GPGPU
点击查看详细内容
在三维的位置看矩阵乘法 {: width="400" height="auto" } ## 1. vortex笔记 ### 1.1. Wavefront Scheduler 1) a set of wavefront masks 2) a wavefront table that includes privated information for each wavefront. The scheduler uses four thread masks: 1) an active wavefront mask 2) a stalled wavefront mask indicates which warps should not be scheduled temporarily, 3) a barrierd mask for stalled wavefronts waiting at a barrier instruction 4) a visible wavefront mask to support hierarchical scheduling policy . 在每个周期中,调度器从visible wavefront mask中选择一个wavefront,并将该wavefront标记为无效。当visible wavefront mask全为零时,通过检查当前哪些wavefront处于`活跃且未被阻塞状态`来重新填充活跃掩码。 ### 1.2. 线程掩码(Thread Mask)和IPDOM栈来处理分支分歧(divergence) **IPDOM栈** 一个硬件栈结构,用于保存分支分歧时的上下文信息(如线程掩码、程序计数器PC等) **当执行`split`指令时(如遇到分支分歧)**: 1) 将当前活跃线程的掩码压入IPDOM栈,标记为`fall-through(else的指令)` 2) 检查每个线程的predicate,“条件为假”的线程会被推入IPDOM栈,栈条目包含这些线程的掩码和分支目标地址(`next PC`,即条件为假时分支的起始地址,如`else`块的入口) 3) 更新线程掩码,仅保留条件为真的线程,继续执行if内的代码块 例子: ```c if (x > 0) { // split指令 A(); // True分支 } else { B(); // False分支 } C(); // 收敛点(join) - 将当前所有活跃线程的掩码作为`fall-through`压栈,对应A->C - 将`False`线程的掩码和`B()`的入口地址压栈 - 掩码更新为`True`的线程,执行`A()` - 如果A()执行->join,弹出`False`线程的掩码和`B()`的入口地址 - 反之,弹出`fall-through`,恢复所有线程活跃,继续执行C ``` ### 1.3. Wavefront Barriers (1)Barrier Table: - **计数器(Counter)**:记录尚未到达该屏障的Wavefront数量。 - **阻塞掩码(Stalled Mask)**:记录因等待该屏障而被阻塞的Wavefront。 - **初始状态**:4个Wavefront需要同步。 - **计数器**=4,**阻塞掩码**=0000(无阻塞)。 - **Wavefront执行屏障指令**: 1. **计数器减1**:例如第一个Wavefront到达后,计数器变为3。 2. **阻塞当前Wavefront**:将对应掩码位置1(如0001)。 - **所有Wavefront到达时**(计数器=0): - 释放所有被阻塞的Wavefront(掩码清零),恢复执行。 (2)Global Barriers:多核配置 barrier ID的MSB=1代表全局屏障(需所有核心的Wavefront参与), MSB=0:本核心内的屏障。 ### 1.4. Hardware Texture Filtering 硬件实现了可配置的纹理单元(texture unit)以支持图形处理,每个纹理单元在给定的(u, v)源坐标和指定纹理细节层级的lod操作数上,实现纹理的点采样和双线性采样。高级Filtering算法如trilinear or anisotropic filtering则以伪指令形式实现。 1) 配置CSR寄存器,设置纹理状态参数(如Wrap模式、Stride步长、Mipmap级数等)。 读取Mipmap对应的**纹理基地址**和元数据。 2) 根据u v lod进行**纹素地址计算**,输出:所有线程的纹素地址(单个或四元组)+元数据(Wavefront-ID、格式等) 3) **内存访问去重(Deduplication)**,随后恢复线程原始请求的数量 4) 纹理采样,将纹素从存储格式(如压缩纹理或自定义格式)转换为标准的RGBA数值,进行**插值(Bilinear Interpolation)** ### 1.5. 高带宽缓存(High-Bandwidth Caches) 传统GPU是如何减少Bank冲突的?Warp 中所有线程同时发出的共享内存访问,如果有线程们访问到相同 bank 或者访问模式无法并行完成,硬件就会将其拆分成若干轮次,每一轮只处理一部分线程的访问请求,直到整个 Warp 的所有访问都完成为止。这样虽然保证了正确性,但会增加访问延迟,导致性能下降。 为了解决多端口存储问题: 1) 虚拟多端口。例如:基础频率为F,存储器以2F运行,奇数周期处理请求A,偶数周期处理请求B 2) Live-Value Table(LVT),其思想是“写入复制 + 读出合并” 1) 与其为每个地址都做真正的多端口支持,不如**将存储器进行“复制”,每个写端口独占一个物理副本** 2) 每个端口都有自己的存储副本,存储空间每个地址在 LVT 表中都对应一行(或若干位)信息 3) LVT 表里存储了“最后一次写 A 是由哪个写端口执行的”,也等效地表示:“**地址 A 最新数据**位于哪个副本”。 4) 需要注意,当多个端口同时写同一个地址的时候,需要软件控制不发生或者硬件设置仲裁优先级,保证仅有一个端口实现写更新。多读的时候怎么办? --- **Bank选择器(Bank Selector)**: - 根据地址将请求分配到不同Bank(如低位取模)。 - **冲突解决**:同一Bank的请求序列化;若开启虚拟端口,合并同一缓存行的请求。 - 虚拟端口的选择:检查访问的地址是不是匹配其访问的bank中的地址,如果命中,则在时间上均匀分配给虚拟端口 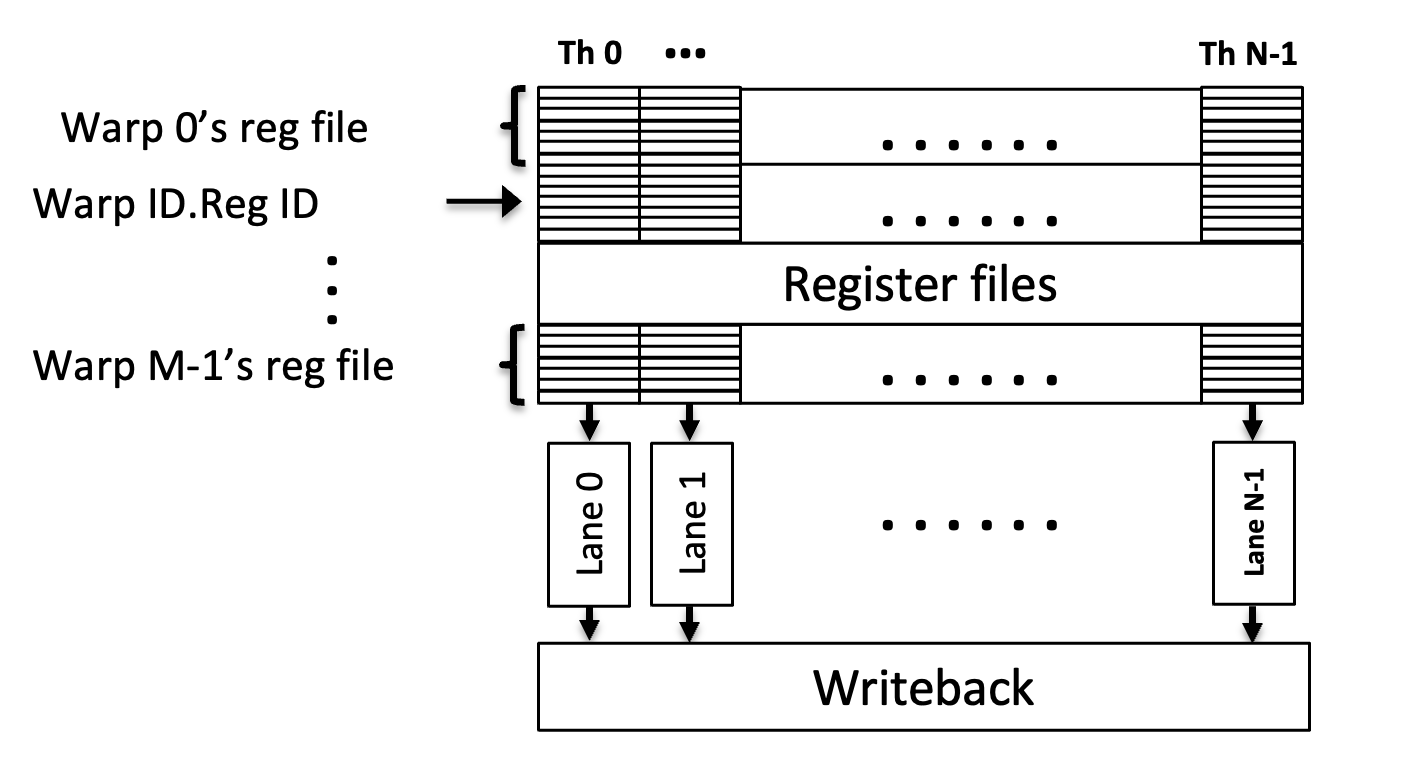{: width="400" height="auto" } - All threads in a warp read the register values in parallel. - Register is indexed with register ID, warp ID 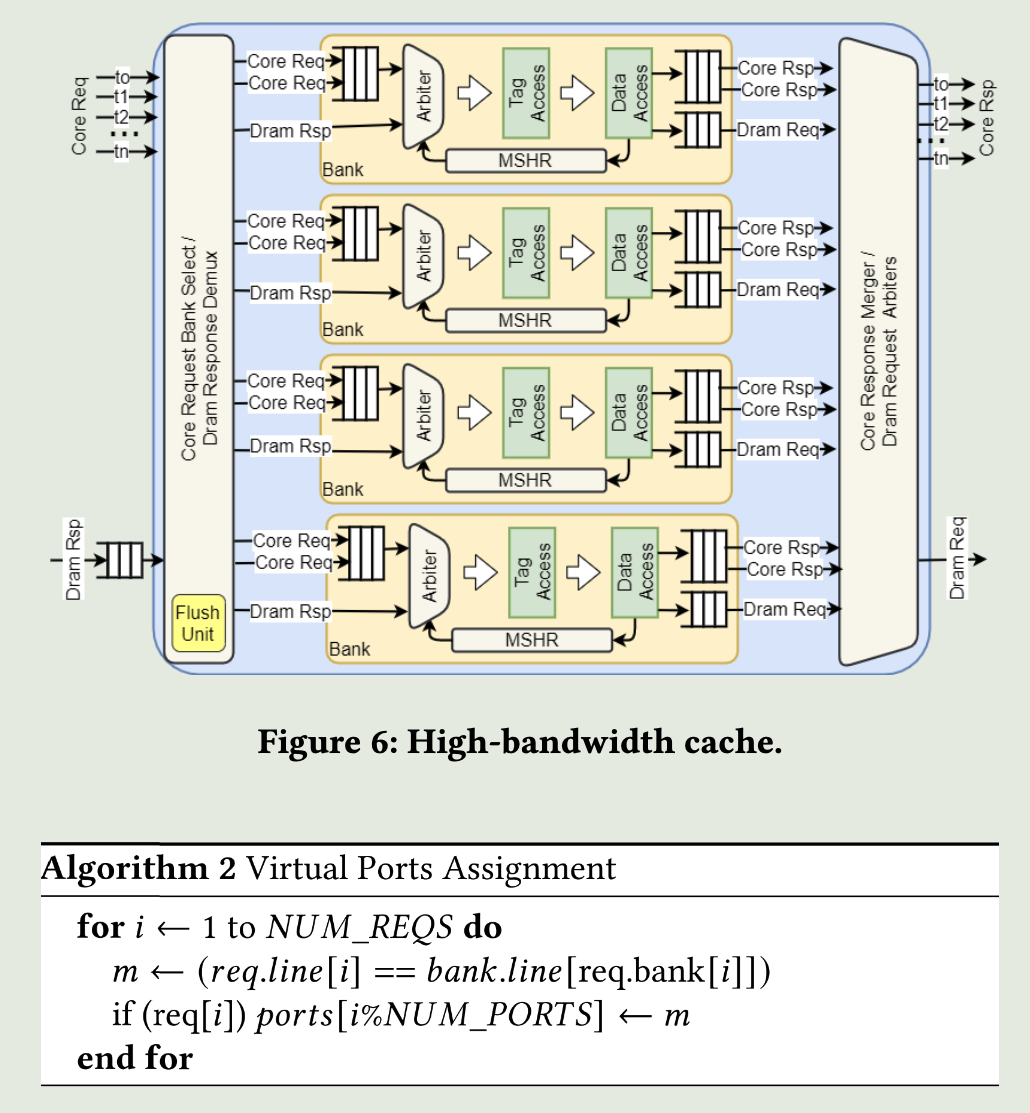{: width="400" height="auto" } MSHR(miss status holding reg):记录“哪个请求正在等待从内存取回数据、缺失在哪个地址”等信息的硬件结构。若要实现多端口或“虚拟多端口”读写,we only need to store the word offsets for each port in the MSHR 访存返回的是full block,可以满足同一时刻多个字偏移的读请求 **缓存中的死锁问题**: MSHR满+有新的请求进入 or Memory Request Queue也是,反压解决 ### 1.6. GPU的分支操作 GPU是SIMT的,一个warp中的所有thread执行的都是同一条指令,所以需要用split来将当前的线程掩码(记录哪些线程满足条件)压入ipdom stack;**将另一条路径(即“未取分支”)的 PC 压入栈** • 同一块硬件需要先执行 taken path 或 not-taken path,然后“切换”到另一条路径,再执行完后汇合。 “join”会从“ipdom stack”中**弹出之前保存的线程掩码和 PC**,让所有线程最终回到同一个控制流点,继续后续指令。 ## 2. code的层次结构 ### 2.1 基础的AXI component - VX_axi_adapter将mem的req通过streaming的形式,将来自 Vortex 侧的多端口请求接口转换为标准的 AXI 接口形式。同时将多bank的返回数据也转换成 Vortex 侧的多端口响应接口 ### 2.2 cache的设计 [Vortex的硬件架构和代码结构分析](https://blog.csdn.net/weixin_41029027/article/details/140276734?spm=1001.2014.3001.5502) 一个4路组相联的cache设计,访存地址分为Tag、Index、Block Offset。Index用于选中4路中的哪一行,也就是选中Tag Memory中某一行,随后使用Tag来确定是否命中了4路中的某一路,如果命中,则接下来在Data Memory对应的路中根据Block offset选中某个cacheline data block 作者采用了`Tag Memory`和`Data Memory`的串行流水线设计 #### 2.2.1 VX_cache_wrap >当系统需要针对非缓存地址(non-cacheable)或部分请求采用绕过缓存的方式时,bypass 模式允许这些请求经过一个专门的绕过路径,而不是走完整的缓存逻辑。 >passthru 模式用于完全绕过缓存功能,将所有内存请求直接传递到下一级接口。这种模式通常用于系统测试、调试或当缓存功能被禁用时使用。 • 当BYPASS_ENABLE时,模块会实例化 VX_cache_bypass,将请求数据转换后送入下一层总线接口(mem_bus_tmp_if),跳过传统缓存逻辑。 • 当不走旁路时(PASSTHRU 为 0),核心请求经过 core_bus_cache_if 后进入实际的缓存模块(VX_cache),缓存内部对数据进行命中检测、替换、存储等处理,并输出处理后的数据到 mem_bus_cache_if。 - bypass设计: ## append、GPU的基础知识点 一个简易版本的架构区别: 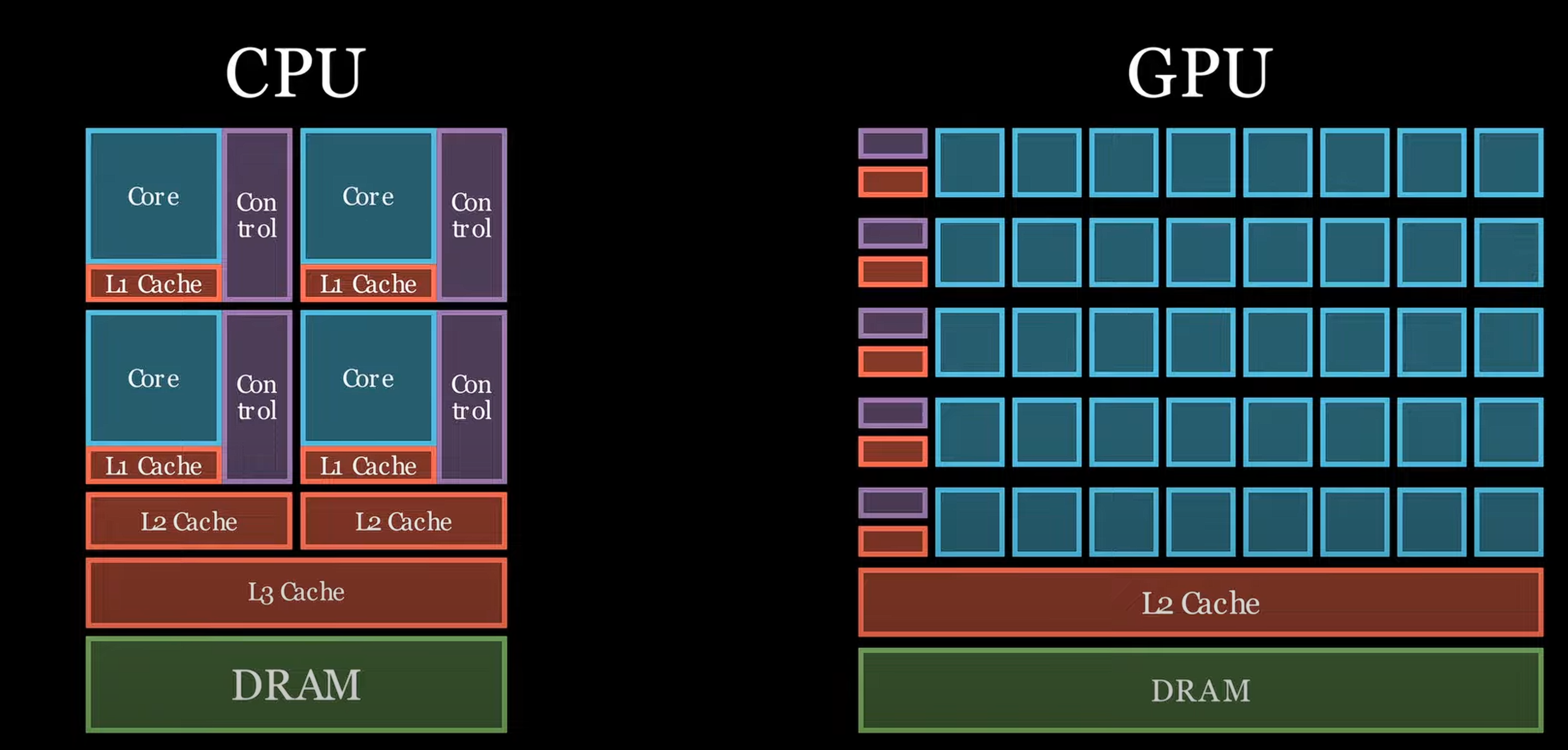{: width="400" height="auto" } GPU索引包含blockIdx和threadIdx,blockIdx是在线程之间共享的 -**Warps** :The PC is shared; maintain thread mask for Writeback,同一warp内所有线程共用一个程序计数器(PC),因此它们在同一时刻执行相同的指令。由于条件分支或其他条件,GPU会维护一个线程掩码,在执行写回(Writeback)阶段时,只有那些处于活动状态的线程会将计算结果写回到寄存器或内存中。 there are thread groups that share control units,and those are streaming multiprocessors. the core components of our gpu 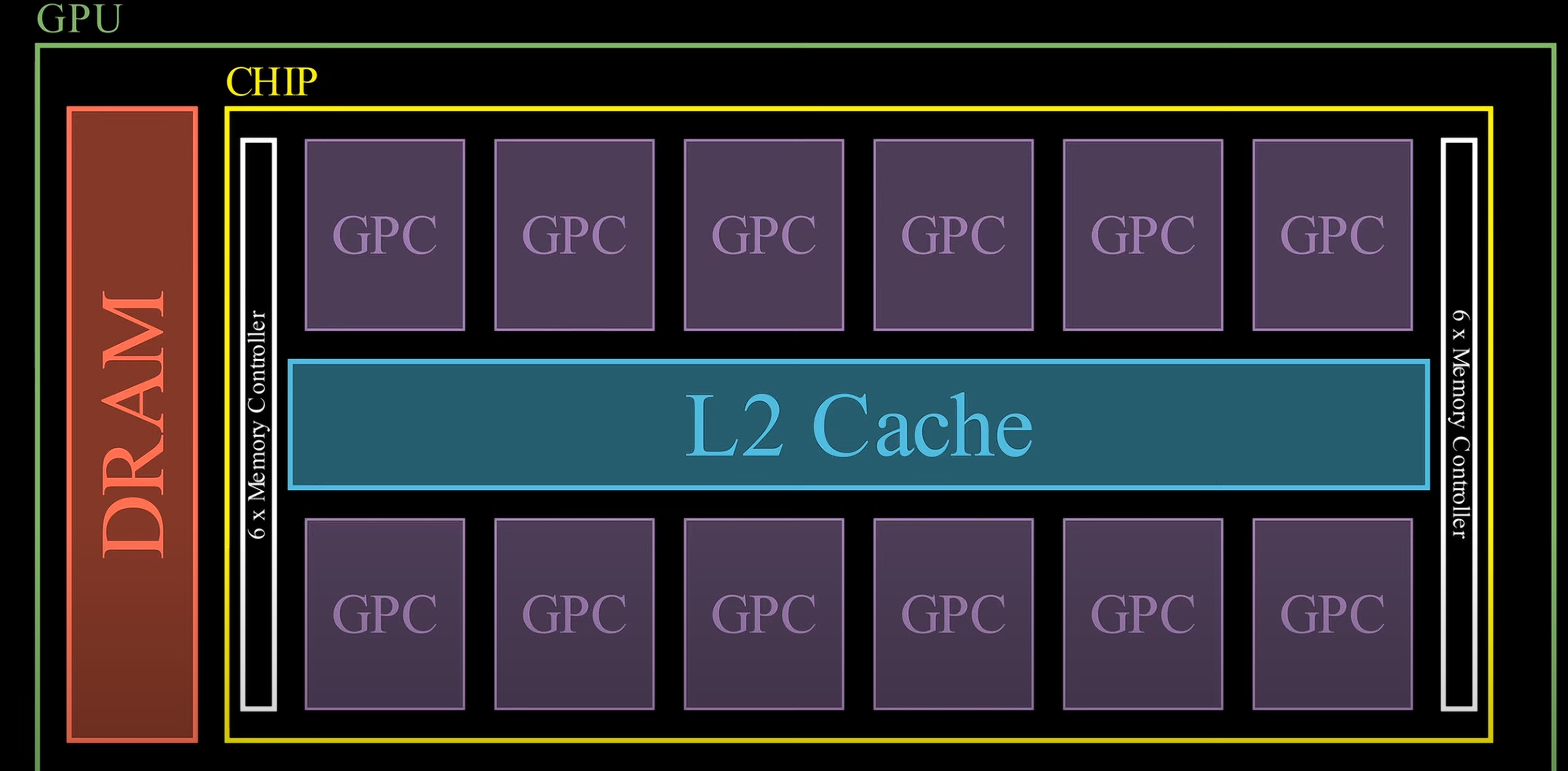{: width="400" height="auto" } 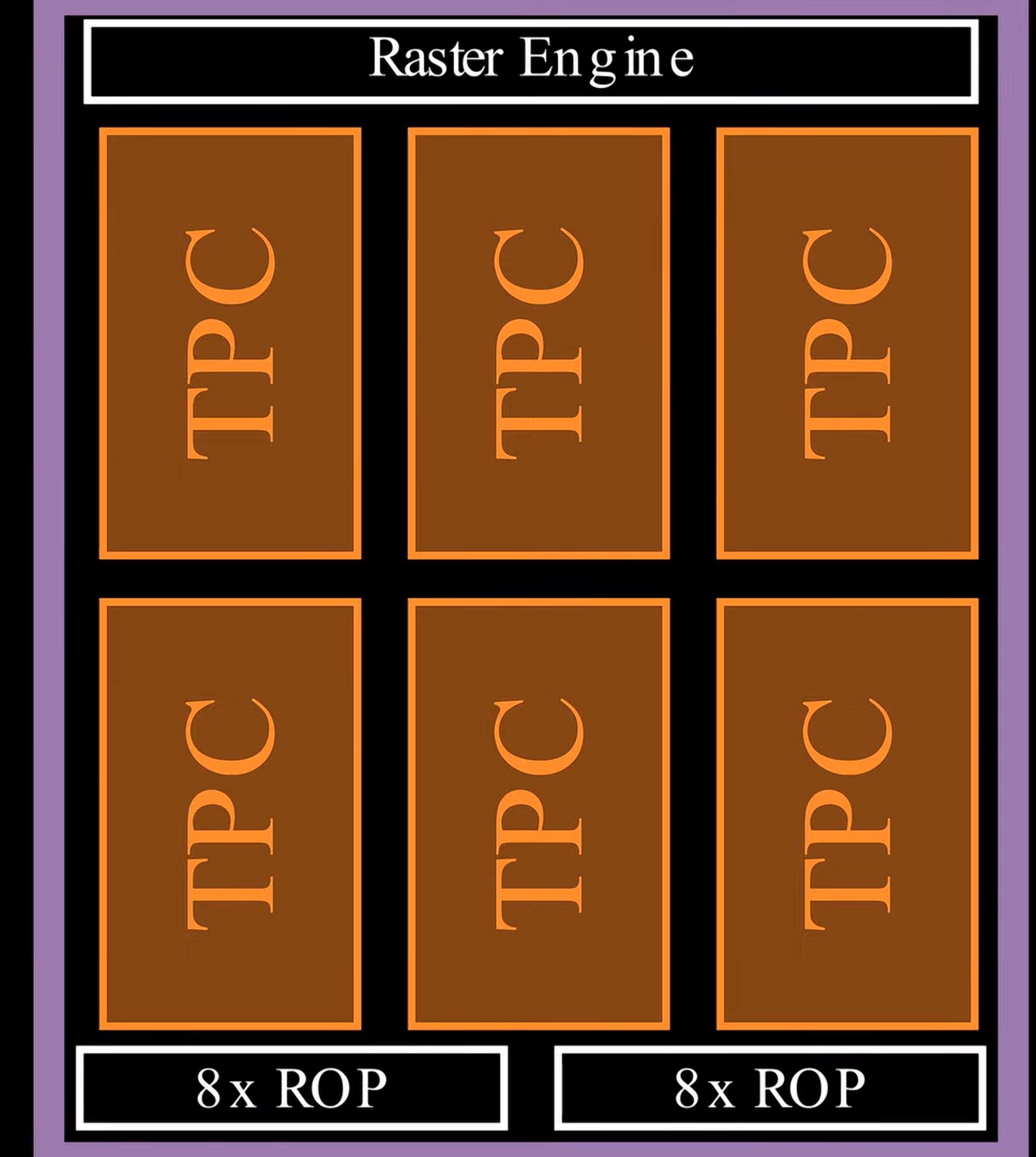{: width="400" height="auto" } 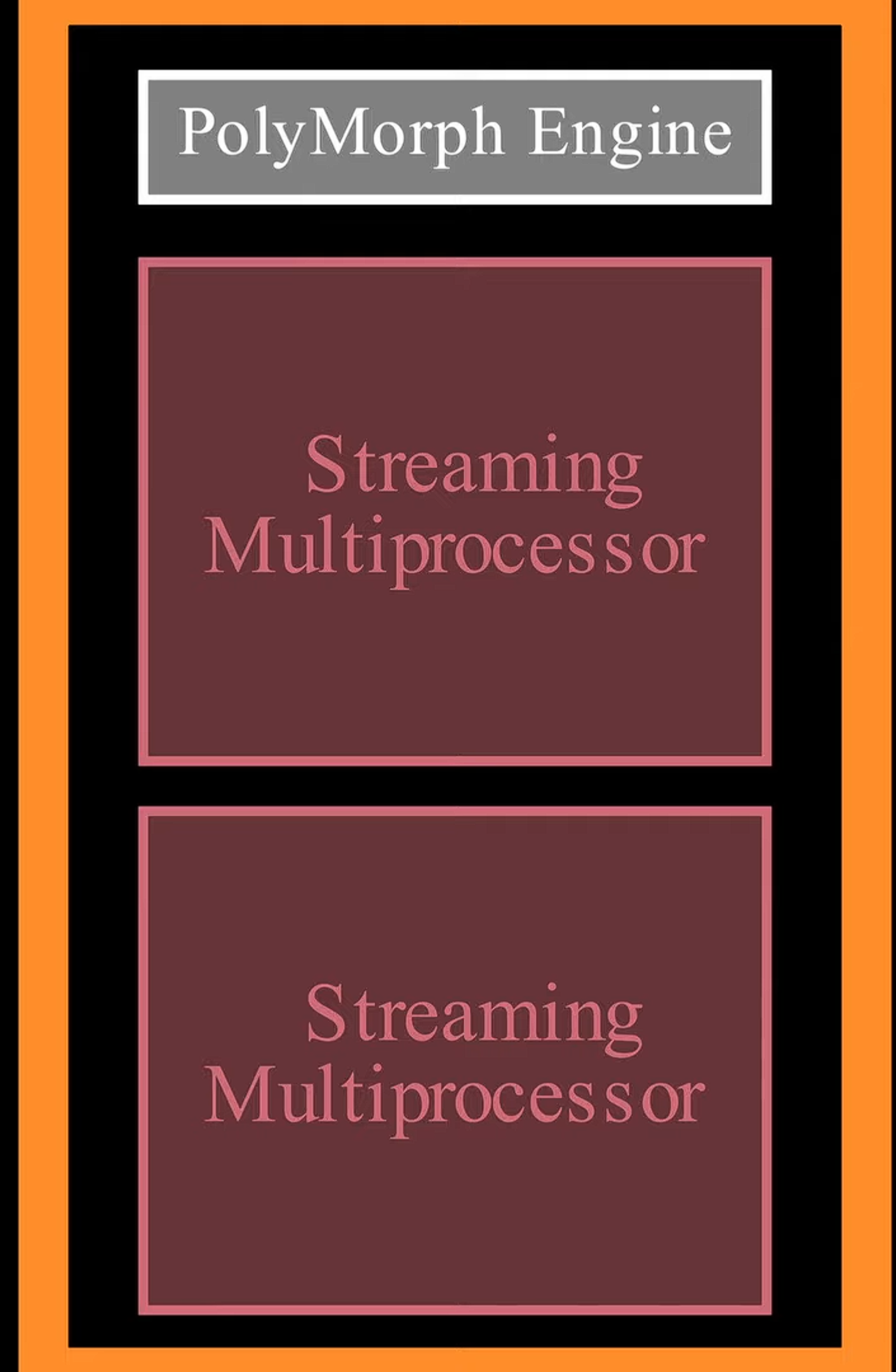{: width="400" height="auto" } {: width="400" height="auto" } {: width="400" height="auto" } 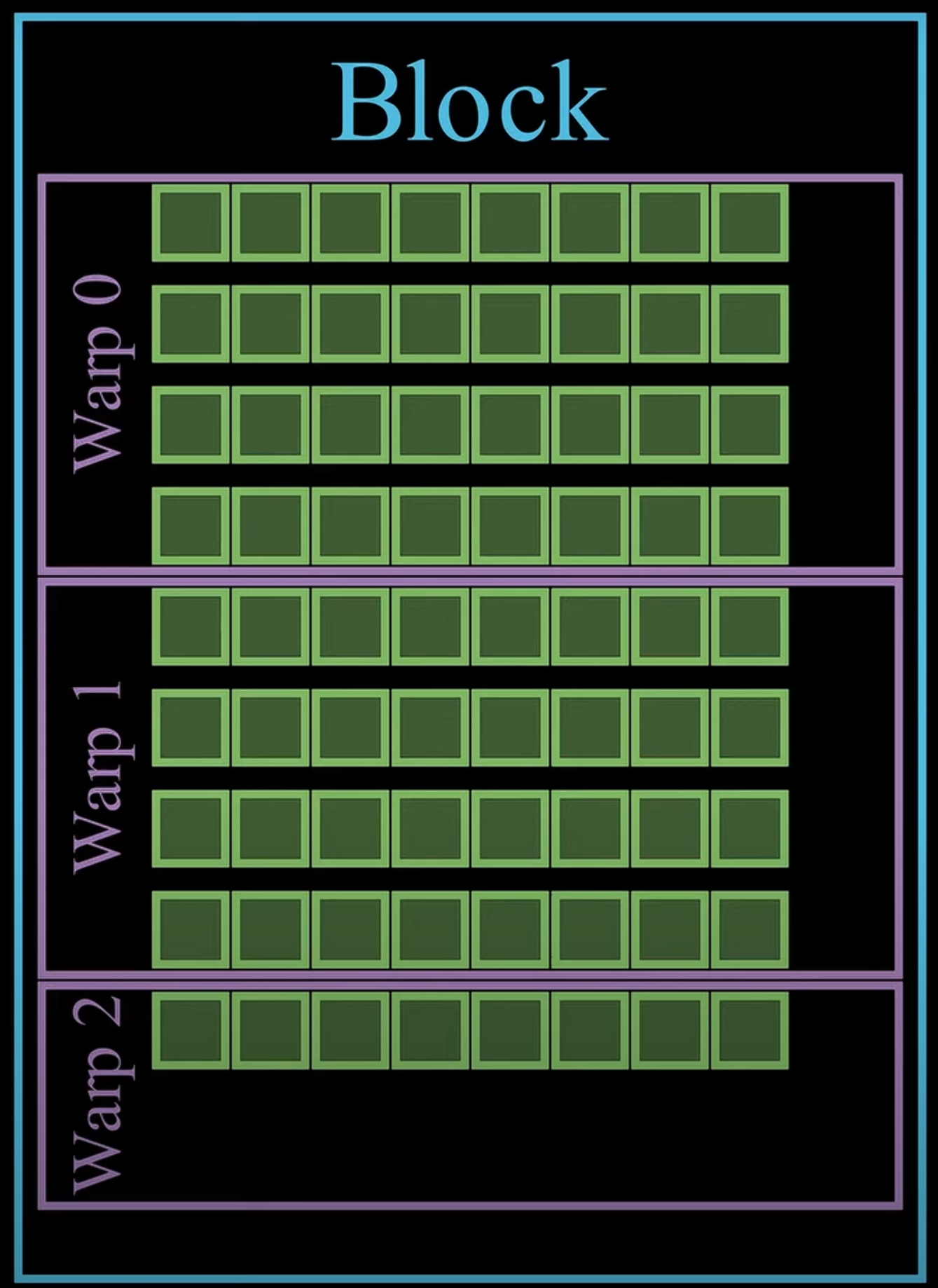{: width="400" height="auto" } 1. Raster Engine 2. ROP 3. PolyMorph Engine 4. RT core 5. TEX unit 6. Warp Scheduler 7. Dispatch Unit 8. SFU This post is licensed under CC BY 4.0 by the author.