/SC/SD。
|
|**ReadUnique** |- RN 想要写非完成的 cacheline,所以先要获得最新的数据和写(unique)的权限,接着进行 partial 的写并与最新的数据 merge;
- 访问的是 snoopable 的地址空间;
- 初始状态建议最好是 I/SC/SD,但是也允许在 UC/UD/UDP/UCE 时发送;
- 命令完成后状态,只能是 UC/UD。
|
| ReadPreferUnique |- 访问的是 snoopable 的空间,想要获得一个 unique 的 cacheline;
- 使用场景上,发送此命令,是希望获得 unique 状态,但是如果不是 unique 的,也允许;
- 发送该命令时,其他 RN 正在对这个地址进行 exclusive 的访问,此时返回的状态是 shared;
- 允许返回的状态一直是 shared;
- 此命令主要是用来提高 exclusive 访问的效率,具体提升点在 exclusive 访问处描述。
|
| MakeReadUnique |- 访问 snoopable 的空间,想要获取该 cacheline 的 unique 状态;
- 典型使用场景是当前 RN 有该 cacheline 的 shared copy,想要获得写该 cacheline 的权限;
- 此命令分为 exclusive/非 exclusive 两种。
|
发送多少snoop:stach和fwd只能发往1个RN-F
附录 术语
- PoC:管理一致性,所有可以访问内存的agent都保证看到内存的相同位置的副本。在HN中需要
- PoS:管理多个memory请求的顺序,在HN中需要
- PoP:管理内存通断电情况下的一些操作
- Snoopee:接受snop的node,即RN-F
- 新术语 Requester(请求者)在旧文档中与 master(主设备)同义
- 新术语 Subordinate(从属设备)在旧文档中与 slave(从设备)同义
- cache HIT
- Read through,即直接从内存中读取数据;
- Read allocate,先把数据读取到Cache中,再从Cache中读数据。
- Write-through(直写模式)在更新数据时,同时写入Cache和内存。简言之,把数据同时写到Cache和内存中。
- Write back:数据首先写入缓存,而不是直接写入主存。当缓存行被替换时,才将数据写回主存。这种策略减少了主存的写操作次数,提高了性能。
- cache-misses :目标地址不在缓存中
- Write allocate:会先把该地址的数据块加载到缓存,然后再进行写操作,然后再通过flush方式写入到内存中;写缺失操作与读缺失操作类似。
- write no-allocate:并不将写入位置读入缓存,直接把要写的数据写入到内存中。这种方式下,只有读操作会被缓存。
Write Allocate与Write Back经常一起使用,No Write Allocate与Write Through经常一起使用。
- snoop filter:在总线中为设备维护标志位,来标识某些core中是否存在这个cacheline,不存在就不用发起snoop请求了
- TxnID:除了PrefetchTgt,这个ID指向唯一的Request,在收到完全响应或者Retry之后,可重用ID
- ReturnNID:SN返回数据响应, Persist响应或TagMatch响应的节点ID
- ReturnTxnID:SN返回数据响应, Persist响应或TagMatch响应的TxnlD
Deep:置位后,写操作到达PoP和最终目的,才能提供Persist响应
- MESI协议,是一种叫作 写失效(Write Invalidate)的协议
- M:代表已修改(Modified),“脏”的Cache Block。
- E:代表独占(Exclusive)
- S:代表共享(Shared)
- I:代表已失效(Invalidated) - MOESI协议引入了一个O(Owned)状态,并在MESI协议的基础上,进行了重新定义了S状态 对应CHI:M=UD、O=SD、E=UC、S=SC
- O位为1表示在当前Cache 行中包含的数据是当前处理器系统最新的数据拷贝,而且在其他CPU中一定具有该Cache行的副本,其他CPU的Cache行状态为S。如果主存储器的数据在多个CPU的Cache中都具有副本时,有且仅有一个CPU的Cache行状态为O,其他CPU的Cache行状态只能为S,状态为O的Cache行中的数据与存储器中的数据并不一致。
- S位。在MOESI协议中,S状态的定义发生了细微的变化。当一个Cache行状态为S时,其包含的数据并不一定与存储器一致。如果在其他CPU的Cache中不存在状态为O的副本时,该Cache行中的数据与存储器一致;如果在其他CPU的Cache中存在状态为O的副本时,Cache行中的数据与存储器不一致。
- 处于E(UC)态,收到snoop请求,不需要返回数据给HN或者forward数据给RN。
- 处于M(UD)态,收到snoop请求,需要返回数据给HN或者forward数据给RN。