noc(1)--《On Chip Network》
- 这是一个Network_generate tool该项目调用了Bluespec Compiler)
- AXI Verification IP (VIP) (xilinx.com)
- 路由知识内容
- 主要内容:Topology、Routing、Buffering、Flow Control
1. 基础概念
NoC包括各种通道、缓冲区、开关和控制器 片上网络的设计可以分解为以下一些组件:
- 拓扑结构:网络中节点和通道之间的物理布局和连接。
- 路由:对一个给定的拓扑结构,路由算法决定了一个信号通过网络到达目的地的路径,直接影响了网络的吞吐量和性能。
- 流量控制:信号通过网络时如何分配资源,如缓冲和通道带宽。
- 路由器微架构:一个通用的路由器微架构由输入缓冲、路由器状态、路由逻辑、分配器和一个Crossbar(或开关)组成,通常包括一个流水线以提高吞吐量,通过片上网络中每个路由器的延迟是通信延迟的主要因素。
- 链接结构:节点之间如何被连接的结构。
专有词
- 度数(Degree):每个节点的链路数
- 直径(Diameter):maximum distance between any two nodes
- 跳数(Hop count):the number of links it traverses一个消息从源头到目的地所需的跳数
2. 各种拓扑结构分析
- topology结构
2.1 直接拓扑结构: RINGS, MESHES, AND TORI
直接网络是每个终端节点(例如,芯片直接网络多处理器中的处理器核心或缓存)与路由器关联的网络;所有路由器既充当流量的源/接收器,又充当来自其他节点的流量的交换机
2.2 间接拓扑结构: CROSSBARS, BUTTERFLIES, CLOS NETWORKS, AND FAT TREES
- crossbar:
non-blocking as it can always connect a sender to a unique receiver.依旧需要仲裁,优点是大并发
- butterflies:
 butterflies的拖拓扑构 k-ary n-flies. Such a network would consist of $k^n$ terminal nodes (e.g., cores, memory), and comprises n stages of $k^{n-1} k×k$ intermediate switch nodes. peak injection throughput of 1 flit/node/cycle.
butterflies的拖拓扑构 k-ary n-flies. Such a network would consist of $k^n$ terminal nodes (e.g., cores, memory), and comprises n stages of $k^{n-1} k×k$ intermediate switch nodes. peak injection throughput of 1 flit/node/cycle.In other words, k is the degree of the switches, and n is the number of stages of switches. 蝴蝶网络的主要缺点是缺乏路径多样性以及这些网络无法利用局部性。由于没有路径多样性,蝶形网络在面对不平衡的流量模式时表现不佳,例如当网络一半中的每个节点向另一半中的节点发送消息时。
- Flattened Butterfly:
 展平butterflies的拖拓扑构
展平butterflies的拖拓扑构Each destination can be reached with a maximum of two hops. However, minimal routing can do a poor job of balancing the traffic load, so non-minimal paths have to be selected, thereby increasing the hop count.
- symmetric Clos network:
 对称结构
对称结构A disadvantage of a Clos network is its inability to exploit locality
- Tree

take advantage of locality
- crossbar:
3.流量控制
3.0 Buffering simpler Arb/Scheduling
- Efficient support for variable-size packets,通常要支持不同位宽大小的包(buffer用来缓存flit的大小块)
3.1 下面是基于Circuit Switching,message,packet,Virtual Cut-Through的流量控制

在
Virtual Cut-Through中,带宽和存储仍然以数据包大小为单位分配,只有在下一个下游的路由器有足够的存储空间来容纳整个数据包的情况下,数据包才能继续发送。当包的尺寸较大时,例如,即使节点x的缓冲区可以容纳5个flits中的2个,整个包的传输也会被延迟。
也就是说,tail的包会继续传输,直到达到头部拥塞的位置
3.2 基于flit的流量控制
虫洞(Wormhole)
同Virtual Cut-Through,不同的是虫洞将存储和带宽分配给flit而不是package,缓冲区更小。但一条链路会在路由器中的包的整个寿命期间都会被保留,包在停顿时其保留的物理链路都是空闲的。
NoC绝大多数采用虫洞流量控制,并利用虚拟通道进行流量控制
 虫洞的flit可能跨越多个Router,大量空闲的物理链路
虫洞的flit可能跨越多个Router,大量空闲的物理链路
3.3 虚拟通道(Virtual Channels)
最早是作为避免死锁的解决方案(原因很复杂,简单来说就是Enforcing switching to a different set of virtual channels on some “turns” can break the cyclic dependency of resources)被提出的,但也被用于缓解流量控制中的队列头部阻塞(head-of-line blocking)以提升吞吐量
阻塞在上面所有技术中都会出现,具体来说就是每个输入口都有一个队列,当队列头部的数据包被阻塞时,就会使排在后面的后续数据包停顿,即使停顿的数据包还有可用资源可以使用。 Virtual Channels首先在每个路由器上分配一个VC给head flit,其余的flit继承该VC,通过虚拟通道流量控制,不同的包可以在同一物理通道上交错传输。这种技术也被广泛用于解决死锁,包括网络内死锁以及协议级死锁。
 仲裁多个input queue,这样就可以缓解:下图中的HOL Blocking,同时可以支持流量优先级
仲裁多个input queue,这样就可以缓解:下图中的HOL Blocking,同时可以支持流量优先级 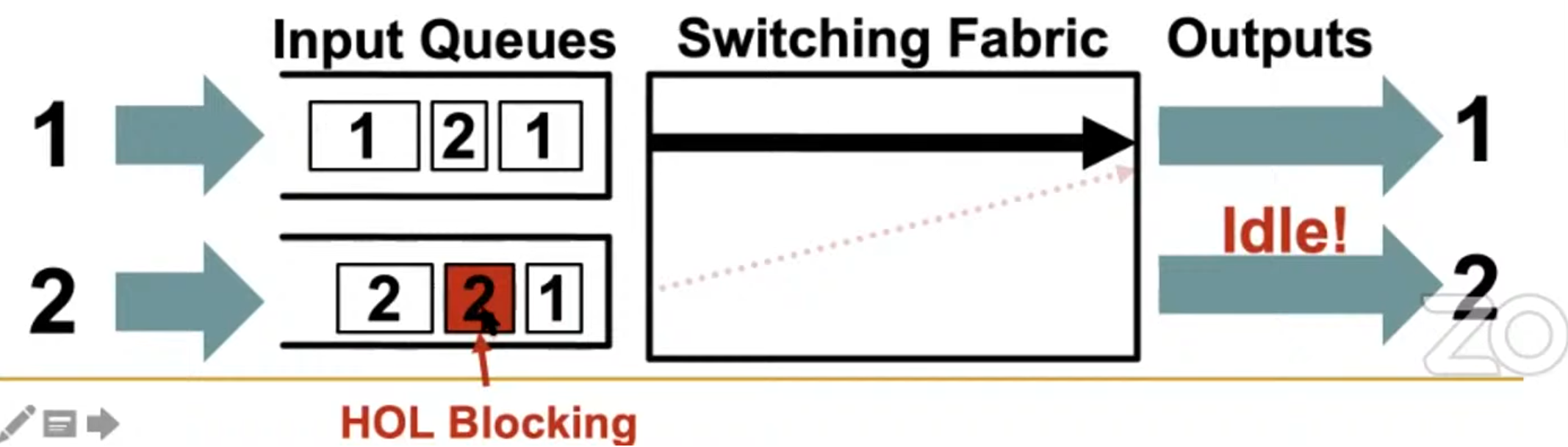
Computer Architecture - Lecture 20

上图是一个说明VC流量控制的例子。A最初占用VC 0,目的地是节点4,B最初占用VC 1,目的地是节点2。在T=0时,A和B都有flit在节点0的左边输入VC中等待。A的head flit被分配到路由器1的左边输入VC 0,并获得开关分配,在T=1时前往路由器1。在T=2时,B的head flit获得开关分配并前往路由器1,存储在VC 1,与此同时,A的head flit未能获得路由器4(A的下一条)的VC,节点4的两个VC都被其他包的flit占用。A的第一个body flit继承了VC 0,并在T=3时前往路由器1,与此同时,B的head flit可以在路由器2分配VC 0并继续前进。在T=4时,B的第一个body flit从head flit继承了VC 1,并获得开关分配,继续前往路由器1。到了T=7时,B的所有flit都到达了路由器2,但A的head flit仍然被阻塞,继续等待一个空闲的VC以前往路由器4。
 流量控制方式总结
流量控制方式总结
3.4 无死锁流量控制
日期变更线(Dateline)和VC分区(VC Partitioning)
每个VC都和单独的缓冲队列绑定,在物理链路上逐周期地进行时间多路复用。在途中,所有消息都通过VC 0发送,直到跨过日期变更线,消息被分配到VC 1,且不能重新被分配到VC 0,这就确保了信道依赖图(channel dependency graph, CDG)是无环的。 
逃逸虚拟通道(Escape VCs)
VC0锁住了,利用VC1逃逸。只要有一个无死锁的逃逸VC,所有其他VC就可以使用没有路由限制的完全自适应路由,而不是在所有虚拟通道之间强制要求一个固定的顺序或优先级 
气泡流量控制(Bubble Flow Control)
通过插入虚假的bubble来控制数据的进入或阻塞,下图中只有R1允许P1数据包进入 
4 Flow Control
- Credit-based flow control,Downstream passes back credits to upstream,buffer的深度需要考虑credit往返的延迟
- Ack/NAck flow control,Buffer cannot be deallocated until ACK/NACK received
4.1 缓冲区反压(Buffer Backpressure)
两个路由器之间的连接在等待下游路由器空出缓冲区时,会空闲6个周期。一旦确定 Flit 将离开路由器并且不再需要其缓冲区,就可以通过触发背压信号(credits 或 on/off )来优化缓冲区周转时间,而不是等到 Flit 实际从缓冲区中读出。
这意味着这个使用 on/off 背压的网络每个端口至少需要 8 个缓冲区来覆盖周转时间,而如果它选择基于信用的背压,则每个端口需要的缓冲区少 2 个。因此,缓冲区周转时间也会影响面积开销,因为缓冲区占用了路由器占用空间的很大一部分。


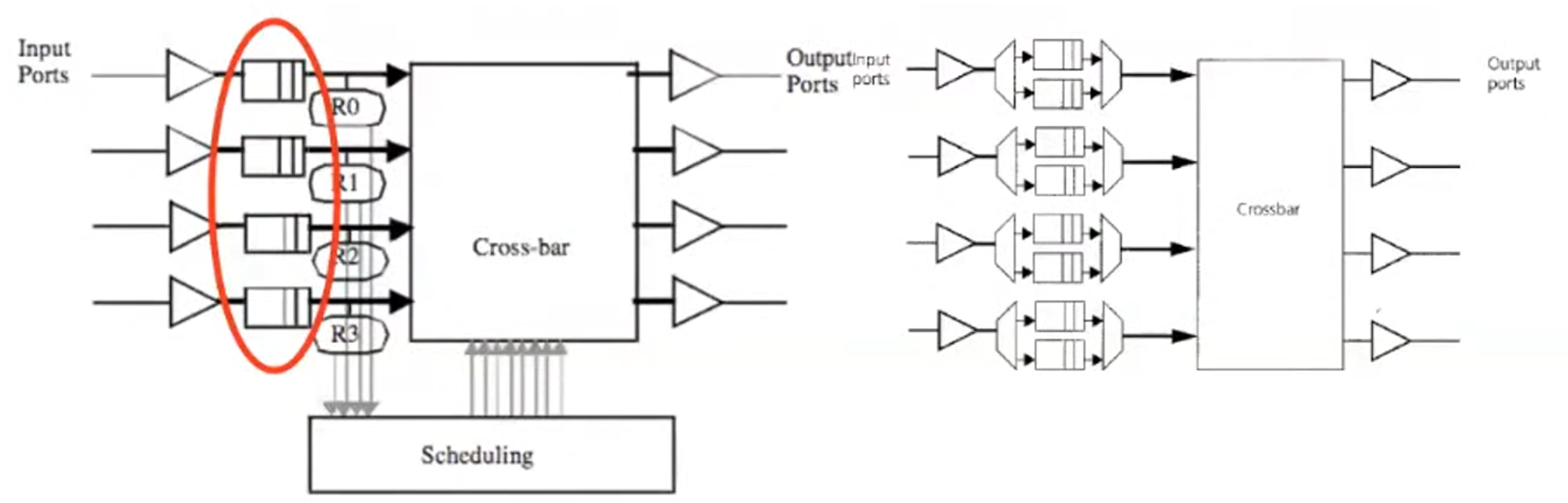
5.Router微架构
Routing机制:算术(x_y)、Source Based(source决定output port)、LookupTable(我认为是最好的)
下图中,假设有一个2Dmesh的结构,存在一个本地+4个方向的端口,每个输入端口有4个VC,每个VC有4flits的缓冲队列 
构成路由器的主要部件是输入缓冲、路由计算逻辑、虚拟通道分配器、开关分配器和crossbar开关。如果不使用源节点路由,1️⃣路由计算器将计算(或查找)当前数据包的输出端口,2️⃣分配器决定哪些flits被选择进入下一个阶段,并穿越crossbar,3️⃣最后crossbar负责将flits从输入端口物理地移动到输出端口。
5.1 缓冲区和VC
1. Single fixed-length queue 这个很简单明了,没有VC,输入添加到队列的尾端,头部发送到crossbar switch,获得仲裁后进一步到达输出
缺陷:队列头部的数据包可能被阻塞(因为其输出端口由另一个数据包持有),队列中存在a->b以及a->c,此时c空闲但是b还在处理,这个时候必须等待a->b被发送。这种阻塞叫做:head-of-line blocking.
 缓冲区和VC组织结构
缓冲区和VC组织结构
- Multiple fixed-length queues
在每个输入端口拥有多个队列有助于减少队头阻塞。这些队列中的每一个都称为一个虚拟通道,多个虚拟通道多路复用并共享物理通道/链路带宽。上图对应于具有 2 个 VC 的路由器。
- Multiple variable-length queues
上述的VC受调度影响,可能VC0一直full但另一个VC经常空闲。为此,出现了每个 VC 队列可以是可变长度的,共享一个大缓冲区 ,这允许更好的缓冲区利用率,但代价是更复杂的电路来跟踪队列的头部和尾部。此外,为避免死锁,需要为每个 VC 保留一个 flit 缓冲区,以便其他 VC 不会填满整个共享缓冲区并耗尽 VC,从而确保前进进度。buffers数量参考这里
Beyond that, for sustaining full throughput, there needs to be a minimum number of buffers (within each VC or in total, depending on the buffer organization) to cover the buffer turnaround time
输入VC状态
每个VC都和其中flit的以下状态有关:
- 全局状态(Global, G)
- Idle(空闲):VC 当前未被使用。
- Routing(路由中):头 flit 正在进行路由计算,以确定下一跳的输出端口。
- Waiting for output VC(等待输出 VC):头 flit 等待在下一个路由器中分配一个输出 VC。
- Waiting for credits in output VC(等待输出 VC 的信用):VC 等待输出 VC 中有可用的信用(即缓冲区空间)
- Active(活动):VC 正在传输 flit,可以参与交换分配。 Active 状态的VC可以请求交换机的访问权限,以传输其 flit。
- 路由信息(Route, R)
头 flit 在路由计算阶段确定输出端口,并将此信息存储在 R 字段中。这里的路由终点分配有多种设计考虑:1️⃣使用预见路由(lookahead routing)或源路由(source routing)的设计中,头 flit 在到达当前路由器时已经携带了目标输出端口信息。2️⃣路由计算器将计算(或查找)当前数据包的输出端口
- 输出 VC(Output VC, O)
在 VC 分配后由头 flit 填充,供该数据包的所有后续 flit 使用,确保整个数据包通过相同的路径和 VC 传输。
- 信用计数(Credit Count, C)
数据包的主体 flit(body flit)和尾部 flit(tail flit)会检查信用计数,决定是否可以发送。
- 指针(Pointers, P) 指向头 flit 和尾 flit 的指针,如果缓冲区实现为多个可变长度队列的共享池,则这是必需的。
| 状态信息总结 | 用途 |
|---|---|
| 全局状态(G) | 反映了 VC 的当前状态,决定了 VC 是否可以参与交换分配和数据传输 |
| 路由信息(R) | 指示数据包应被发送到哪个输出端口,是交换分配的关键依据 |
| 输出 VC(O) | 确定了数据包在下游路由器中使用的 VC,确保了数据包的有序传输 |
| 信用计数(C) | 用于流量控制,防止缓冲区溢出,保障网络的稳定运行 |
| 指针(P) | 在共享缓冲区的情况下,管理数据包在缓冲区中的位置,维护数据完整性 |
上述内容原文
6.2.2 INPUT VC STATEEach Virtual Channel is associated with the following state for flits sitting in it.
1️⃣Global (G): Idle/Routing/waiting for output VC/waiting for credits in output VC/Active. Active VCs can perform switch allocation.
2️⃣Route (R): Output port for the packet. This field is used for switch allocation. The output port is populated after route computation by the head flit. In designs with lookahead routing (described later in Section 6.5.2) or source routing, the head flit arrives at the current router with the output port already designated.
3️⃣Output VC (O): Output VC (i.e., VC at downstream router) for this packet. This is populated after VC allocation by the head flit, and used by all subsequent flits in the packet.
4️⃣Credit Count (C ): Number of credits (i.e., flit buffers at downstream router) in output VC O at output port R. This field is used by body and tail flits.
5️⃣Pointers (P ): Pointers to head and tail flits. This is required if buffers are implemented as a shared pool of multiple variable-length queues, as described above.
5.2 开关设计
路由器的crossbar开关是路由器数据通路的核心部分,将数据从输入端口移动到输出端口。大多数低频路由器使用下面这种很简单粗暴的crossbar  当频率要求更高时,下面展示了5x5的crossbar
当频率要求更高时,下面展示了5x5的crossbar 
这里我不是很明白,可能得看看相关代码
5.3 分配器与仲裁器
VC分配器(VA):将VC分配给数据包或flit,即找到输出端口的VC(即下一个路由器输入端口的VC) Switch Allocator(交换机分配器):将crossbar端口分配给VC
在大多数NoC中,路由器的分配逻辑决定了周期时间,因此分配器和仲裁器必须是快速的,并且是流水线的,以便在高时钟频率下工作。
仲裁器
- RRArb:If Granti is high, PriorityiC1 becomes high in the next cycle and all other priorities become low.理解成一个指针每次仲裁完了+1

- 矩阵仲裁

分离式分配器
为了降低分配器的复杂度,并使其流水化,分配器可以被构建为多个仲裁器的组合。
 三个请求者,四个资源的分配器设计
三个请求者,四个资源的分配器设计还有更多分配器请查看原文
5.4 VC路由器的逻辑流水线
1️⃣(BW)head flit到达一个输入端口时,首先根据其输入的VC在BW级进行解码并放入缓冲区
2️⃣(RC)RC级路由逻辑进行计算以确定包的输出端口
3️⃣(VA)head flit在VA级进行仲裁,找到输出端口的VC(即下一个路由器输入端口的VC)
4️⃣(SA)进入SA级,对switch的输入和输出端口进行仲裁
5️⃣(ST)遍历crossbar
6️⃣(LT),该flit被传送到下一个节点
body和tail flit遵循类似的流水线,但不会经过RC和VA级。而是直接继承header flit分配的路由和VC,tail flit在离开路由器时,会移除head flit保留的VC
下图中介绍了几种优化措施,具体见原文page91 
6. 一些思考
不用buffer可以避免死锁,但是会引来活锁,活锁一般会记录数据包的顺序,router永远优先处理最早的数据包
Handling Contention: 1) Buffer 2) Drop 3) route to somewhere else